不确定性建模
- 论文:What Uncertainties Do We Need in Bayesian Deep Learning
for Computer Vision,NIPS2017 - 推荐理由:跟我之前想得同时建模均值和方差挺像的,不需要有不确定性的标注,
就能建模。但是本文无疑思考得要深刻得多,这种不确定性是系统固有的,可以建模
预测,还有由于数据有限带来的估计偏差,本文通过贝叶斯方法来估计。并且可以
同时估计这两种不确定性。虽然这篇文章是CV任务,但是这种不确定性建模方法原则
上可以应用到很多任务当中。
主要内容
- 对于回归问题,$(y = f_0(x) + \epsilon)$,f0是X能解释的部分,而$(\epsilon)$是
不能解释的固有随机性。这种固有的随机性带来的不确定性叫做 aleatoric 不确定性。
另一方面,在收集数据的时候,数据本身也可能存在误差,比如测量误差等。
这也算作aleatoric不确定性的一部分。这种不确定性无法通过增加训练样本
的方式来消除。 - 另一种不确定性来自于通过有限数据集训练的模型f与真实f0之间的误差,叫做
epistemic不确定性,它可以通过增加训练样本来消除。 - aleatoric不确定性的建模:对于回归问题,同时建模均值函数和方差函数
$$
Y \sim N(f_0(X), \sigma_0^2(X))
$$ - 对于分类问题,将对数几率建模成高斯分布
$$
logit_i \sim N(f_{0i}(X), \sigma_{0i}^2(X)) \\
P(Y=i) = softmax(logit)[i]
$$ - epistemic不确定性的建模:由于它是由于训练数据不充分带来的误差,可以通过
贝叶斯方法来估计。将模型参数全部贝叶斯化,
用不确定性来加权多任务损失函数
- 论文:Multi-task learning using uncertainty to weigh losses
for scene geometry and semantics,CVPR 2018 - 推荐理由:多任务损失函数的权重是个超参数,本文提供一种简单的方法,并且有
不错的理论逻辑。对其他做多任务场景,有一定借鉴意义。文章认为不同任务的损失
函数的权重应该跟他的不确定性成反比。不确定性大的任务损失函数的权重要小一些。 - https://github.com/yaringal/multi-task-learning-example/blob/master/multi-task-learning-example.ipynb
主要内容
- 多任务建模的时候,每个任务的loss会求个加权和得到总loss
$$
L_{total} = \sum_i w_i L_i
$$ - 上述权重对效果影响较大,但是调整这种超参数太费时间了,因为跑一轮CNN,
可能就要几天。 - 多任务联合似然函数,
$$
P(y_1, y_2|f^W(x)) = P(y_1|f^W(x)) P(y_2|f^W(x))
$$ - 对于回归任务,假设分布服从高斯分布
$$
P(y_i|f^W(x)) = N(f^W(x), \sigma^2)
$$ - 对数损失为
$$
log P(y_i|f^W(x)) \propto -\frac{1}{2\sigma^2}||y_i - f^W(x)||^2 - log \sigma
$$ - 所以,两个任务的联合损失见下式,可以看到,权重跟$(\sigma^2)$成反比
$$
L_{total} = \frac{1}{2\sigma_1^2}L_1 + \frac{1}{2\sigma_2^2}L_2 + log \sigma_1\sigma_2
