TensorFlow 白皮书
第一代分布式机器学习框架: DistBelief。
第二代:TensorFlow,通用的计算框架!
基本概念
- TensorFlow 的计算被表达为一个有向图(graph)——计算图,它由很多节点(Node)构成
- 每一个节点有0个或者多个输入,0个或者多个输出,表达了一个计算操作实例
- 正常边上流动的值被称作张量(tensor)
- 特殊边:control dependencies:没有数据流过这些边,用来控制依赖关系的
- 操作(Operation):对计算的抽象,例如矩阵乘法,加法等。操作可以有属性,所有的属性必须被指定,或者在图构建的时候能够推断出来
- 内核(Kernel):操作的一种特殊实现,能够在特定的设备(如CPU,GPU)上运行
- 会话(Session):client程序与 TensorFlow 系统交互的方式, 一般创建一次,然后调用
run方法执行计算图的计算操作 - 变量(Variable):大多数 tensor 在一次计算后就不存在了,变量在整个计算图计算过程中,可以一直保持在内存。Variable 操作返回一个句柄,指向该类型的可变张量。对这些数据的操作可以通过返回的句柄进行,例如 assign, assignadd操作。一般用来保存模型参数!
- 实现:单机,分布式。client 通过 session 提交计算任务,master通过 worker 执行计算操作
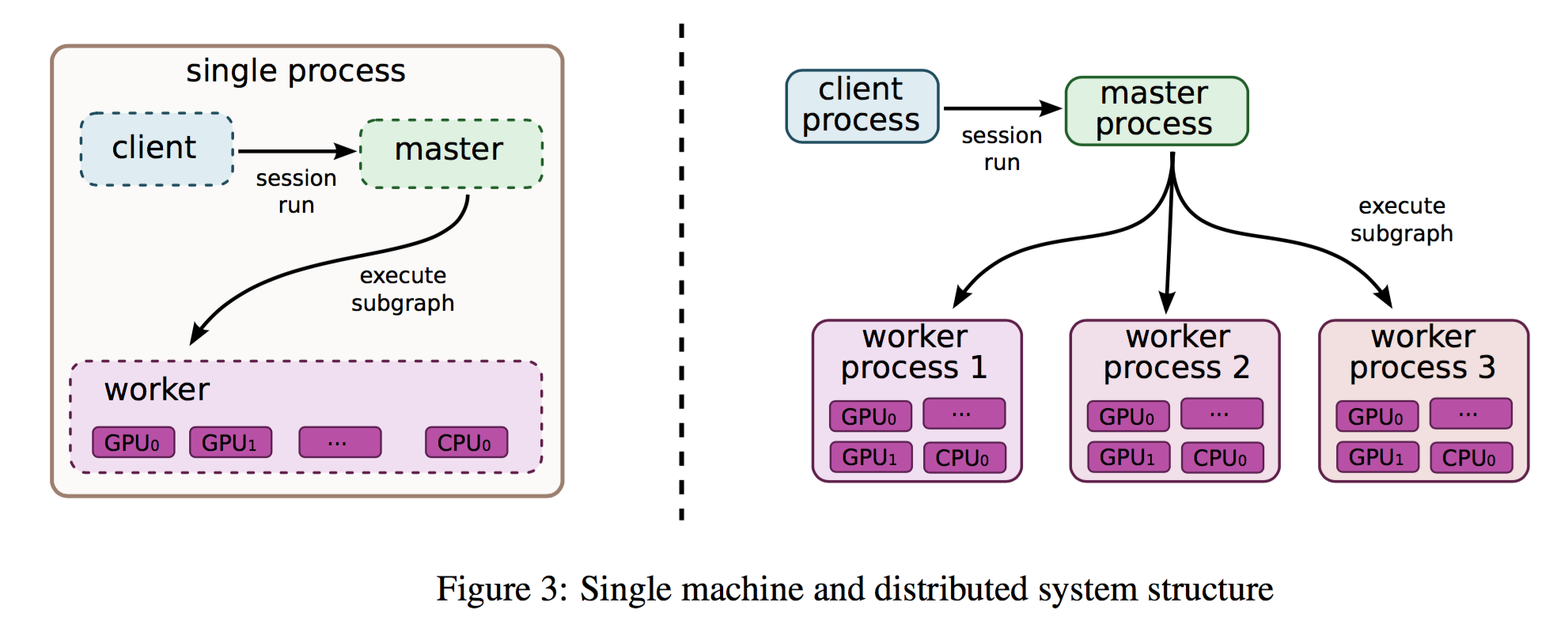
-
设备:device,如CPU或者GPU;每一个 worker 关联一个或多个设备。每个设备都一个一个类型,和一个名字,如
/job:localhost/device:cpu:0
或者/job:worker/task:17/device:gpu:3。其他设备类型可以通过注册的机制加入! -
单机执行
- 多机执行:多机通信方式:TCP or RDMA
- 容错:一旦检测到错误,就重新开始;变量(Variable)会定期的保存 chekpoint。
- 梯度计算:会创建一个子图,计算梯度
- 控制流:支持 条件跳转,switch,以及循环
- 输入节点:client通过feed灌入数据,或者直接定义输入节点直接访问文件(效率更好)
- 队列:让子图异步执行的特性!FIFO队列,shuffle 队列
- 容器(container):用于存长期可变状态,例如变量
优化
- Common Subexpression Elimination,公共子表达式消除
- 通过控制流,延迟recevier节点的通信,减少不必要的通信资源消耗
- 异步 kernel
- 采用深度优化的库:BLAS,cuBLAS,convolutional,Eigen(已扩展到支持任意维度的张量)
- 有损压缩,通信的时候采用有损压缩传递数据
- 数据并行,模型并行!
