Table of Contents
AutoInt
- 论文:AutoInt: Automatic Feature Interaction Learning via Self-Attentive Neural Networks,CIKM 2019
- 基本思想:用self-attention来学习特征交叉
- 代码:https://github.com/DeepGraphLearning/RecommenderSystems
主要内容
模型
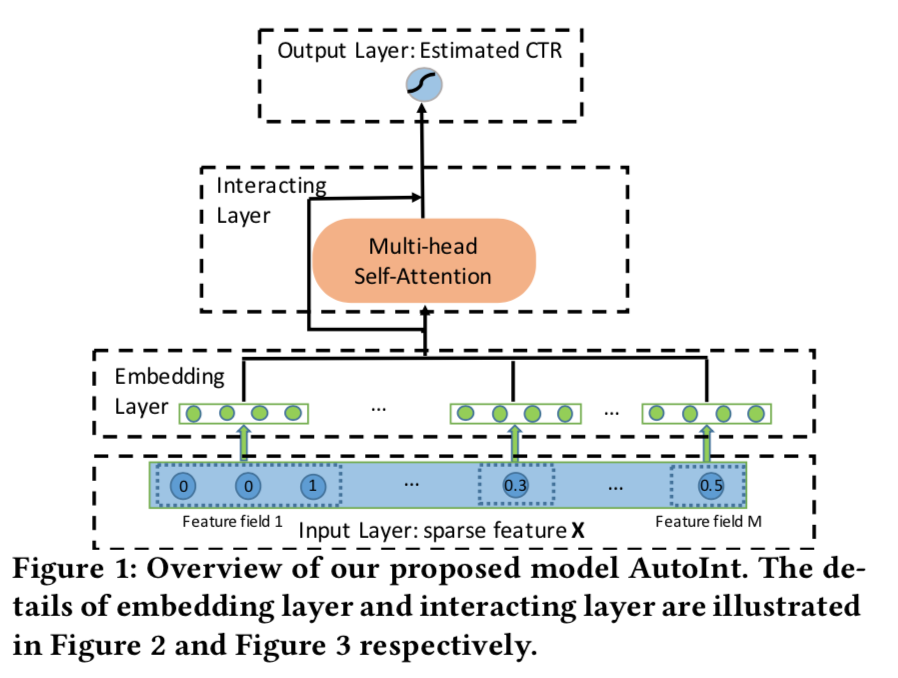
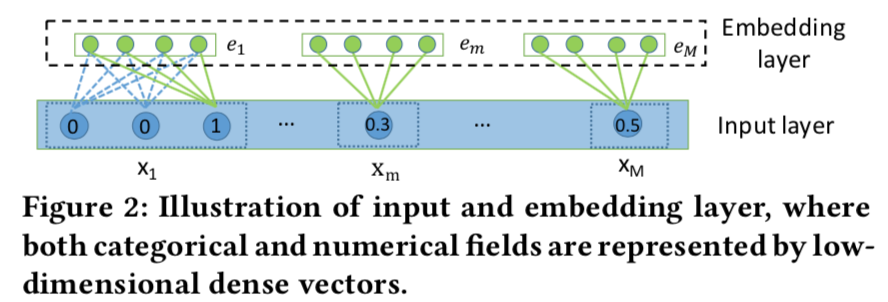
- 将所有的特征当做稀疏特征,投影到同一个emb低维空间,得到向量序列e1,...,eM
- 对单值特征,直接emb
- 单值连续值特征,emb后乘以连续值
- 对多值特征,emb后取平均
- 交互层,将上述每个emb依次看做query,利用self-attention实现特征间的交互,
利用多头Attention每个向量都可得到H个变换后的向量,拼接得到交叉特征$(\tilde{e_m} = \tilde{e_m}^1 \oplus ... \oplus \tilde{e_m}^H)$
