背景
跟踪推荐学术界、工业界相关新技术调研,把握技术动向。
方法
- 学术界的信息来源主要是公开的论文以及关键论文的被引,微博大脑推荐
- 工业界的信息来源主要是一些公众号和论文
排序模型
- xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems
序列模型
- attention流派:
- 阿里 DIN: 将用户的某种集合(一般是session集合,点击过的item)用attention加权做Pooling
- STAMP: Short-Term Attention/Memory Priority Model for Session-based Recommendation, KDD2018 将session的item加权Pooling,结果与最后一个item以及候选item做了个三向量内积
引入强化学习
- Supervised Reinforcement Learning with Recurrent Neural Network for Dynamic Treatment Recommendation
引入知识图谱
- Leveraging Meta-path based Context for Top-N Recommendation with A Neural Co-Attention Model, KDD2018
- 关键IDEA: 除了用user和item向量之外,引入meta-path上下文。 meta-path上下文构造方法: 首先构造一个图谱,以电影推荐为例,节点有用户(U),电影(M),导演(D);节点间的关系有用户间的朋友关系,用户与电影之间看过关系,电影与导演间的导演关系。这些节点和关系构成一张异构图,利用random walk按照某种特定的顺序采样(UMUDM),这个顺序即 meta-path,采样得到的节点序列就是一个上下文,这种方法在其他文献中也有用到。从一个user出发到某个item结束可以有很多种序列,根据不同的meta-path也能采样出不同的序列,这些节点序列通过embedding,CNN(或RNN或self-attention),Pooling(max-pooling或attention Pooling)可以得到一个上下文向量,这样就将这个信息引入和推荐系统。
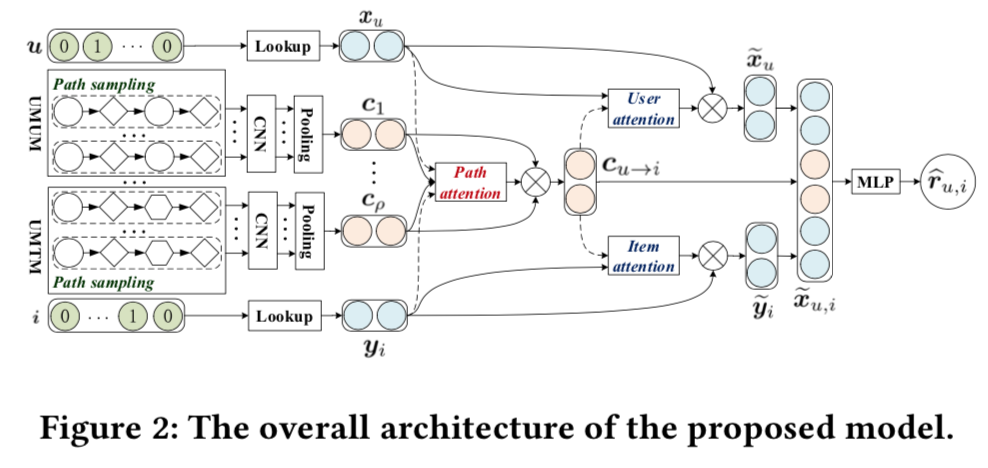
- Explainable Reasoning over Knowledge Graphs for Recommendation, AAAI2019
- 关键IDEA:也是采样多个从user到item的路径,然后将节点和关系都做embedding,构造向量序列用LSTM做Encoder,多个路径的预测概率最后做一个Pooling
- RippleNet: Propagating User Preferences on the Knowledge Graph for Recommender Systems
- 关键IDEA:
- item向量还是直接embedding