$$ - 对分类问题,用scaled版本softmax
$$
P(y|f^W(x), \sigma) = softmax(\frac{1}{\sigma^2} f^W)
$$
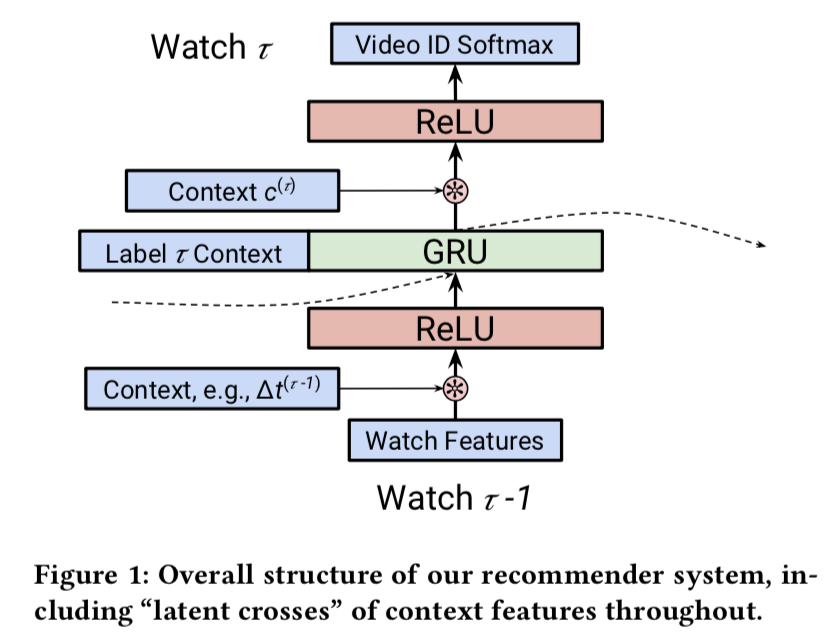
Latent Cross
- 论文:Latent Cross: Making Use of Context in Recurrent Recommender Systems,
WSDM 2018, Youtube - YouTube出品
主要内容
- 场景向量的利用:传统的方法是直接作为特征加到MLP里面,本文采用了
- 隐式交叉:将场景向量跟DNN的隐层做元素乘法
- 场景向量构建:时间、设备类型、页数
-
一阶DNN用ReLU学习交叉比较低效,所以要手动引入交叉
-
上下文向量:
- 时间间隔,即用户相邻两次行为的时间间隔
$$
\Delta t^{\tau} = log (t^{\tau +1} - t^{\tau})
$$ - 终端类型
- 页码
- 时间间隔,即用户相邻两次行为的时间间隔
- latent cross: 因为MLP学习输入两个向量的内积比较困难,所以需要
显式地增加内积。以时间特征为例,$(w_t)$是时间对应的权重
$$
h_0^{\tau} = (1 + w_t) * h_0^{\tau}
$$ - YouTube推荐模型用的是RNN,所以是用场景特征对隐态h来做加权。这种加权
可以看做一种Attention作用。 - 对于多个特征,比如在上述基础上,再增加设备类型。在增加一个加性项来实现。
不用乘法是因为:加法更容易训练,乘法会增加函数的非凸性。
$$
h_0^{\tau} = (1 + w_t + w_d) * h_0^{\tau}
$$
评论
- 这篇文章提到的latent cross比较有意思,他的出发点在于,MLP学习输入的两个
向量的内积比较困难。实际上有不少的文章提到过这个点,我们在实际工作中也发现了。
显式地利用元素乘法来增加交叉有一定的作用。跟本文的做法比较类似。 - 另外,本文主要是将场景向量跟RNN的隐态来做交叉,实际上在其他地方也具有一定的
适用性。
MMOE
- 论文:Recommending What Video to Watch Next: A Multitask Ranking System
- YouTube出品,用MMOE做多任务学习
主要内容
- 解决的主要问题:
- 多目标建模问题,MMOE。点击率,时长等
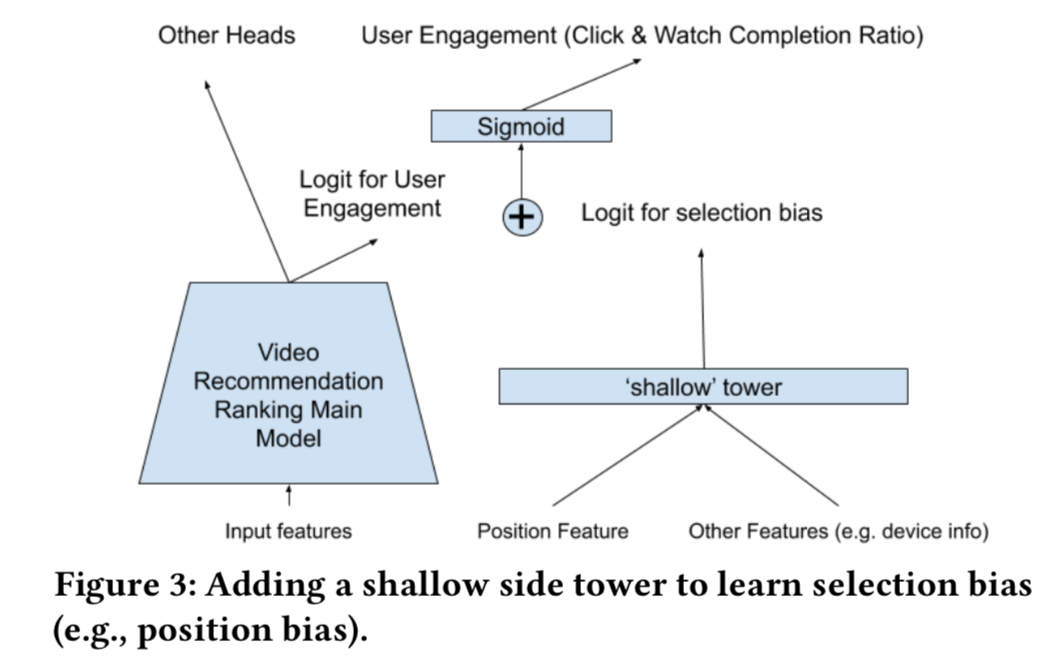
- 隐式选择偏差,W&D。用户点击并不是因为喜欢它,而是因为它展示在前面。
可以通过一个shallow塔来移除这种选择偏差。
- 模型结构
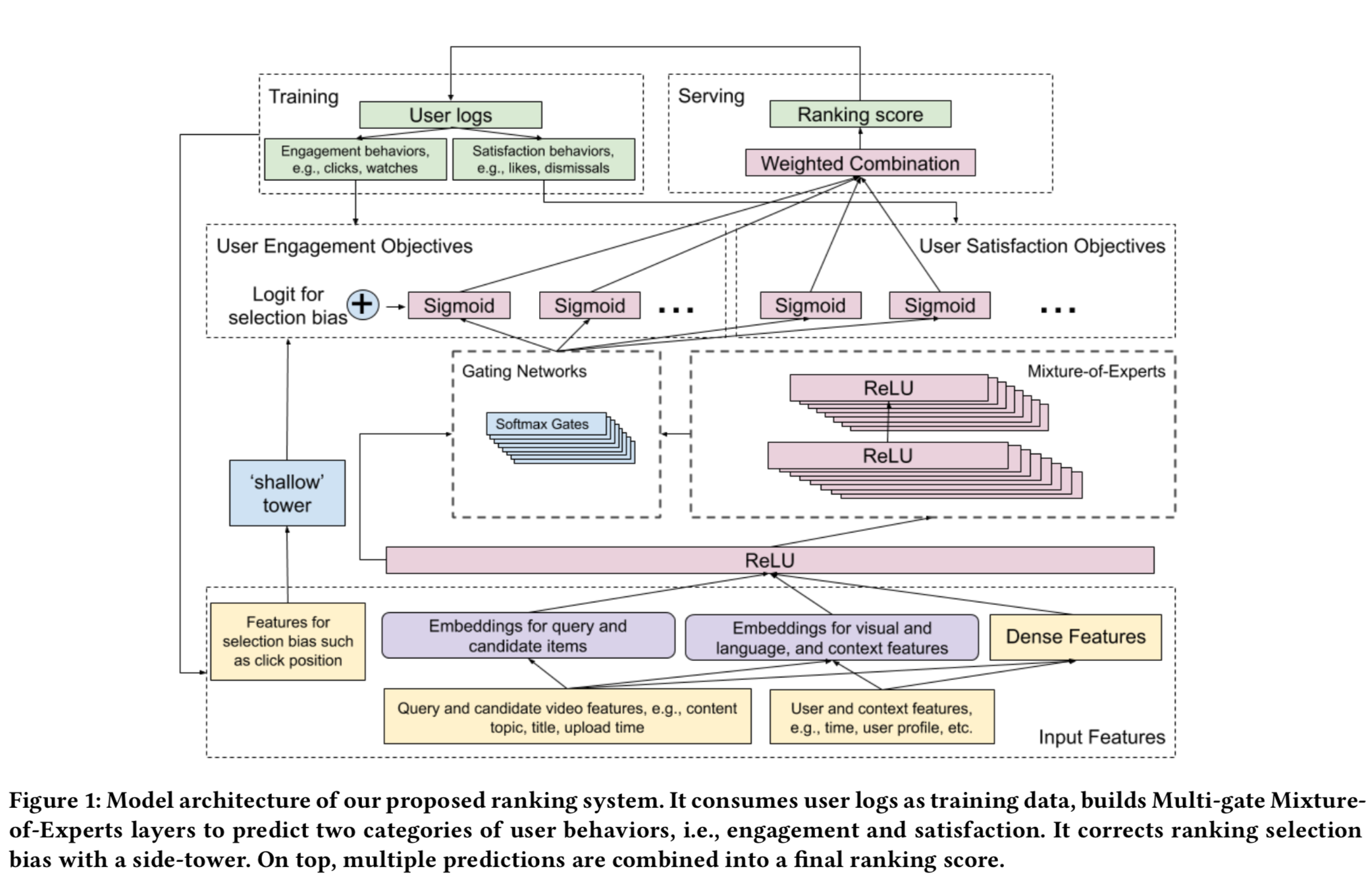
- 将多目标分为两组
- engagement objectives:click,degree of engagement
- satisfaction objec- tives:user liking a video,rating a video
- shallow塔设计
- 输入跟选择偏差有关的特征,如展示的rank,输出是一个标量logit
- 两组bias:position bias,presentation bias
- 当前通用的做法是,将position作为特征去训练,而在预测的时候设置为固定的值,
如1或者missing value - 归一化或正则方法:inverse propensity score(IPS)