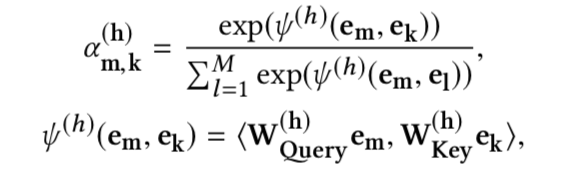
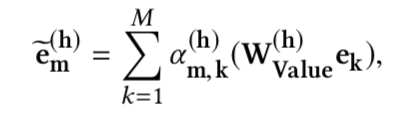
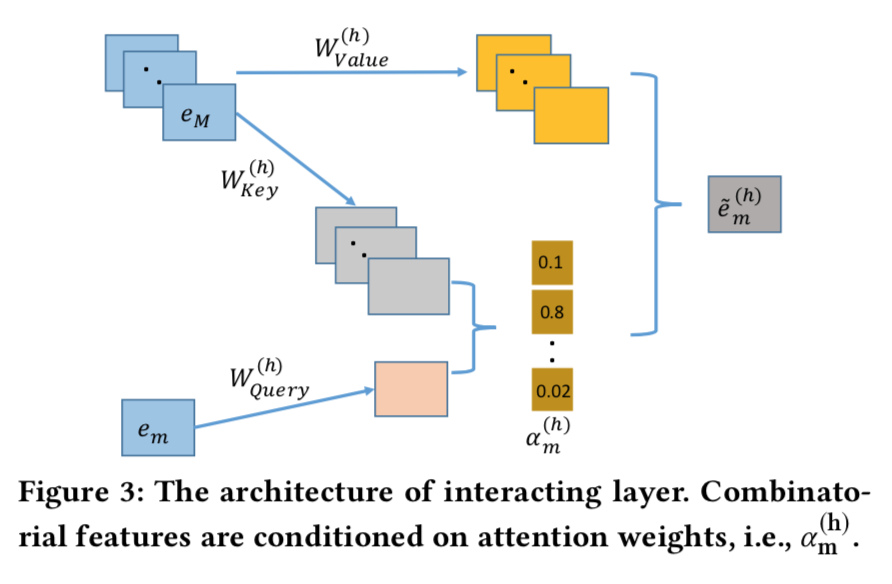
-
将多头变化后的向量$(\tilde{e_m})$跟原始向量$(e_m)$用残差方式融合得到最终向量。
$$
e_m^{Res} = ReLU(\tilde{e_m} + W_{Res} e_m)
$$ -
进过上述交叉层后,每个$(e_m)$都得到一个融合特征交叉后的$(e_m^{Res})$。
concat后进入逻辑回归层,预测概率即可。
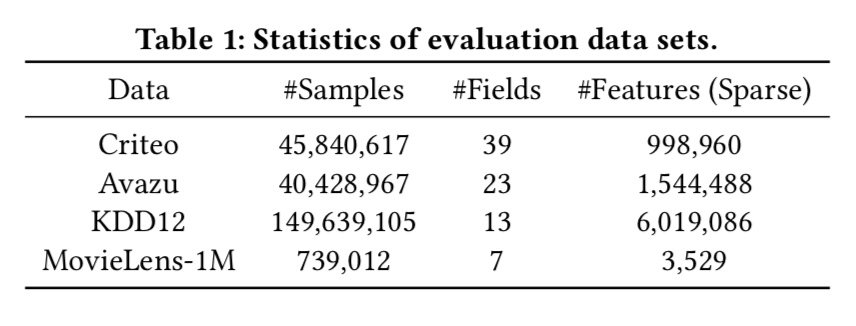
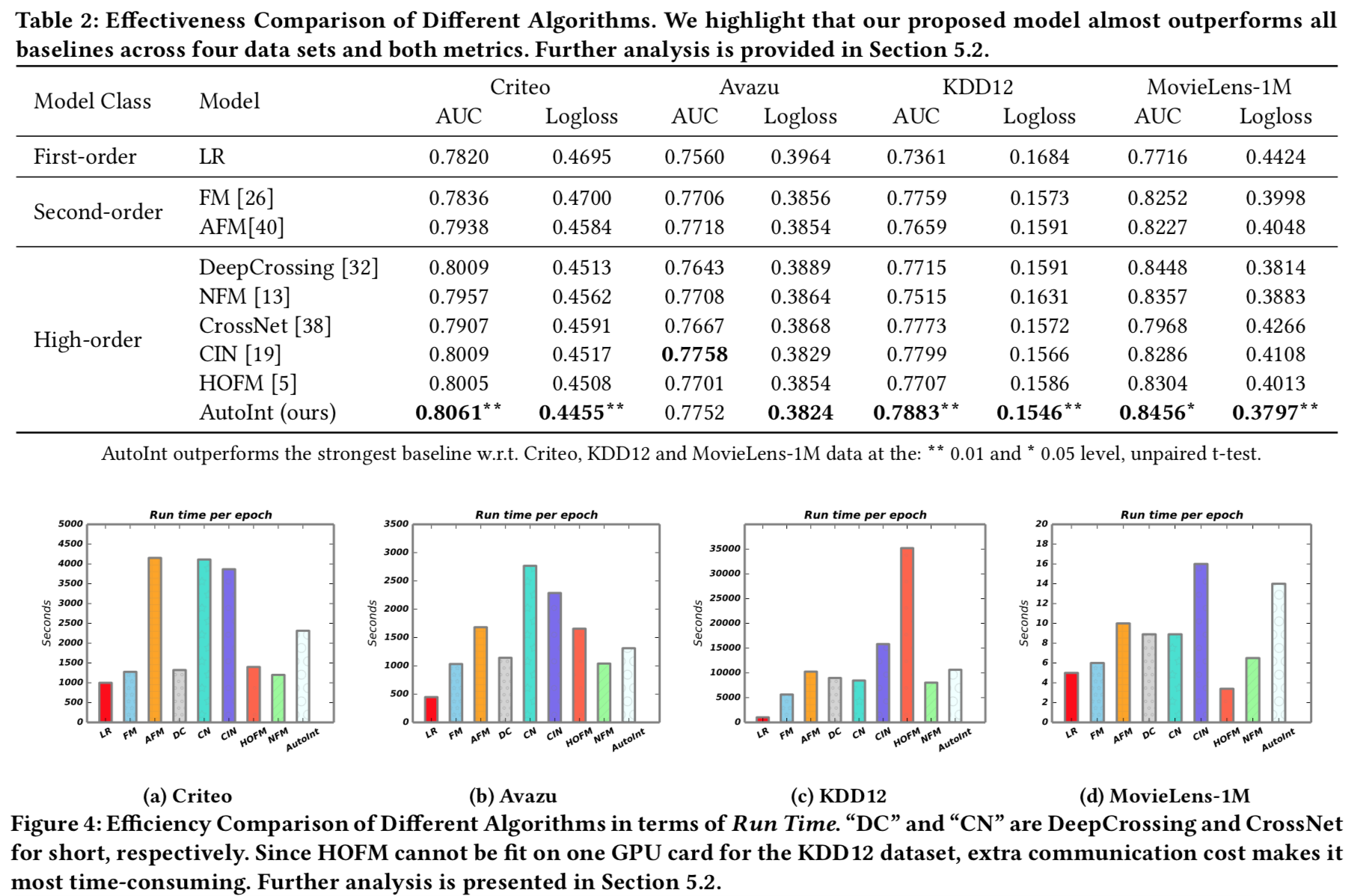
试验
- 实验结果显示,相比于其他实现交叉的方法,在离线指标上有显著提升。
- 残差对结果提升较大,self-attention层数不用太多2-4层即可。
- 交互层对模型训练性能影响还比较大。
评论
- 利用self-attention来做特征间的交叉是个不错的想法,但是self-attention的
物理意义应该是用其他特征向量来平滑中间特征向量,直观上来看有点说不太通。至少
在这个点上,可以做一些改进,比如$(\tilde{e_m}^h)$不是用所有特征向量的线性组合,
而是用特征间内积的线性组合,可能更能表示特征间的交叉。 - 另外,由于不同的特征的emb尺寸是一样的,可能会影响高基数特征的表达能力,因为
这个尺寸大家必须相同,所以不会特别大,而很多id特征的基数很高,如果比较重要的话,
提高这部分特征的emb尺寸是有一定价值的。但是在autoint中,强行让所有的emb尺寸都相同,
从理论上来分析,可能会有一定的负面效果。当然,最终以试验结果为准,炼丹大分部都是玄学。 - 实际上,可以对self-attention稍加改造就可以不需要让每个特征的emb尺寸保持一致。
在计算内积的时候增加一个投影即可,所以维度不匹配的地方都可以通过一个投影来实现维度匹配。 - 复杂度从实验结果来看,在合理的范围内,可以在实际场景中试试。
TFNet
- 论文:TFNet: Multi-Semantic Feature Interaction for CTR Prediction,2020
- 主要思想:之前的特征交叉利用向量乘法对特征对进行交叉,忽略了不同语义空间的交叉!??
