论文列表
A Survey on Session-based Recommender Systems
- 基于session的推荐系统
- 基于内容的推荐(找相似内容)和基于协同过滤(利用用户行为找相似的人/物),偏静态,无法快速捕获用户的实时兴趣点的变化
- 将session作为推荐的基本单位而不是将用户作为基本单位
- session的概念: A session is a set of items (e.g., referring to any objects, e.g., products, songs or movies) that are collected or consumed in one event (e.g., a transaction) or in a certain period of time or a collection of actions or events (e.g., listening to a song) that happened in a period of time (e.g., one hour).
- 即在一个事件(比如交易)中被获取或消费的一系列item的集合, 或者在一段时间内发生的动作或事件的集合
- session推荐系统:Given partially known session information, e.g., part of a session or recent historical sessions, an SBRS aims to predict the unknown part of a session or the future sessions based on modelling the complex relations embedded within a session or between sessions.
- 即根据session的一部分来预测未知的部分、或者未来的session事件以及session之间的关联
- 两个方向: 推荐下一个/多个item; 推荐下一个session
- 基于session推荐: 基于session上下文预测target,有时也加入item特征和user特征

- item是基本单位,也是基于session的推荐系统的主要角色,其他的要么是描述item的特征,要么是组织item的结构如session
- 每个item都被多种特征所描述: item的类别,价格,位置等等
- 大多数情况下,item的相关性建模都基于他们的共现
- 关键挑战
- inner-session challenge
- inter-session challenge
- outer-session challenge
- session上下文: 时间、地点、天气、季节、用户; 这里将用户信息看做上下文信息
- 参考:
- Duc-Trong Le, Yuan Fang, and Hady W Lauw. 2016. Modeling sequential preferences with dynamic user and context factors. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases. Springer, 145–161.
- Gediminas Adomavicius and Alexander Tuzhilin. 2011. Context-aware recommender systems. In Recommender systems handbook. Springer, 217–253
- Longbing Cao. 2015. Coupling learning of complex interactions. Information Processing & Management 51, 2 (2015), 167–186
- 多样性挑战
- 特征值的多样性,不同值出现的频率不大一样
- 特征类型的多样性
- item的多样性,一些出现频率高二另外一些很少出现
- session的多样性,不同上下文对当前session的相关性不一样,不知道是个什么鬼
- 上下文的多样性,很多不同类型的上下文因子,时间、地点
历史
- 最早始于1980年[1],
- 两个阶段:
- 1990s-2010s, model-free阶段; 模式挖掘,关联规则挖掘,序列挖掘
- 2010s-今, Model-base阶段; 时间序列相关模型,马尔科夫链,RNN,DNN
- 研究社区关注, [2-4]
- what to recommend, 购物篮数据, 事件历史数据(movielens, POI)
- how to recommend, 建模session内的依赖
- item的顺序在某些场景非常重要,比如基因数据,但是在另外一些场景价值比较有限,比如加购物车的顺序。顺序关系比较重要的场景可以使用马尔科夫链、RNN等捕获序列关系的模型
- 不考虑顺序的模型,发觉共现规律
- 一阶依赖与高阶依赖, 一阶依赖:一阶马尔科夫链、因子机; 高阶依赖: 神经网络
- session间依赖, 将上一个session也输入模型
- item依赖模型,建模来自于不同session的item间的依赖: 因子机模型
- 集合依赖模型,将session中的item看做一个整体
- 特征级别的依赖, 功能互补的item经常出现在同一个session当中。 基于内容的推荐,解决冷启动的问题, 协同过滤。早期的推荐系统研究较多,基于session的推荐研究较少
- 技术类别:
- model-free 方法:
- 基于模式/规则的方法, 关联挖掘, 牛奶和面包通常一起购买, 挖掘无序数据
- 基于序列模式的方法, 挖掘有序数据规律
- model-based方法:
- 马尔科夫链
- 因子机方法
- 神经网络模型方法, 也叫 embedding模型和表示学习模型
- model-free 方法:
-
不同方法的比较
- model-free方法:简单容易实现,对于复杂的数据和关系挖掘力不从心
- model-based方法:能处理复杂的数据和关系挖掘,上限很高
-
基于模式/规则的方法
- 频率模式挖掘, Aprior、 FP-Tree, 如果P(i|s)概率高于某个阈值,就可以认为
- 序列模式挖掘
- 频率模式挖掘, Aprior、 FP-Tree, 如果P(i|s)概率高于某个阈值,就可以认为
- 基于模型的方法
- 马尔科夫链, 频率统计估计概率
- 马尔科夫embedding模型, 解决马尔科夫链稀疏的问题,不是用统计频率来估计转移概率,而是用embedding向量的欧式距离建模概率 $(P(i_1 \rightarrow i_2) = exp(-||v_{i_1} - v_{i_2}||^2) )$, 问题: 破坏了非对称性??