- 当前通用的做法是,将position作为特征去训练,而在预测的时候设置为固定的值,
- 其他问题:
- 多模态特征:video内容(视频),audio(音频),标题和描述(文本),用户画像
- 特征
- video meta-data,video content signal
- user demographic,device,time,location
- 目标
- 二分类:点击,喜欢
- 回归:时长,打分
- 多目标融合:手动调权
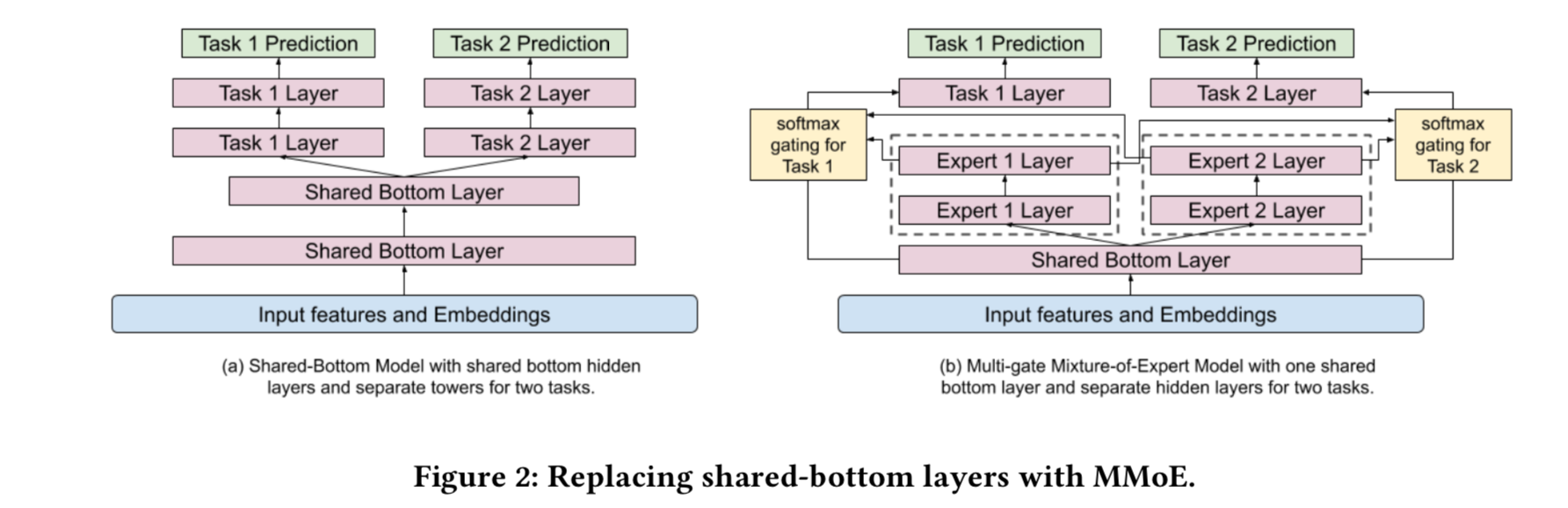
- shared bottom结构的问题:如果两个任务相关性较低,会产生负迁移问题。
MMOE可以解决这个问题。 - MMOE结构:
- MMOE 相比 MOE的改进点在于引入gate,这样一来可以用少量的子网络
实现更多的目标预测!并且训练和预测的计算量也少了很多。
- MMOE 相比 MOE的改进点在于引入gate,这样一来可以用少量的子网络
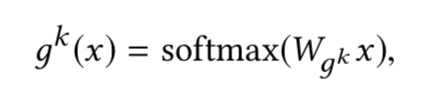
- position bias的移除
- 训练的时候,所有曝光的位置都被使用,并且采用10%的dropout概率,防止模型
过度依赖于位置特征 - 预测时,位置特征设置为missing value
- 位置特征跟设备交叉,因为不同设备其实位置差异比较大
- 训练的时候,所有曝光的位置都被使用,并且采用10%的dropout概率,防止模型
-
产品形态
-
训练细节
- 流式训练,数据按照时间顺序
- 效果数据

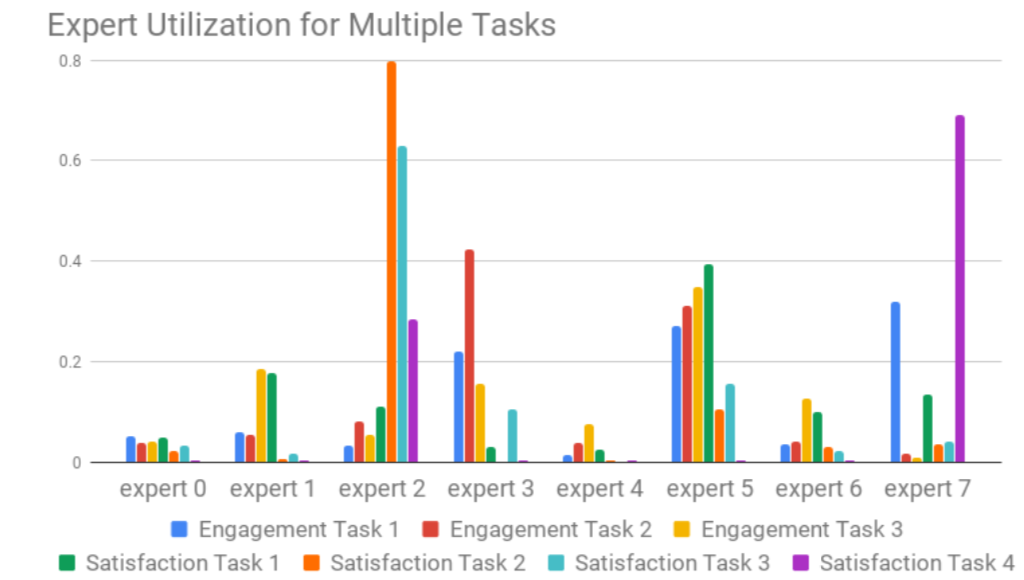
- gate 的分布图
- gate线上试验发现,是否有一层shard层没有什么差异
- gate网络的扩展性
- gate网络存在不平衡问题,导致倾向于特定专家。试验中也发现了20%的几率
会出现这个问题。这种极化现象会造成不利影响,可以通过dropout的方法解决。
具体做法是,以10%的概率设置一些专家的权重为0,并重新归一化softmax的
输出权重。
- gate网络存在不平衡问题,导致倾向于特定专家。试验中也发现了20%的几率
- 位置偏差的对比组
- 直接加特征,然后删除。负向!没有加载wide部分???
- 对抗学习,没太搞懂,线上也没啥效果
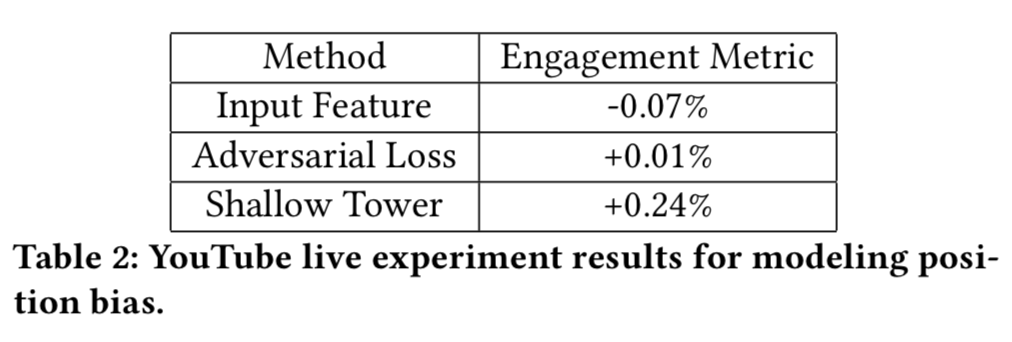
- 还有很多其他bias,暂时难以处理
- 线上线下不一致问题,选择简单一些的模型会更好的泛化到线上
评论
- 位置偏差消除这个点,基本是目前主流做法。值得提的几个点是,训练时使用了dropout,
防止模型过度依赖与位置特征。另一个是将位置特征跟设备交叉,实际上,在别的业务中,
不同的展示流量也可能对这个有影响,比如某些流量展示双栏,而另外一些展示单栏。所以
在实际问题中,应该根据实际情况来决定应该使用哪些position bias特征。 - MMOE中的gate如何降低极化问题的技巧也是个不错的想法。通过随机让一些权重为0,让
模型不要过于依赖某一个专家。 - MOE可能是未来增强模型容量的一个重要的方法,尤其是在推荐场景中!
大规模稀疏MOE
- 论文:Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geofrey Hinton, and Jef Dean. 2017. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538 (2017).
- 回答能不能大规模扩充MOE专家数目
-
专家数目多了,如何控制计算复杂度?利用稀疏性+条件计算!