主要内容
模型
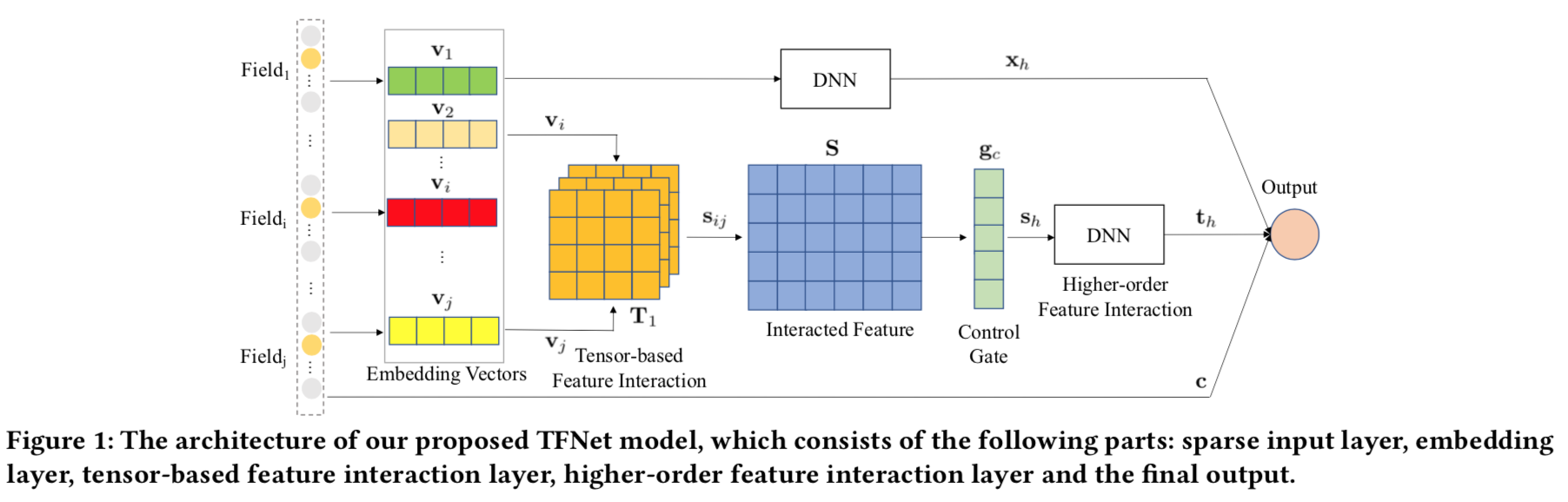
- embedding输入层:n个特征,n个field,每个field通过embedding映射到一个d维向量vi。
- 基于张量的语义交叉,对任意两个特征向量vi,vj,用3阶张量$( T1\in R^{d\times m \times d})$交叉
$$
s_{ij} = vi T1 vj \in R^{m}
$$ - 所有的特征对的交叉构成了矩阵$( S \in R^{q\times m} )$,q=n(n-1)/2
- 自适应门控,认为每个语义空间重要性不一样。
$$
T1 = g_a \odot T2
$$ - Attention权重ga通过第3个张量$(T3\in R^{d\times m \times d})$学到
$$
g_a = softmax(v_i^T T3 v_j)