- user向量构造是从用户session开始,从session的item开始在知识图谱中向邻居扩散,每一次扩散都有一个输出向量,最终的用户向量是这些输出向量之和
- 每一次传播的输出向量是所有节点向量的加权和, 权重取决于来源节点、关系、target item的关系得分
- 关键IDEA:
- 知识图谱的处理, 图卷积GNN
模型压缩
- Ranking Distillation: Learning Compact Ranking Models With High Performance for Recommender System
- 基本IDEA: 用一个小模型来学习大模型的输出, 最小化二者的KL距离
评论数据的利用
-
个人观点: 评论数据对推荐是有一定作用,但是评论数据的信噪比很低,在CTR模型中, 在已有的数据基础上直接增加评论数据可能不见得有提升,但是评论中可以抽取出item的一些显示feature(比如电影中的某个演员演技很赞, 特效很好, 值回票价 etc),如果这些feature能在展示环节漏出,应该能够有效地提升点击率
-
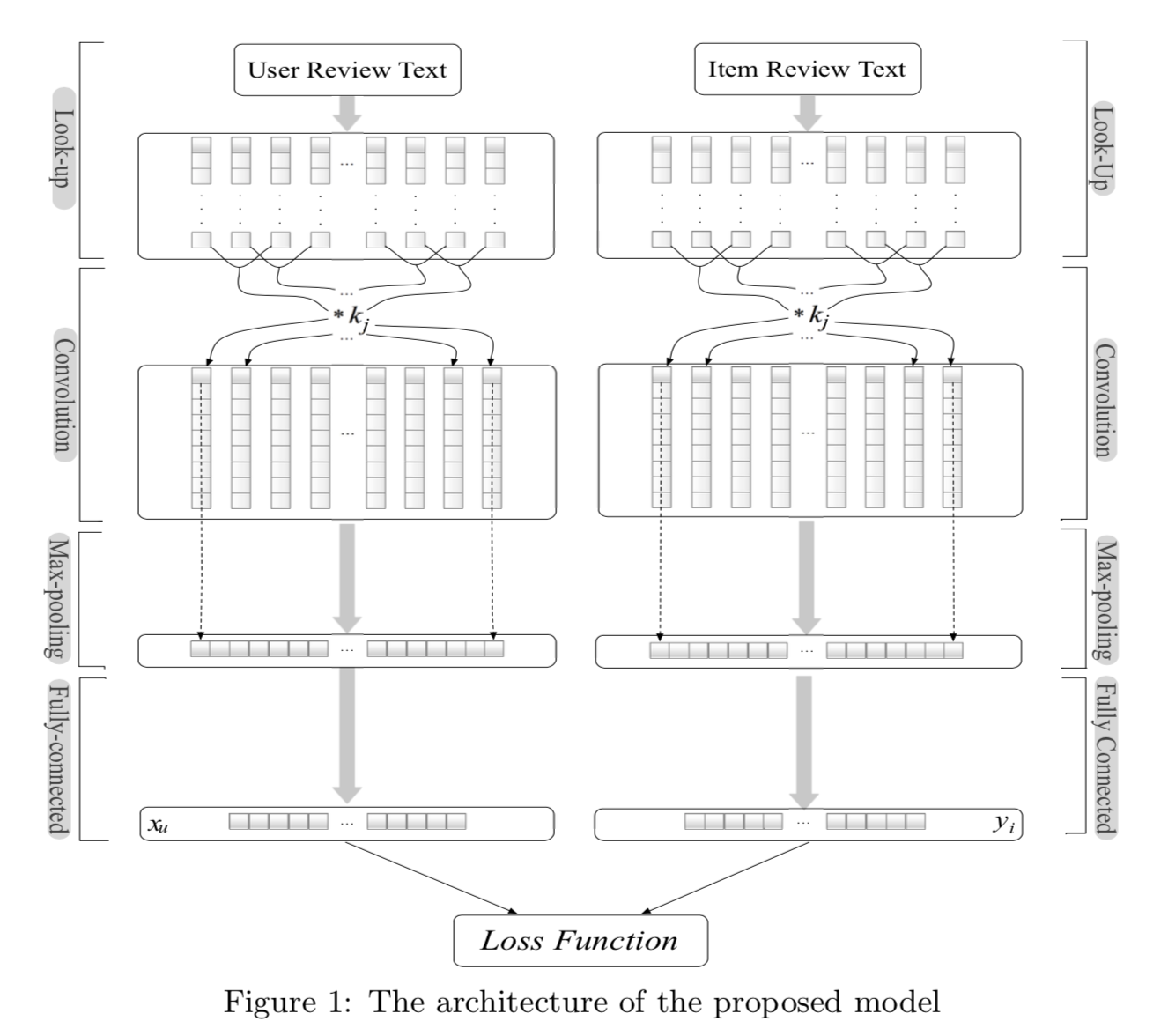
DeepCoNN: 用户由用户写的评论表示, item由item的所有评论表示,把这两部分文档分别用CNN做encode,然后用FM做匹配(最后一层是用户向量和item向量用FM算出来的loss)。
- ref: Joint Deep Modeling of Users and Items Using Reviews for Recommendation, 2017
-
TransNets: 在DeepCoNN基础上增加了 multi-task learning 模块
- ref: TransNets: Learning to Transform for Recommendation
-
Dual Attention CNN model (D-ATT):
- ref: 对每个词学一个attention权重,从而将重要的词提权,不中要的词降权,从而提高信噪比。 attention 就是一种利用数据自己学习提高信噪比的方法!!
- 全局attention: 对所有的词向量做加权
- local attention: 搞一个滑动窗,只在这个窗内做加权
- Multi-Pointer Co-Attention Networks for Recommendation, KDD2028
- 利用attention学到硬attention向量(即只有一个维1其他为0,所以也叫pointer),然后做Pooling

GAN 的应用
- Neural Memory Streaming Recommender Networks with Adversarial Training, KDD2018, 360
- 关键点:
- 利用一个有外部存储的neural memory networks, 同时建模用户的长期兴趣和短期兴趣
- 利用一个基于GAN的负采样方案, 来优化流式推荐模型。传统负样本采样(随机采或者基于popularity的采样)采出来的
- 关键点:
- 流式训练的关键点:
- SGD优化