-
TensorFlow的实现:https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/utils/expert_utils.py
主要内容
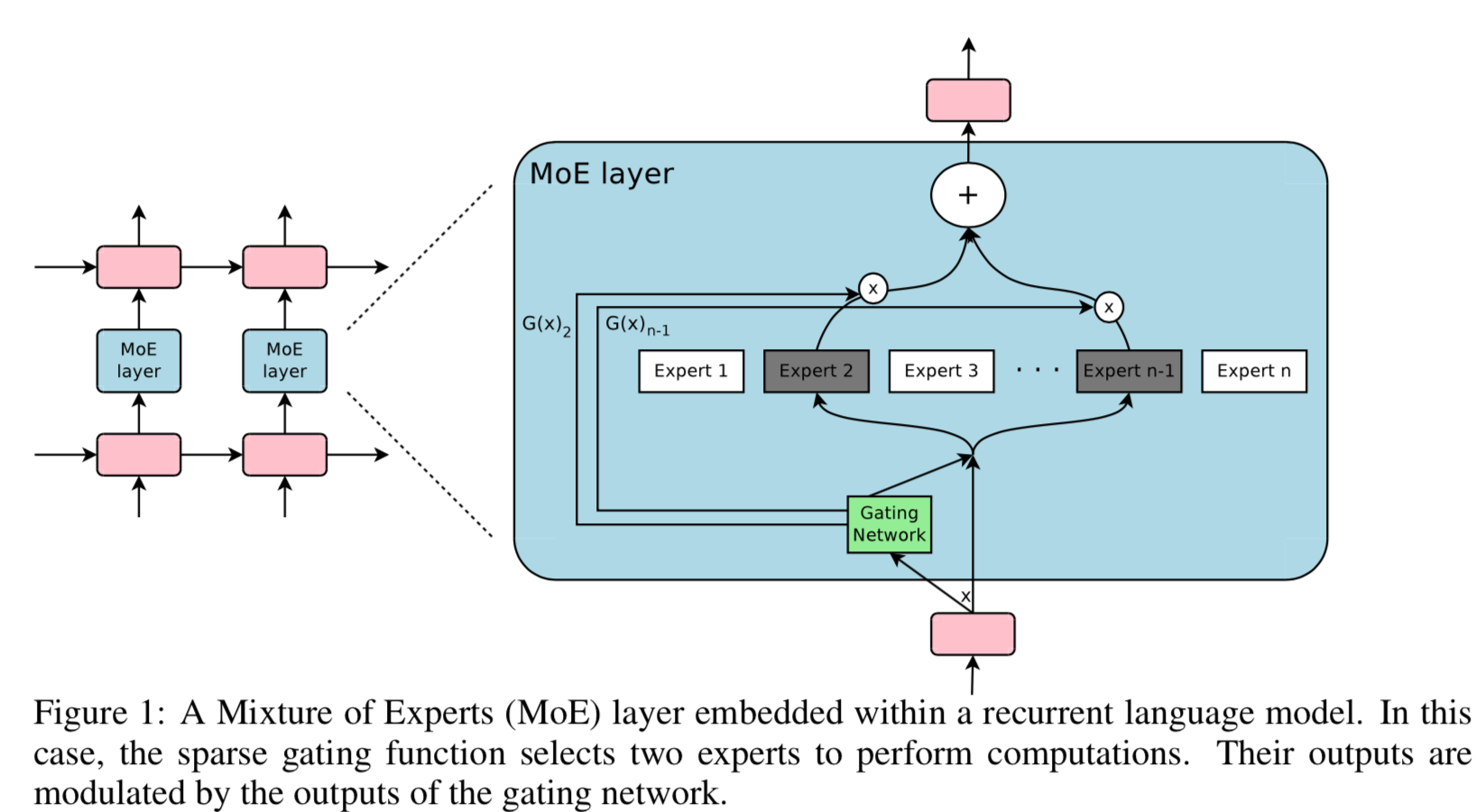
- 现代的计算元件如GPU,更适合计算而不是分支条件
- embedding layer 就是条件计算的一个典型案例
- Noisy Top-K Gating:关键是gate的设计,利用noise + 取 TOPK

-
TOPK操作是否可导?是的,可以类比于思考max-pooling操作也是可导的。
BP的时候,误差只通过TOPK神经元反向传递。 -
训练batch缩小的问题?因为每个batch的样本被分散到多个子网络中,所以
每个子网络的batch数目远小于原来的batch size(如果专家网络很多)。
解决的方法是,增加原始输入样batch的大小。 - 极化问题:模型倾向于总是选择一小部分专家。通过添加用于均衡的损失,强行
让模型选得更加均匀。
评论
- 从诸多文献看来,未来是大力出奇迹的时候。扩充模型容量+数据是提升效果的最
有效的途径。本文的方法实际上是在通过大量子网络提升容量的时候,尽可能地保持
计算性能。关键是稀疏化 + 条件计算! - 令一个要解决的问题是极化现象,在上一篇文章也提到,结合上一篇文章来看,目前
解决的方法有两套,一套是本文的加辅助损失,强行让模型选择更均匀,另一套是利用
dropout的方法,避免过度依赖特定的一些子网络!
向量召回优化
- 论文:Efficient Training on Very Large Corpora via Gramian Estimation
- Google出品
- 解决大规模语料DSSM训练的问题,通常的做法是对未见过的pair做采样当做负样本。
本文的方法可以不用对未见过的pair采样,提升计算性能!
主要内容
- 在学习相似关系的时候,如果只使用观测样本(即正样本)只会将相似的item学到距离接近。
而无法将不像似的item距离学到很远!从而导致实际效果较差! - 相似建模的问题的损失函数如下,第1部分是两个模型学到的emb向量跟相似度的损失
(观测数据部分)。第2部分是先验,每个pair对的先验相似度为Pij,在推荐场景中
基本上可以认为接近于0,即不相似。 - 第二项需要遍历所有的pair,传统方法是通过采样来实现 !即负采样!
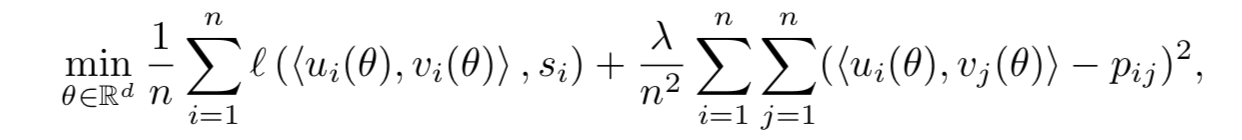
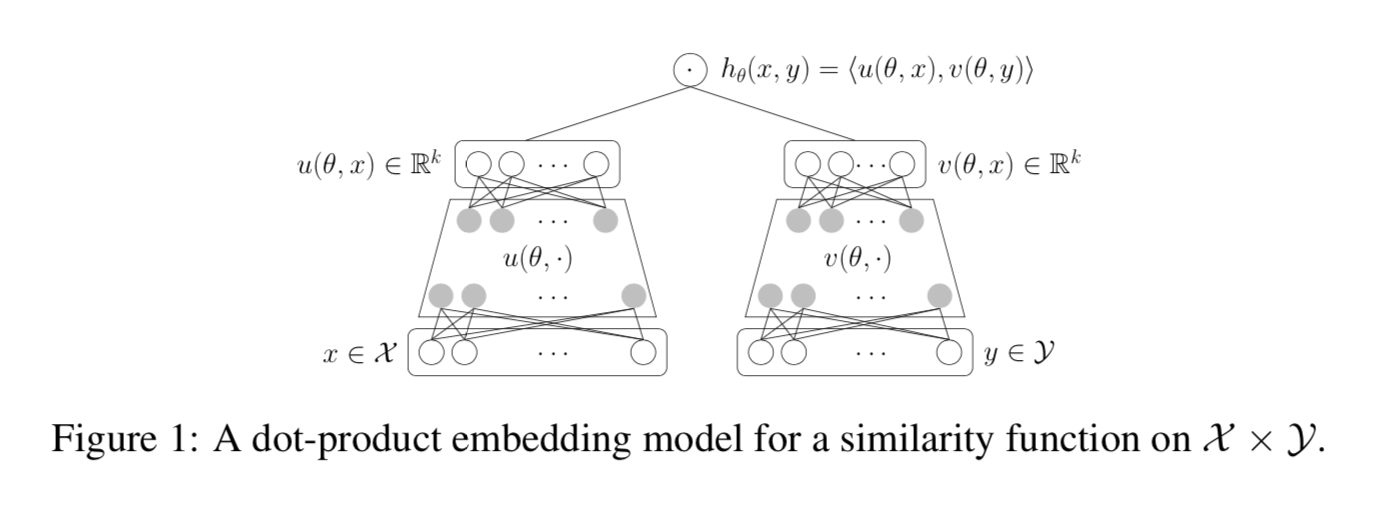
- 第二项,可以通过合理的数学技巧,变换为两个k阶Gram矩阵的内积!!k是emb的维度!
