Table of Contents
UDMF: USER PROFILING THROUGH DEEP MULTIMODAL FUSION
- 为了将多种数据源的数据集成到一个模型中, 作者搞了两个技巧: stacking 和 power-set combination
-
一个正常的多层感知器, 应用到数据源D上时, 第h层的第i个神经源的响应是
$$
U^h_i(D) = f\left( \sum_j w_{ij}^{hl} U_j^l(D) \right)
$$ -
而第0层的输入则为
$$
U^0_i(D) = f\left( \sum_j w_{ij} D_j \right)
$$ - 利用stacking的方法,将其他画像任务的输出作为当前画像任务的输入(见图2),并且可以实现在其他输入相同的情况下,多次不断的迭代。第q次迭代中, 第0层的输入可以记作
$$
U^{0q} _ i(D) = f\left( \sum_j w_{ij} D_j + \sum_z w_{iz} \alpha_z t_z^{q-1} \right)
$$ - t代表第z个画像的输出,q代表轮数,第q次的输入特征是上一轮其他画像的值。$(\alpha_z)$ 是一个示性函数,将当前画像上一轮的值排除掉,当z是当前画像时,取值为0,其他画像则为1.
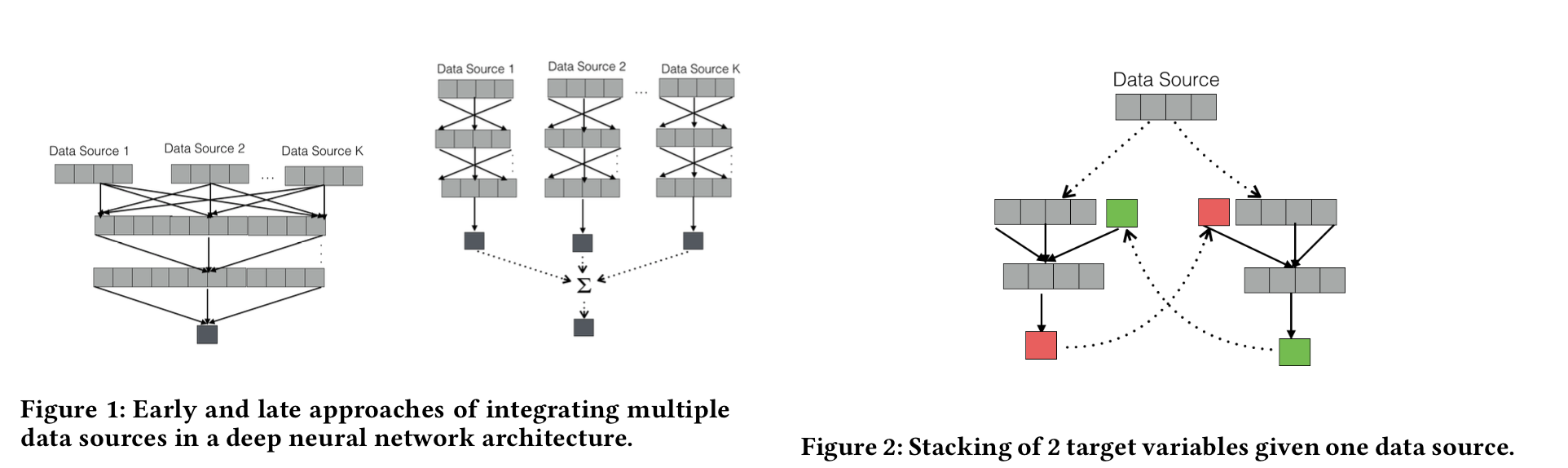
- 多个数据源首先作为特征融合,然后将多个画像用stacking方式融合
-
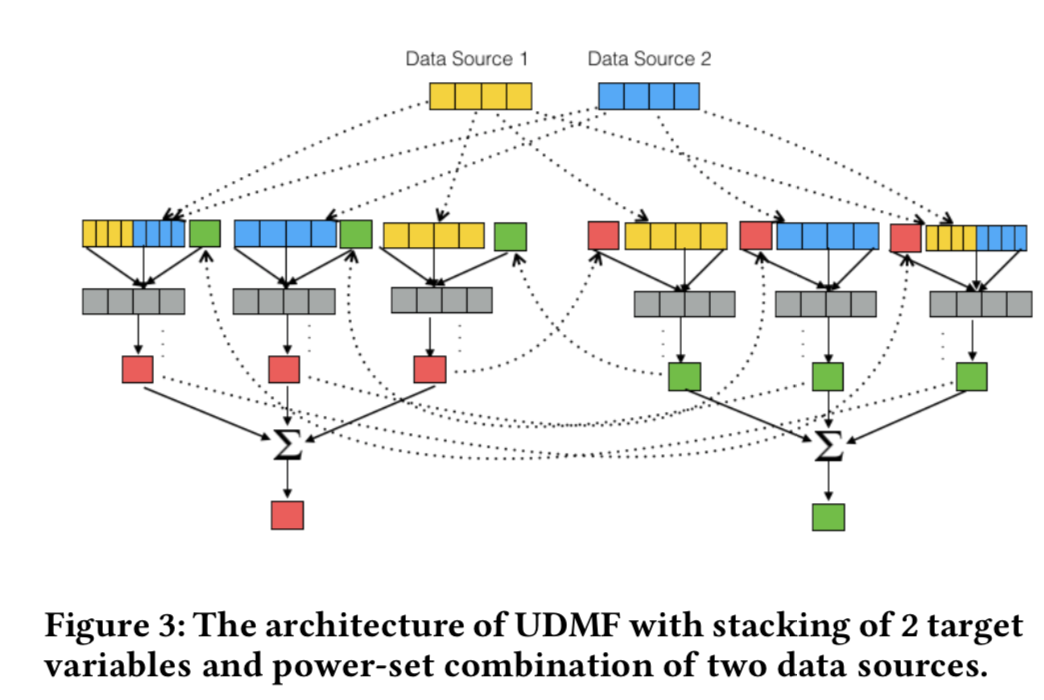
幂集融合,k个数据源$(DS = \{ D_1, D_2, ..., D_k \} )$,非空子集数目为$(2^k - 1)$,对每个非空子集,构建一个mini-DNN, 他的每个神经元会将其他子集对应的mini-DNN中相同的神经元的结果求和,说得很啰嗦,看公式($(\mathcal{D})$表示非空子集的集合)
$$
U^{0q} _ i(\mathcal{D}) = f\left( \sum_{D \in \mathcal{D}} \sum_j w_{ij} D_j + \sum_z w_{iz} \alpha_z t_z^{q-1} \right)
$$ -
以2个数据源2个画像为例,每个画像会有3个子DNN网络,所以一共有6个DNN网络
- 在决策层,每个画像都将子DNN网络的输出结果进行融合,比如简单投票
数据源embedding
- 文本:
- 88 Linguistic Inquiry and Word Count (LIWC) features (最佳)
- Glove
- fastText
- 图像:
- Oxford Face API
- CNN输出的向量,作者用的是在ImageNet上预训练的VGG输出的向量,效果不如特征描述子和API特征有效
- 关系数据:
- Node2Vec 向量 (最佳)
- page like 向量,类似于矩阵分解