$$ - 控制门$(gc \in R^q)$,不是所有学到的新特征都有用,用这个门控制只选取有用的特征。
用L1范数限制他稀疏,同时要求非负。最终输出的向量$(s_h = S^T g_c \in R^m)$ - 高阶交互,后续通过一个DNN实现高阶交互。
- 输出层,将原始特征、DNN输出向量、跟TFnet的输出concat后,经过逻辑回归层输出概率。
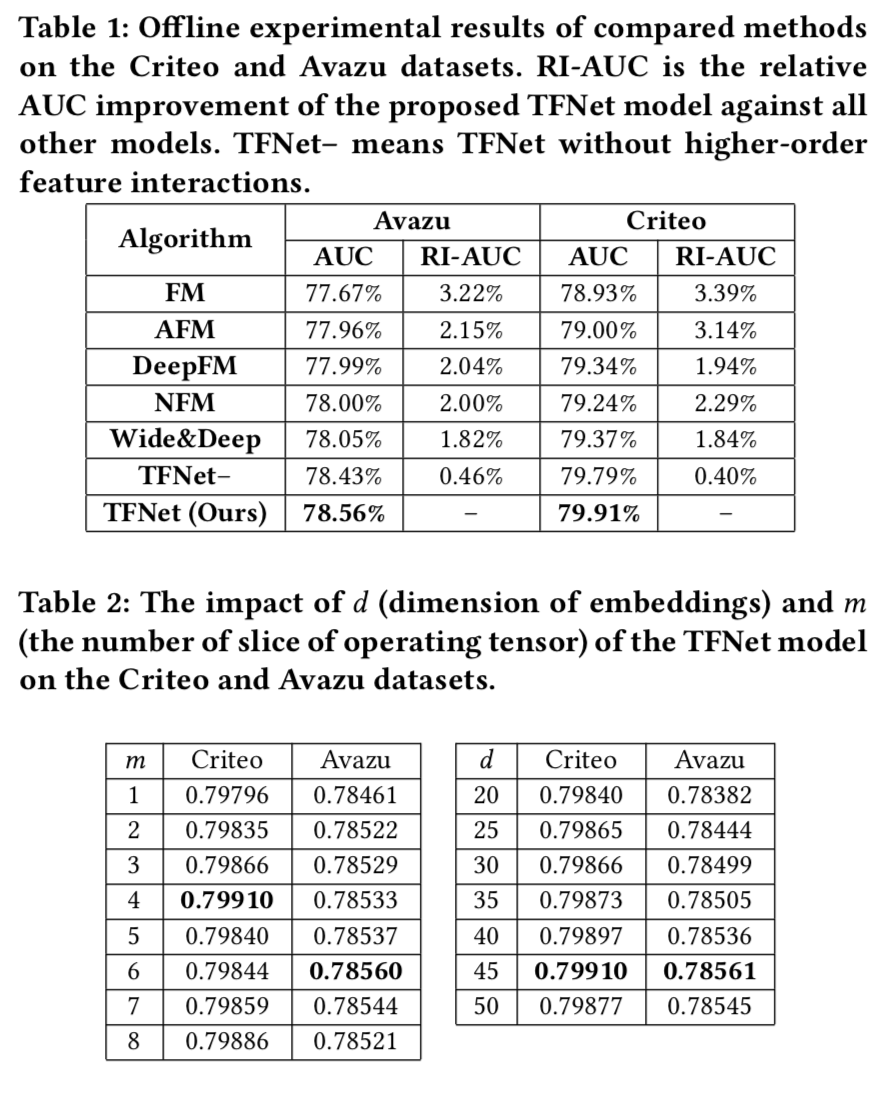
试验结果
- 评估指标,RI-X X是普通指标时为相对提升,X为AUC是减掉0.5之后的相对提升。
- 离线试验,对比了FM,W&D,DeepFM,NFM,AFM
- 在线评估

评论
- 所谓的基于张量的语义交叉,就是一个简单的双线性变换嘛,包装过头了!
- 总的来说是一篇比较普通的文章,没有证实每个部分的必要性,T1,T2,T3,哪个是不可少的?