这大大减少了第二项计算复杂度!剩下的问题就是Gram矩阵的问题了。因为计算它还是
费时间,而Gram矩阵依赖模型参数,导致每次迭代都要重新计算!
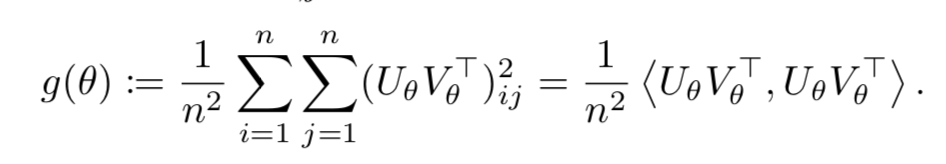
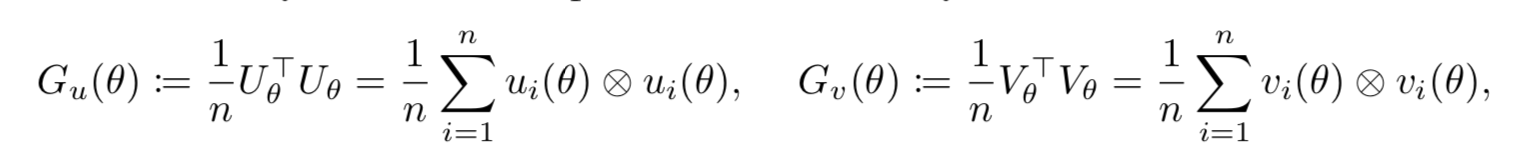
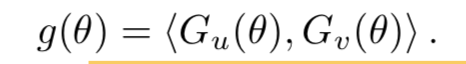
- Gram计算的问题解决:通过维护两个PSD矩阵Gu和Gv来估计它两!那么原问题就可以
通过梯度下降遍历所有观测数据来优化了!而不用采样非观测数据 - Gram矩阵如何估计?见算法流程,略,有点复杂,以后用到的时候再来看,没太搞明白。
文章提出两种方法,随机平均,在线学习两种算法,见下列两个图


评论
- 方法上挺有意思的,并且给出了负采样方法的理论依据是对第二项的近似。
不知道在推荐上是否会比基于采样的方法更好,基于采样的方法貌似落地
要容易一些,并且在采样上可以根据业务来一些定制化!
基于检索的兴趣模型
- 论文:Search-based Interest Model
- 基本思想:用检索的方法从用户行为历史中检索出比较重要的TOP-K行为
- 相比UIC:可以拿到原始行为表达,让用户兴趣跟当前的因素(item,场景etc)相关
- 我们对电商场景兴趣建模的理解愈发清晰:
- 通过预估目标item的信息对用户过去的行为做search提取和item相关的信息是一个很核心有效的技术;
- 更长的用户行为序列信息对CTR建模是非常有效且珍贵的。
- 解读:https://mp.weixin.qq.com/s/vANO8z-UXBE2w9eUG90T-Q
主要内容
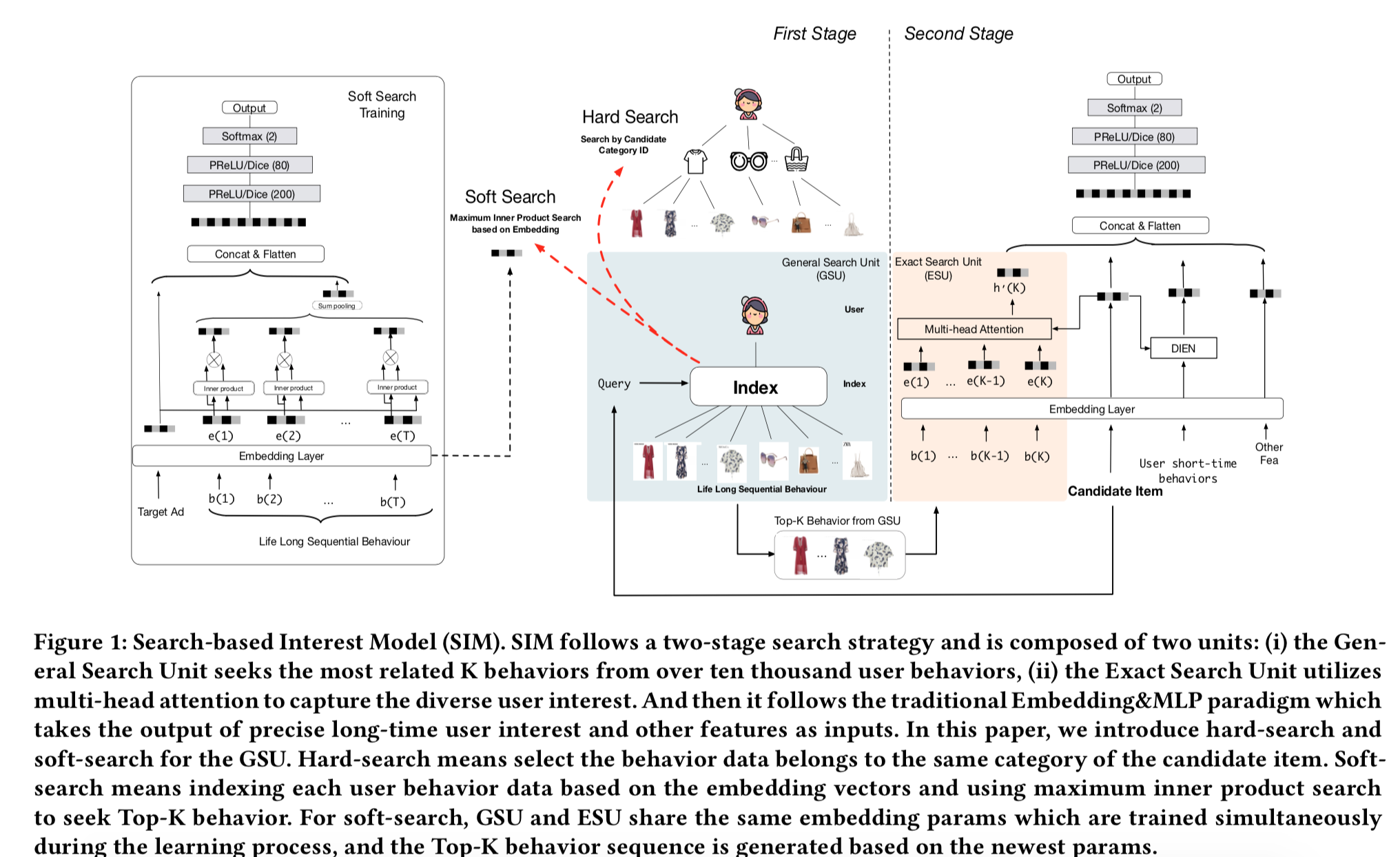
- SIM的核心模块是用户行为历史检索,分为两阶段,General Search Unit (GSU),
Exact Search Unit (ESU)。两阶段是端到端训练的。 - GSU,将行为序列缩短到百量级
- ESU,类似于DIN和DIEN的方法
- GSU的实现,a代表target item,i代表第i个行为
- hard search,根据品类检索
- soft search,向量检索,最大内积搜索(MIPS)
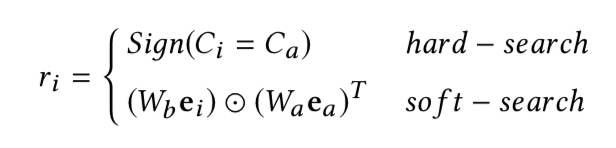
-
soft search的emb向量没有直接用短期兴趣学出来的emb,作者认为短期兴趣分布
跟长期兴趣差异比较大,所以单独搞了个辅助CTR任务来学。该任务只用用户的长期
兴趣表示向量和target item向量concat后,进过一个MLP来预测。长期兴趣的表达
$$
U_r = \sum_{i=1}^T r_i e_i
$$ -
ESU:将item跟时间间隔emb向量拼接到一起,然后进过多头Attention,这里的Attention
不是self-attention,而是DIN那样的Attention。下标b和a分别表示用户第b个行为和target
item a。最终用户长期兴趣的表示是q个head concat后的向量。最终跟其他特征concat后,
放到MLP中做CTR预估。
$$
att_{score}^i = softmax(W_{bi}z_b \cdot W_{ai} e_a) \\
head_i = att_{score}^i z_b
$$ -
线上效果,首页猜你喜欢,CTR +7.1%,RPM +4.4%
- MIMN可以处理1000个用户行为序列,而SIM可以到54000.但是,SIM比MIMN只增加5ms时延。
- Days till Last Same Category Behavior:最后一次产生相同品类行为的天数
- 从下图中可以看到,SIM推荐了跟多的长期行为相关的item,而且在长期行为品类上,
SMI比MIMN的提升要大得多!
