Table of Contents
基本思想
- 利用超长用户历史行为来建模更全的用户兴趣,但这势必带来性能问题,本文通过工程优化来实现上线
- 关键词:大力出奇迹,效果的提升还得靠更多数据,更多数据需要更高效的系统设计来支持上线
模型结构
- 将用户历史行为长度从100->1000,AUC +0.6%
- 一些数据
- 存储:6亿用户,150->1TB,1000->6TB
- 时延:DIEN,150->15ms,500qps;1000->200ms,500QPS.系统限制是在500QPS,30ms
- UIC,500QPS,19ms
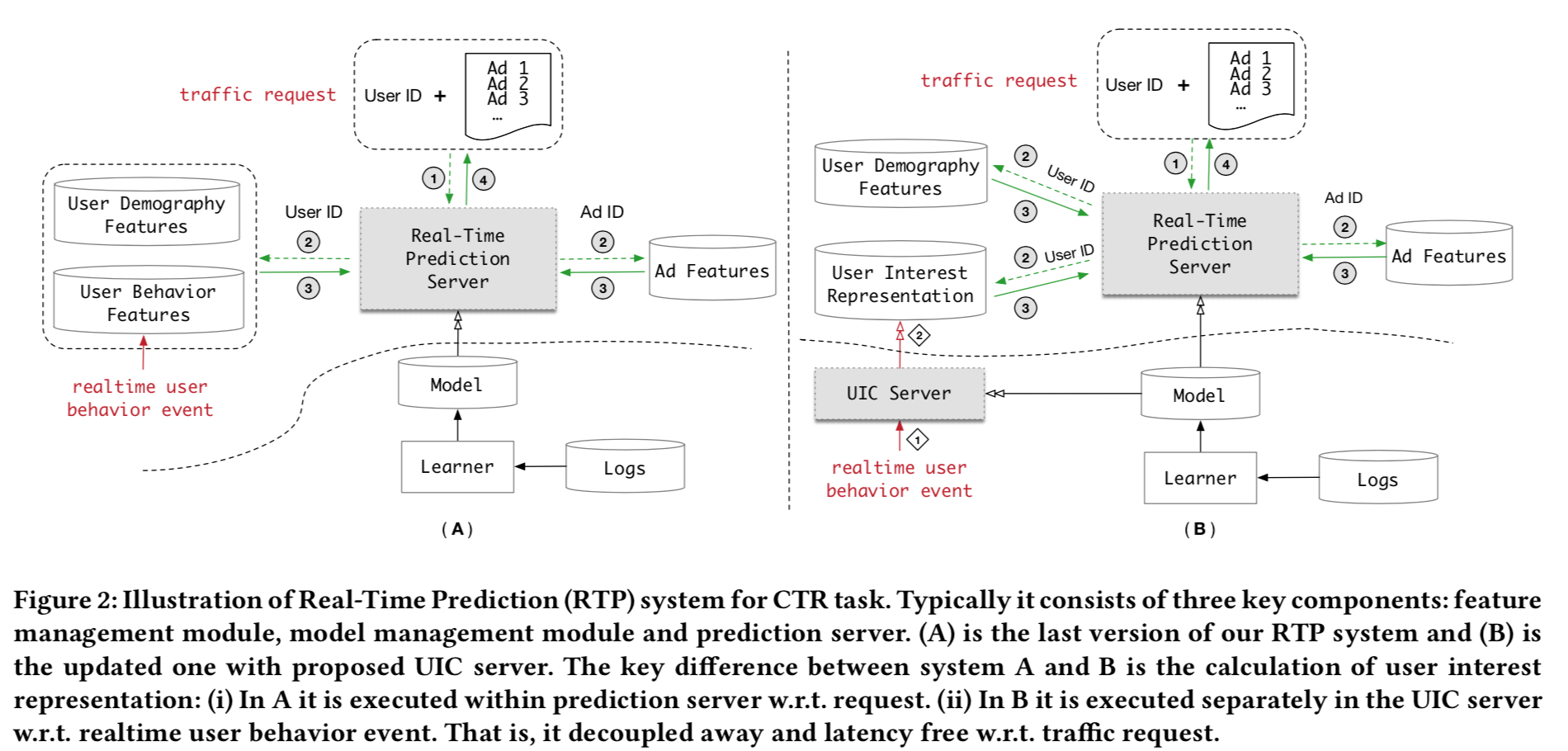
- 系统改造核心点
- 将用户兴趣计算从CTR模型中抽出来独立
- 原来兴趣向量是在request来了的时候实时计算,现在是在用户行为事件的时候更新
- 将兴趣更新跟请求时取兴趣向量分离,这样避免了请求计算的大时延,并且原则上请求时延已跟行为长度无关了!几乎是个固定值
- UIC设计借鉴了神经图灵机NTM的设计,设计了读操作和写操作
- 存的是一个固定长度的向量,但是这些向量是跟用户所有的历史行为有关
- 向量在用户行为到来是更新,通过NTM的读写操作来更新
- 应用场景,用户行为更新速度要少于点击率请求速度
- MIMN相比DIEN的AUC提升解决1个百分点!
- 线上效果,MIMN比DIEN,CTR+7.5%,RPM+6%
- 移除双十一的数据有效果上的提升,毕竟分布差异太大
- 每天0点重置一下,用近7天的数据,how?
FAQ
如果用户行为事件也很多怎么办?
相比将长短期分开策略比怎么样
- 长短期兴趣分开
- 短期session取固定长度大小
- 长期行为截取固定长度大小?