Table of Contents
第一名 方案
- Boosting algorithms for a session-based, context-aware recommender system in an online travel domain
- 数据集
- 16M 用户点击事件
- 数据
- user
- session
- timestamp
- action type
- location
- device
- filter preference
- 候选集最多25个
- 目标:按照点击率排序
-
评估指标: MRR https://en.wikipedia.org/wiki/Mean_reciprocal_rank
$$
MRR = \sum_{r_i} \frac{1}{r_i}
$$ -
作者选用了LightGBM,没有优化MRR的目标函数,作者选择了NDCG来做优化目标
- 问题:如何直接优化MRR?lambdaMart不行?
- 特征:220个数值特征30个类别特征
- 最重要的特征是跟最近一次交互的item的交互频率
- 最主要有用的特征是item和user-item交互特征,user的特征没太大用
- 作者还构造了一些item-item的相似特征
- 第一个item是指query下的item,第二个item指的是用户交互过的item
- 每一个hotel有一个属性集合,用户点击过的item-item相似,是拿每一个点击过的item跟候选的item在属性维度算一个jaccard距离,然后在所有点击过的item上平均。用户点过的item是指在一个事件窗口内点击过的item
$$
d_{uh} = \frac{1}{t} \sum_{h_c=1}^t \frac{|R_h \cap R_{h_c}|}{|R_h \cup R_{h_c}|}
$$
- rank变换
- 在一个query中,某个特征(如价格)的排序值
- 在曝光位置前/后的item的特征(如价格)
- 跟曝光位置前/后的item的特征(如价格)差异
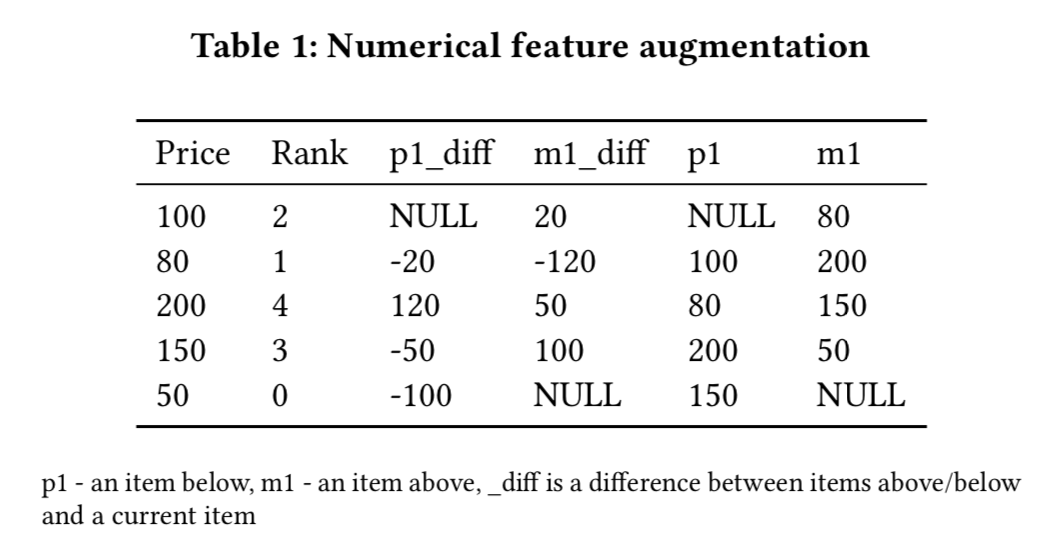
- 累积特征,将用户session开始以来的事件来提取累积特征,如累积CTR?
FAQ
这个比赛的目标是什么
- 数据集
- 16M 用户点击事件
- 数据
- user
- session
- timestamp
- action type
- location
- device
- filter preference
- 候选集最多25个
- 目标:按照点击率排序
- 评估指标: MRR https://en.wikipedia.org/wiki/Mean_reciprocal_rank
$$
MRR = \sum_{r_i} \frac{1}{r_i}
$$
MRR跟AUC和NDCG的区别和联系是什么
- 都是用来衡量排序好坏的指标
- AUC是全量样本之前排序好坏,MRR和NDCG都对用户做了归一化,不比较用户间的相对排序,因此这两个指标跟gAUC更像
第一名方案的作者为什么选择NDCG来做优化目标
- 作者用LightGBM,不支持直接优化MRR,但是支持NDCG
- 在只有一个正样本的情况下,MRR和NDCG只相差一个对数变换,MRR是1/r,而NDCG是1/log(r+1)
如果改造lambdaMART支持MRR该如何实现
训练集和验证集如何划分的
- 原始数据集是一周的数据,作者将周一到周五划分为训练集,周六和周日作为测试集
- TODO,验证集如何划分?
- 作者每个模型有两个版本,一个版本是用不包含验证集数据训练的模型,用于验证;一个版本是包含验证集数据训练的模型,用于最终提交预测结果
论文中有哪些重要有借鉴价值的特征构造
为什么user特征价值没有item以及user-item交互特征大
- 因为user的特征更像是一种bias
- 直观地来理解,item的排序一个是item是否热门是否够好(这些信息只跟item有关);一个是用户对item的偏好(这个是用user-item交互特征表达);而用户的基础特征偏静态,在实时排序中影响自然没有前两者那么大
item-item相似特征是如何构造的
- item跟item的相似通过属性上的jaccard距离来算的
- user跟item的相似是通过user在一个事件窗点击过的每一个item跟item的相似平均得到的
- 这个方法基本跟现在attention-Pooling类似
用户跟新hotel的交互概率是干什么的
为什么需要rank特征变换
- 因为人在判断item是否点击时,会参考上下文来做,所以rank特征变化本质是加入上文和下文item的特征