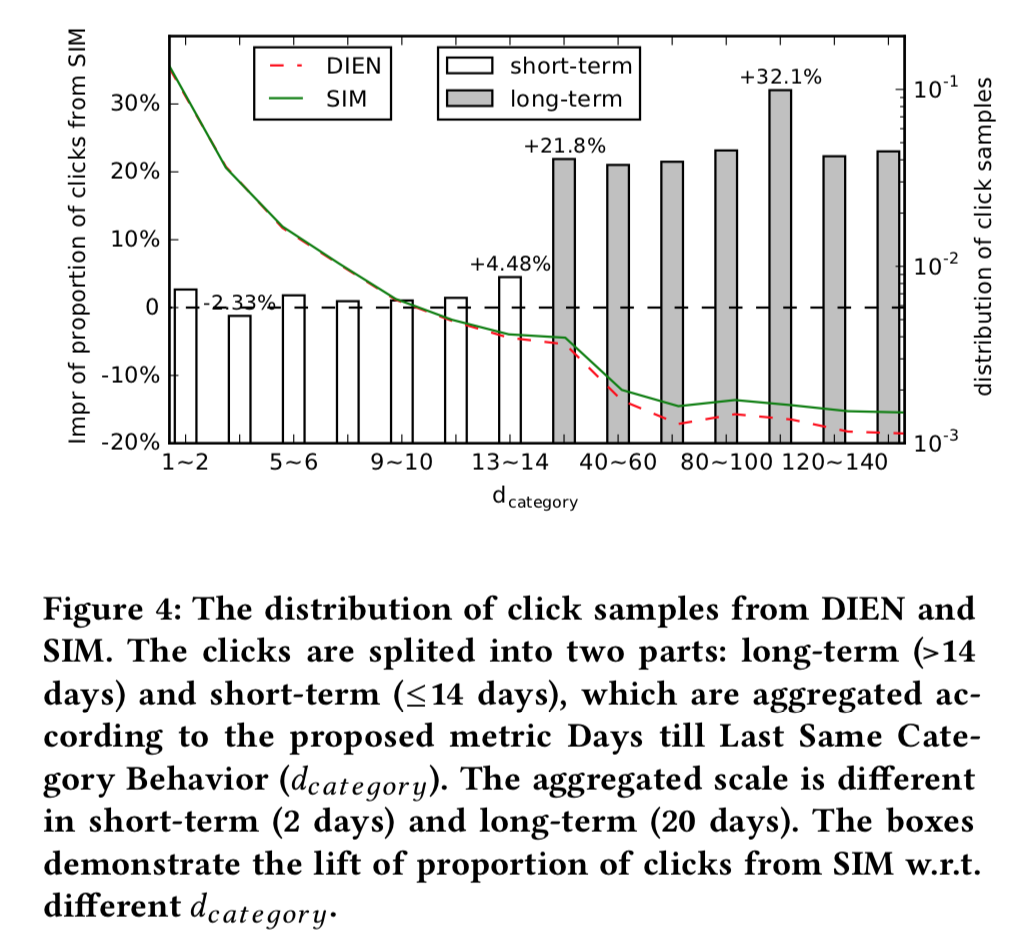
评论
- 一直认为,在推荐系统中,最重要的特征就是用户的历史行为。这篇文章的价值是,
将所有的用户历史行为都拿过来做推荐,同时解决了用户行为历史太长,导致系统
性能搞不定的问题。文章的解决方法是,检索TOPK。而检索可以很快! - 文章的假设是,用户历史行为中跟当前预估的item有关的那些行为很重要,但实际上
不同业务这个假设可能不太一样。有些业务可能是用户在当前场景下相同的行为更重要。 - 另外,作者在Life-long兴趣建模视角CTR预估模型:Search-based Interest Model
中提到,想给每个用户搞一个模型,这个想法实际上跟SGMOE比较像,SGMOE可以看做
所有用户只共享emb参数,模型参数都是不同的,几乎就是每个用户一个模型了。
SGBM
- 论文:Soft Gradient Boosting Machine
- 解读:https://mp.weixin.qq.com/s/lnNeExbA9cJFxxeyTg0EVg
- 推荐理由:周志华死磕GBM
主要内容
- GBM的主要问题:不能在线学习
百度品牌广告
- 论文:MOBIUS: Towards the Next Generation of Query-Ad Matching in Baidu’s Sponsored Search
- query-ad匹配框架
- https://mp.weixin.qq.com/s/Hgl_NtsAclk9PelbA-wEVQ
主要内容
DIN
- 论文:Deep Interest Network for Click-Through Rate Prediction,2017