但是交叉的思想还是有一定参考意义。
时空NN
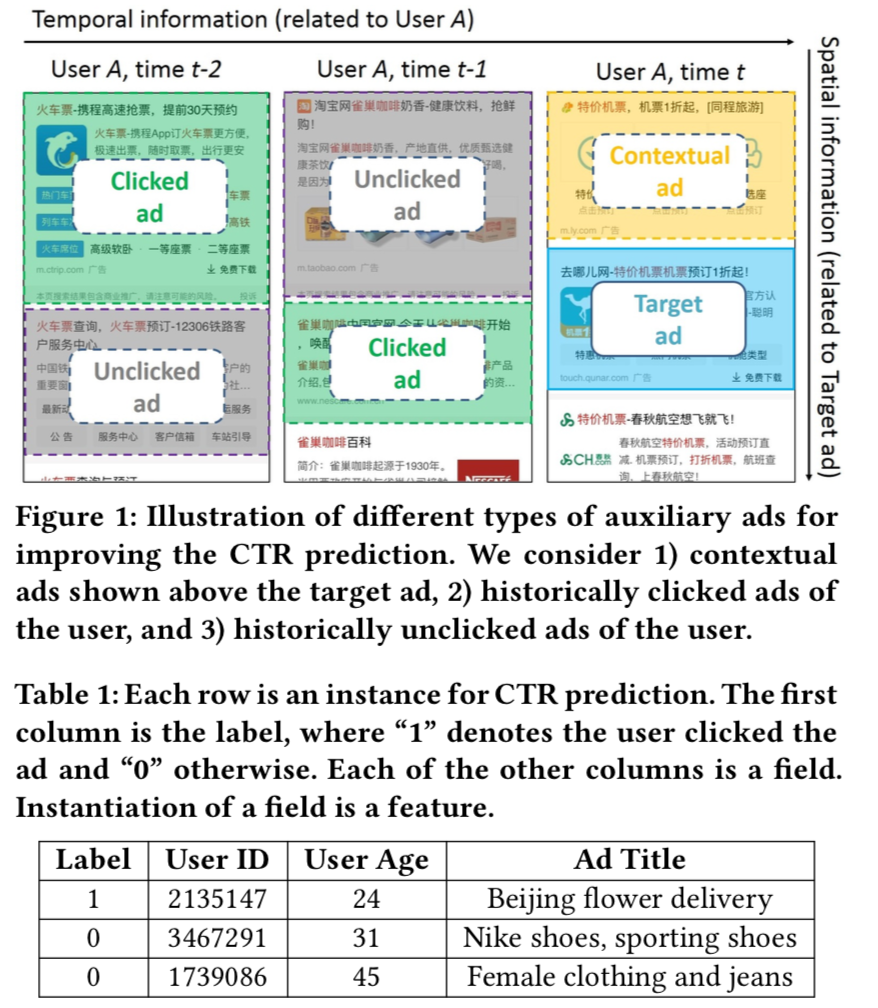
- 论文:Deep Spatio-Temporal Neural Networks for Click-Through Rate Prediction,2019
- 神马搜索,利用辅助数据,利用同页面上的上下文广告,点击跟未点击数据
主要内容
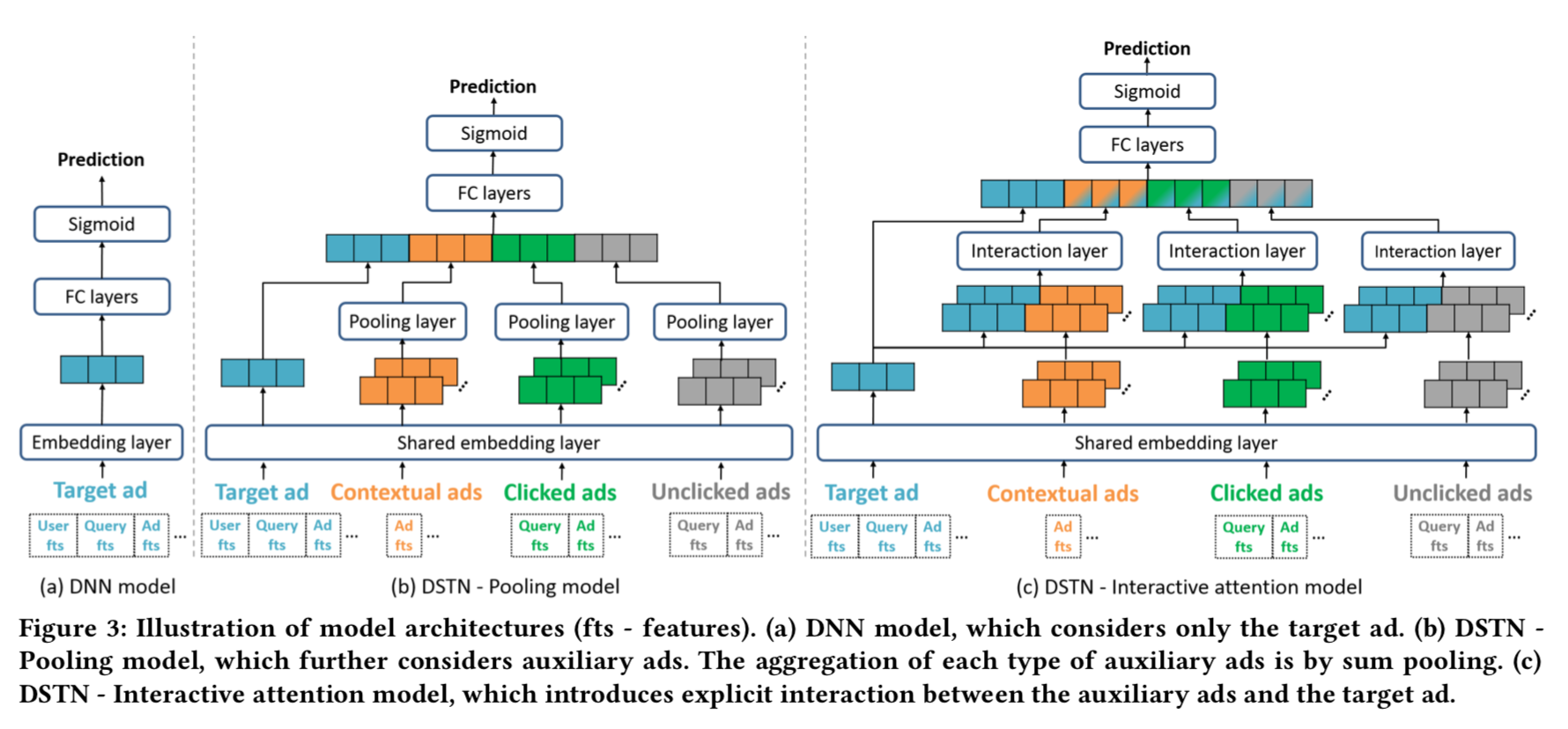
模型
- 特征embedding
- 单值cat特征,直接embedding
- 多值cat特征,embedding后sumpooling
- 连续特征,离散化后embedding
- 经过embedding层后,得到target ad向量 xt,nc个上下文广告向量xc,nl个点击广告向量xl,
nu个未点击广告向量xu - DSTN - Pooling Model:直接sumpooling融合多个广告向量
- DSTN - Self-Attention Model:Attention权重来自于自己,且跟其他特征无关
(这个是跟NLP中的self-attention不一样的点),没有什么意义 - DSTN - Interactive Attention Model:用target ad向量xt跟广告向量一起算
Attention权重。
唯一ID生成算法
- 推荐理由:是一个比较关键的基础算法,可以适当了解一下
- 博客:https://zhuanlan.zhihu.com/p/154480290
主要内容
- 用途:分布式场景的唯一标识
- 唯一ID需要满足的要求
- 全局唯一性:不能出现重复的 ID 号,既然是唯一标识,这是最基本的要求;
- 趋势递增:在 MySQL InnoDB 引擎中使用的是聚集索引,由于多数 RDBMS
