Table of Contents
基于HMM的语音识别技术
主要参考文献[1]
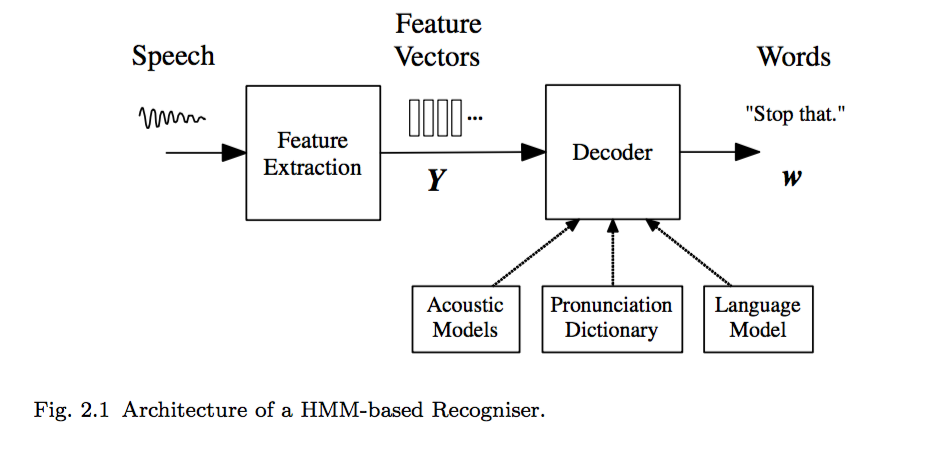
首先,语音信号被分帧(一般10ms)提取特征,比如 MFCC 特征,得到一系列的特征向量序列 $(Y_{1:T} = y_1,...,y_T)$,这里$(y_i)$都代表一帧的语音特征。语音识别器寻找一个最佳词序列 $(w_{1:L} = w_1,...,w_L)$进行解码,即最大化后验概率 $(P(w|Y))$。
后验概率建模通常比较困难(现在可以直接用深度学习建模啦),所以 HMM 的语音识别通过条件概率建模,
参考
- The Application of Hidden Markov Models in Speech Recognition, Mark Gales, Steve Young, Cambridge University, 2008