- 推荐理由:推荐系统处理用户行为特征的一个经典模型,是后续很多模型的基础
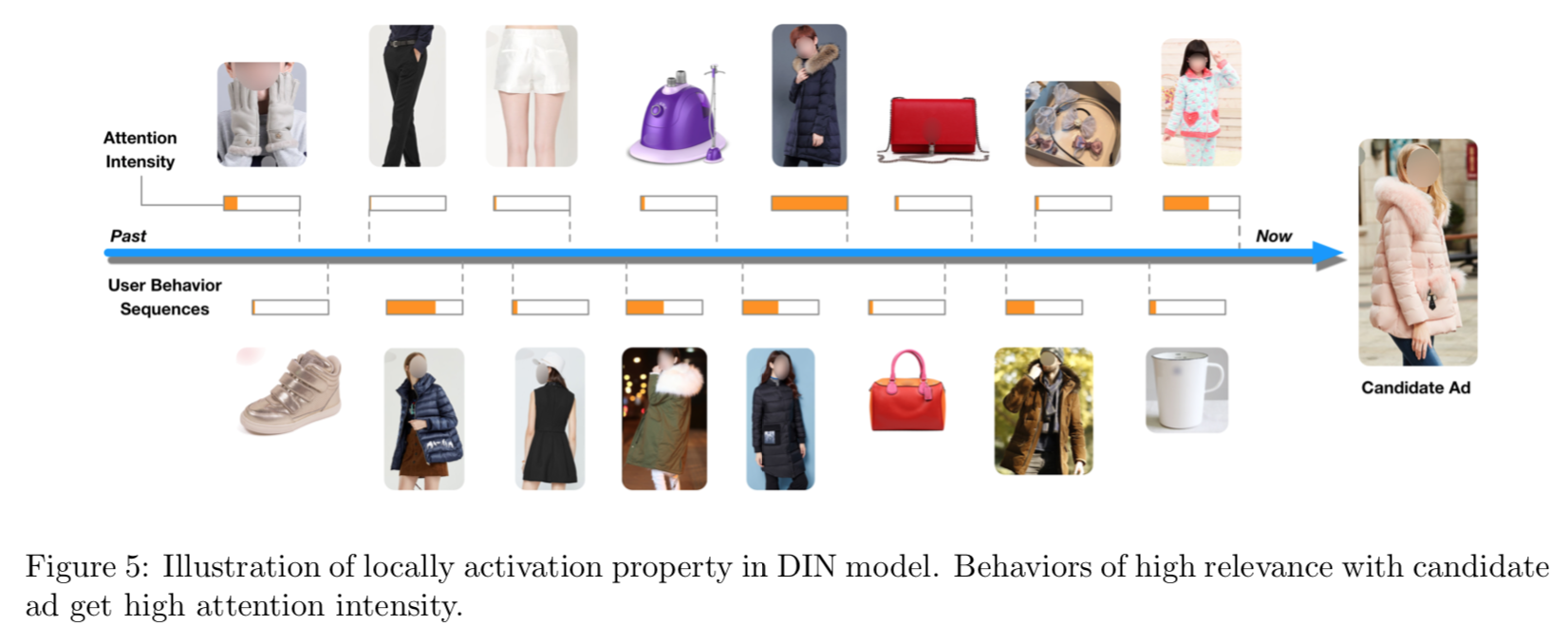
- 出发点是,用户行为历史里面只有部分行为对当前推荐是有价值的
主要内容
- GAUC,按照用户维度聚合的AUC
$$
GAUC = \frac{\sum_i impression_i * AUC_i}{\sum_i impression_i }
$$ -
DIN结构,关键是对用户历史行为用了Attention Pooling,Attention权重取决于
行为中的item跟target item的score
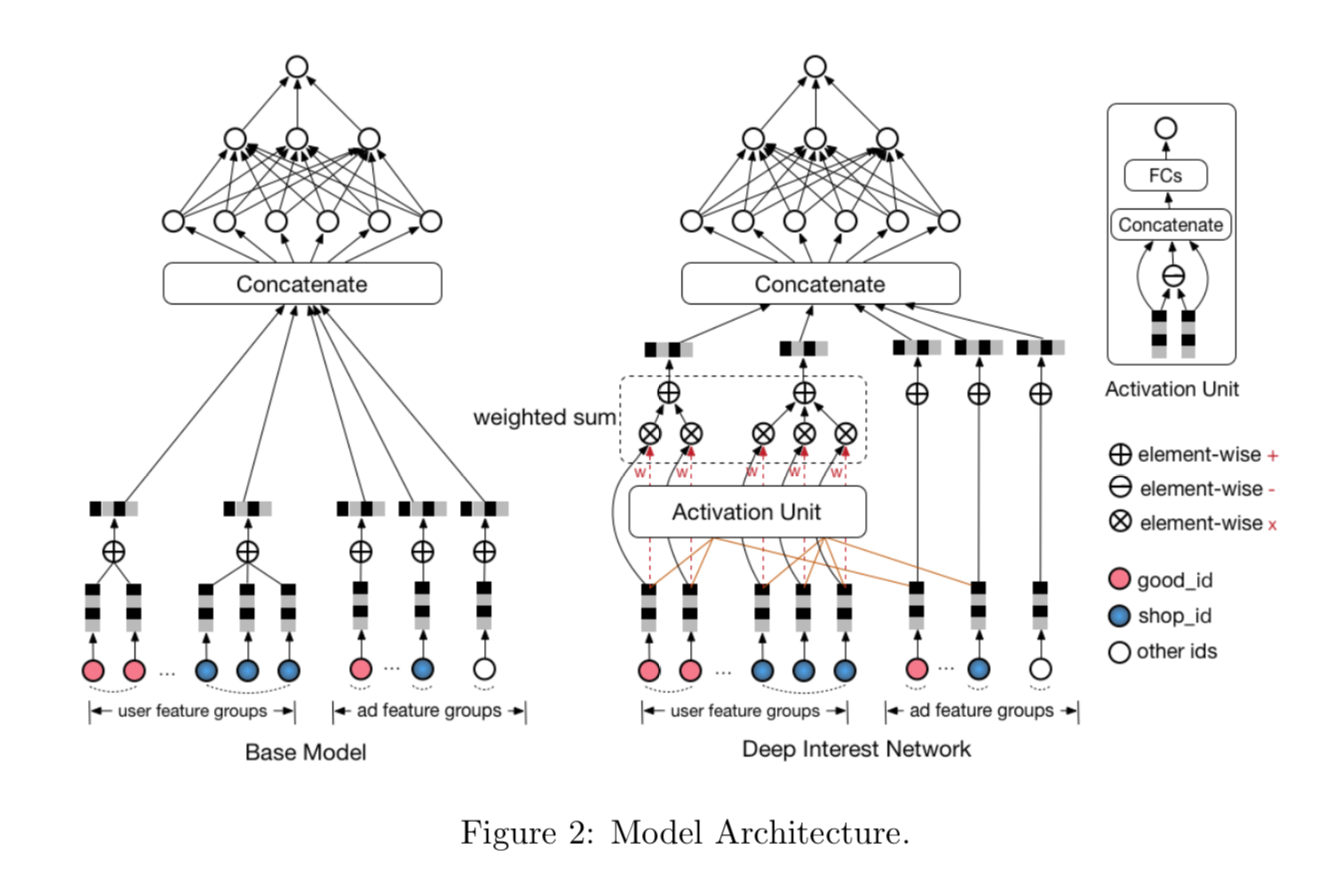
-
DICE:在PRELU上做的改进,根据数据分布选择y和ay的比例,当y>0,p=1,y<0,p=0
的时候,就是PRELU。 -
实现:https://github.com/mouna99/dien/blob/master/script/Dice.py
$$
Dice(y) = a(1-p)y + y \\
p = \frac{1}{1+e^{-\frac{y - Ey}{\sqrt{var[y] + \epsilon}}}}
$$ -
自适应正则,如果特征出现次数很低,其对应的正则项就比较大,否则就很小。相当于
让低频特征的权重更小!
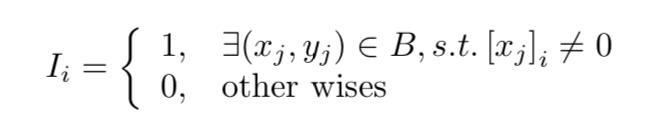
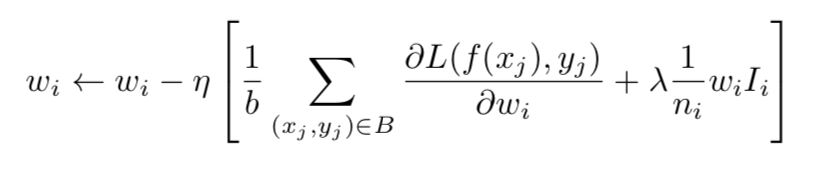
-
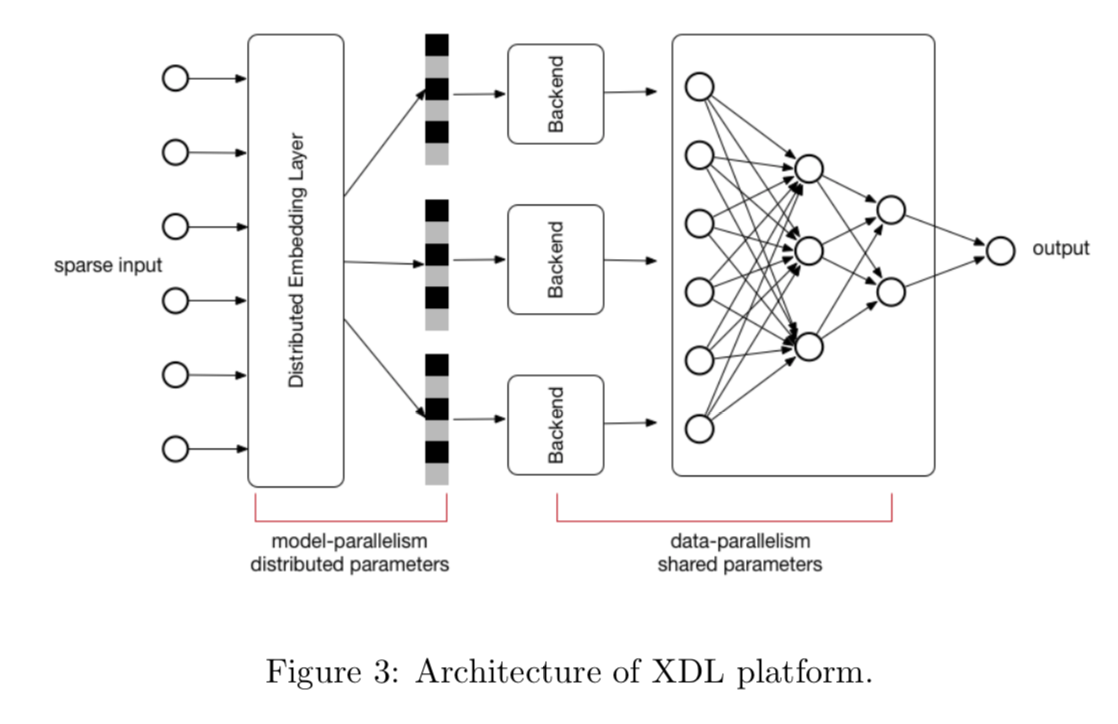
XDL,模型并行,关键是分布式emb层。利用XDL,训练速度加速10倍!