使用 B-tree 的数据结构来存储索引数据,在主键的选择上面我们应该尽量
使用有序的主键保证写入性能; - 单调递增:保证下一个 ID 一定大于上一个 ID,例如事务版本号、IM 增量消息、
排序等特殊需求; - 信息安全:如果 ID 是连续的,恶意用户的爬取工作就非常容易做了,直接按照
顺序下载指定 URL 即可;如果是订单号就更危险了,竞争对手可以直接知道我们
一天的单量。所以在一些应用场景下,会需要 ID 无规则、不规则。
- UUID算法(Universally Unique Identifier),uuid有以下几部分组成
- 当前日期和时间,UUID的第一个部分与时间有关
- 时钟序列。
- 全局唯一的IEEE机器识别号,如果有网卡,从网卡MAC地址获得,没有网卡以其他方式获得
- Snowflake,Twitter 2010,Snowflake 以 64 bit 来存储组成 ID 的4 个部分:
1、最高位占1 bit,值固定为 0,以保证生成的 ID 为正数;
2、中位占 41 bit,值为毫秒级时间戳;
3、中下位占 10 bit,值为工作机器的 ID,值的上限为 1024;
4、末位占 12 bit,值为当前毫秒内生成的不同 ID,值的上限为 4096; - 百度 UIDGenerator
PEIA
- 推荐理由:微信,交叉结构有一定借鉴意义
- 论文:PEIA: Personality and Emotion Integrated Attentive Model for Music Recommendation on Social Media Platforms
主要内容
评论
噪声、正则与泛化
- 公众号文章:泛化性乱弹:从随机噪声、梯度惩罚到虚拟对抗训练
- 作者苏剑林写过很多不错的技术文章,而且文笔很好,思考得也有深度,值得我们学习。