工具
- TensorBoard:训练过程可视化,计算图结构的可视化
核心图数据结构
class tf.Graph
基本数据类型
- constant
a = tf.constant(5.0) b = tf.constant(6.0) c = a * b with tf.Session() as sess: print sess.run(c) print c.eval() # just syntactic sugar for sess.run(c) in the currently active session!
- Session
tf.InteractiveSession()- default session
- Variables,用来表示模型参数。
“When you train a model you use variables to hold and
update parameters. Variables are in-memory buffers
containing tensors” - TensorFlow Docs.
W1 = tf.ones((2,2)) W2 = tf.Variable(tf.zeros((2,2)), name="weights") R = tf.Variable(tf.random_normal((2,2)), name="random_weights")
使用函数tf.initialize_all_variables()参数初始化,初始值在定义的时候给出。
如果要对变量作用域里面的所有变量用同一个初始化方法,可以在定义作用域的时候指定。
参考https://www.tensorflow.org/versions/r0.7/how_tos/variable_scope/index.html#initializers-in-variable-scope
with tf.variable_scope("foo", initializer=tf.constant_initializer(0.4)): v = tf.get_variable("v", [1]) assert v.eval() == 0.4 # Default initializer as set above.
变量的更新,使用方法tf.add, tf.assign等方法
state = tf.Variable(0, name="counter") new_value = tf.add(state, tf.constant(1)) update = tf.assign(state, new_value) with tf.Session() as sess: sess.run(tf.initialize_all_variables()) print sess.run(state) for _ in range(3): sess.run(update) print sess.run(state) 0 1 2 3
利用tf.convert_to_tensor方法可以将数值变量转换为张量。
- placeholder用来输入数据,通过
feed_dict字典将输入数据映射到placeholder.
input1 = tf.placeholder(tf.float32) input2 = tf.placeholder(tf.float32) output = tf.mul(input1, input2) with tf.Session() as sess: print sess.run([output], feed_dict={input1:[7.], input2:[2.]}) tf.placeholder(dtype, shape=None, name=None)
注意,这里有个大坑,这个字典的键是一个op,而不是一个字符串!!
-
变量作用域,
variable_scope,get_variable_scope,get_variable.
scope.reuse_variables()可以使得该作用域的变量重复使用,在RNN实现中很有用。
声明重复利用的时候,get_variable的时候不是创建一个变量,而是查询保存的那个变量。 -
word embedding
优化
当得到损失函数之后,可以通过tf.train.Optimizer优化工具来进行优化,实际优化的时候使用的是他的子类,
如GradientDescentOptimizer, AdagradOptimizer, or MomentumOptimizer。
优化obj通常有以下几个重要方法可以使用。
train_op = minimize(loss),直接最小化损失函数compute_gradients(loss),计算梯度train_op = apply_gradients(grad),应用梯度更新权值
tf.distrib.learn 框架
一个高级机器学习框架
- 模型基本接口,与sklearn很像
- init() 初始化
fit拟合evaluate评估predict预测
CPU vs GPU
- Q: 自己代码在实现上有什么区别呢?
TIPS
tf.reshape(some_tensor, (-1, 10))将数据重新划分为10列的元素,第一维自适应tf.device指定CPU或者GPUtf.add_to_collection(name, value)将value保存为名字为name的共享集合中,供后面使用.
tf.get_collection(name),获取存储的值- tensorflow里面的标量和
shape=[1]是不同的,请注意。
[1] https://www.tensorflow.org/
[2] http://cs224d.stanford.edu/lectures/CS224d-Lecture7.pdf