-
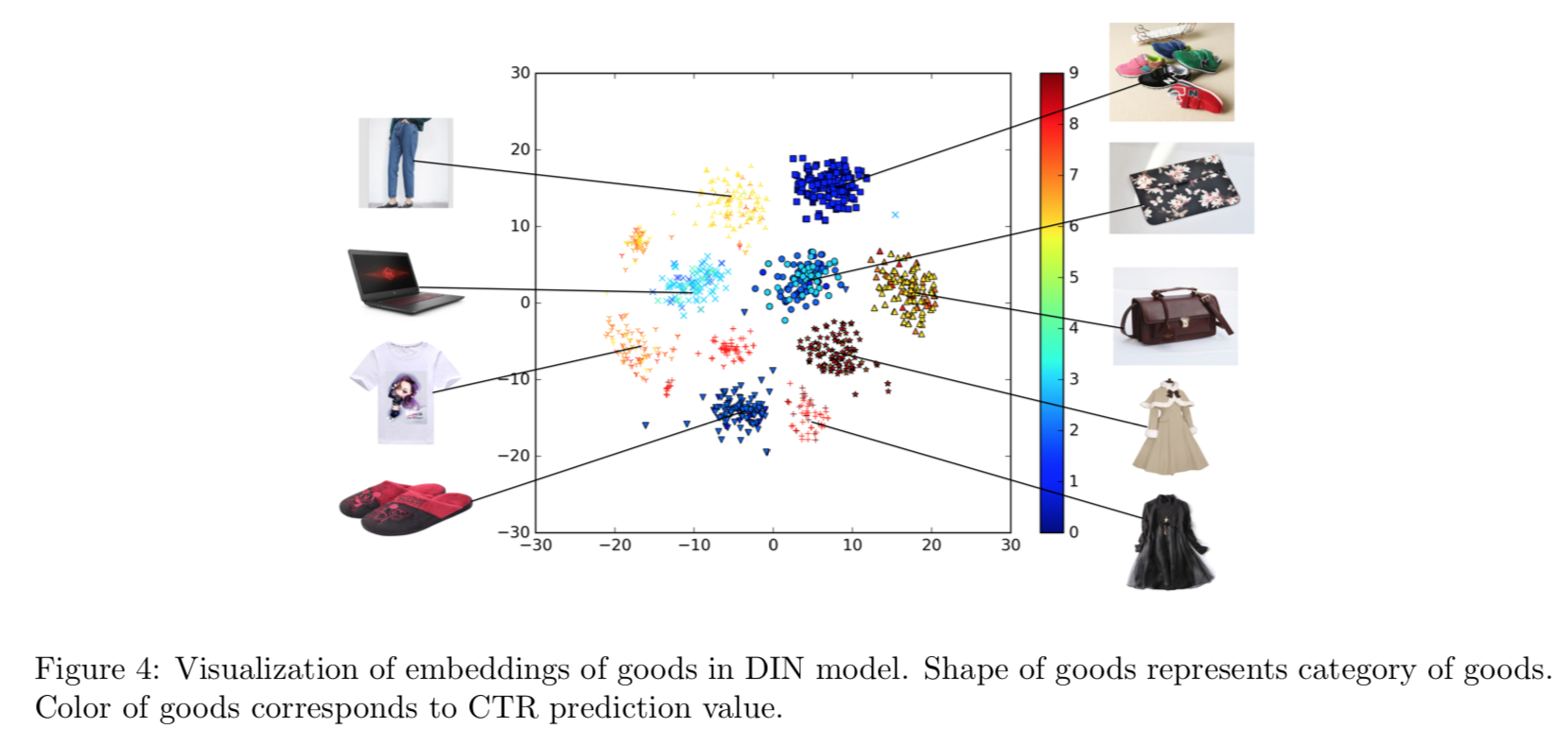
模型可视化
-
实验结果:GAUC最多提升了1.24%,作者认为GAUC更有知道意义。
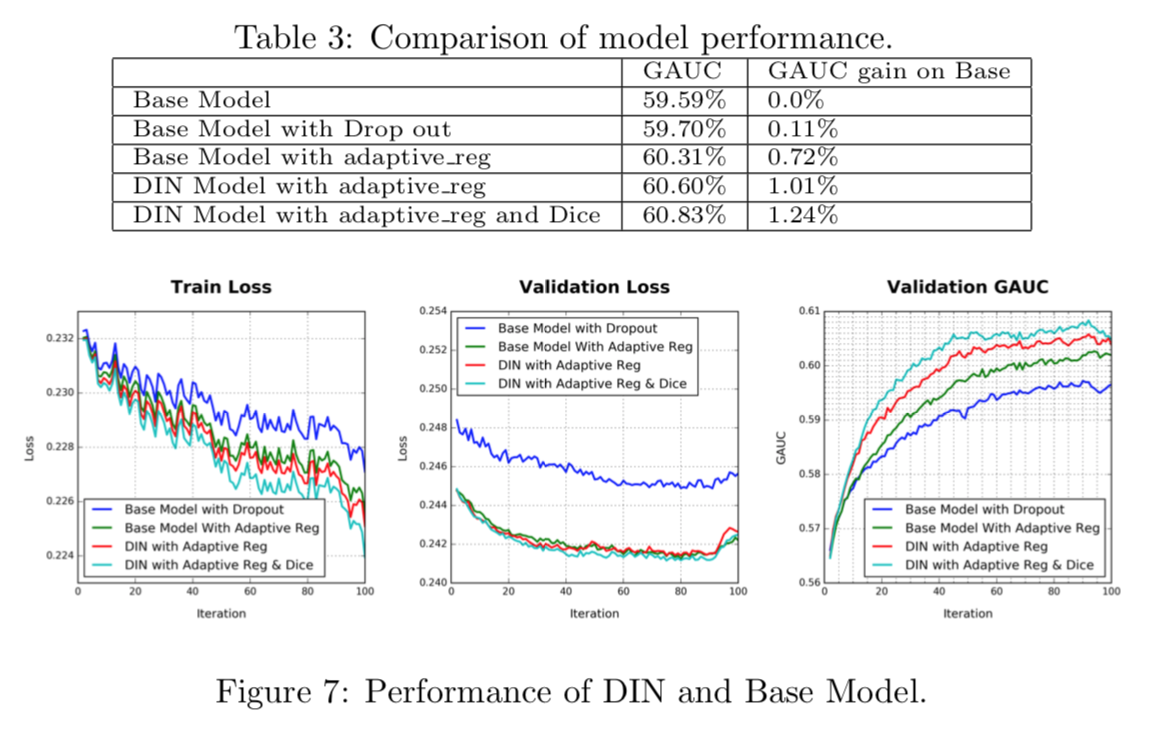
评论
- DIN的想法非常直接,有业务内在意义。Dice确实能加速收敛,在我们的试验当中
也发现是有效的。 - 隐层的emb向量是如何搞出来的?直接分析模型文件么?