- 因子机模型, 为每个用户建立因子模型, $(A^{|U| \times |I| \times |I|})$, 每个元素代表某个用户从1个item转移到另一个item的转移概率。
- Tucker Decomposition, $(A = C \times V_U \times V_{I_j} \times V_{I_k})$, C是核心张量, $(V_U)$ 是用户特征矩阵, $(V_{I_j})$和$(V_{I_k})$分别代表最后的item矩阵和下一个item矩阵。乘法分解
- Canonical Decomposition, 加法分解。 $(a _ {u, i _ j, i _ k} = (v_u, v_{i_j}) + (v_u, v_{i_k}) + (v_{i_j}, v_{i_k}))$
- 神经网络模型方法
- 浅层网络, item2vec, user2vec, 在隐空间匹配
- 深层网络, RNN做序列推荐, GRU2Rec, DNN推荐, CNN
未来的方向
- 用户通用偏好
- 利用用户显式偏好,长期偏好和短期偏好
- 更多上下文因子,
- 噪声和无关的item, 用户点击item的行为具有太多随机性了,怎样将随机性去除,而只将有规律的信号建模出来? attention, Pooling
- 多步推荐, Encoder-Decoder 框架?
- cross-session information, 相当于偏长期一点的依赖
- cross-domain information, 看了电影, 听对应的歌曲, transfer learning
- 非IID的时变问题
参考
[1] Ahmad M Ahmad Wasfi. 1998. Collecting user access patterns for building user profiles and collaborative filtering. In Proceedings of the 4th international conference on Intelligent user interfaces. ACM, 57–64
[2] Balázs Hidasi, Alexandros Karatzoglou, Oren Sar-Shalom, Sander Dieleman, Bracha Shapira, and Domonkos Tikk. 2017. DLRS 2017: Second Workshop on Deep Learning for Recommender Systems. In Proceedings of the Eleventh ACM Conference on Recommender Systems. ACM, 370–371.
[3] Alexandros Karatzoglou and Balázs Hidasi. 2017. Deep Learning for Recommender Systems. In Proceedings of the Eleventh ACM Conference on Recommender Systems. ACM, 396–397.
[4] Alexandros Karatzoglou, Balázs Hidasi, Domonkos Tikk, Oren Sar-Shalom, Haggai Roitman, Bracha Shapira, and Lior Rokach. 2016. RecSys’ 16 Workshop on Deep Learning for Recommender Systems (DLRS). In Proceedings of the 10th ACM Conference on Recommender Systems. ACM, 415–416.
[5] Shoujin Wang and Longbing Cao. 2017. Inferring implicit rules by learning explicit and hidden item dependency. IEEE Transactions on Systems, Man, and Cybernetics: Systems (2017)
[6] Wei Wei, Xuhui Fan, Jinyan Li, and Longbing Cao. 2012. Model the complex dependence structures of financial variables by using canonical vine. In CIKM’12. 1382–1391.
[7] Jia Xu and Longbing Cao. 2018. Vine Copula-Based Asymmetry and Tail Dependence Modeling. In PAKDD’2018, Part I. 285–297.
基于规则的算法
Aprior 算法
- item集合 I , 也就是要推荐的东西的集合,比如商品集合,poi集合, I
- session集合 S, 每条记录s代表一个item list,表明他们之间存在某种关联,比如同时在一个订单中出现, 同时在用户的一个session中出现等等。 s是 I的子集
- 支持度 $(support(A => B) = P(A \union B) )$, A和B都是I的子集, 支持度高的规则可以用来做推荐, 例如A是用户已经点击过的item集合,如果support(A => B)很大,那么就可以认为B是要给用户推荐的item集合。联合概率
- 置信度 $(confidence(A => B) = P(B | A) = \frac{P(A \union B)}{P(A)})$, 条件概率
- 强关联规则, 满足最小支持度和最小置信度的关联规则
- 由于任何(k-1)非频繁项集都不是k频繁项集的子集,所以在构建的时候可以减枝,在生产k项集的时候,可以只考虑k-1频繁项集的扩展集合即可
FP-Tree
- 论文:Mining frequent patterns without candidate generation, 韩家伟
- 并行版本实现: parallel fp-growth for query recommendation, Spark ml 库使用的方法
- Frequent Pattern Tree
- 关键是构建FP树
- 遍历整个数据集, 统计出每个item的次数,只保留超过最小支持度的item
- 将每条记录中的item按照item的全局频次排序
- 将排序号的列表插入到FP树中, 直到所有数据插入完成, 得到一个包含了数据集所有统计信息的数据结构
- FP树包含了用于频繁模式挖掘的所有信息, 是完备的
- FP树构建复杂度分析
- 只需要扫描数据库两次, 1次统计每个item的次数, 1次构建树
- 时间复杂度是 O(|transaction|)
- FP树的高度不超过每个transaction中频繁item的数目最大值
- FP树节点的数目不超过全部transaction中频繁item的数目总和
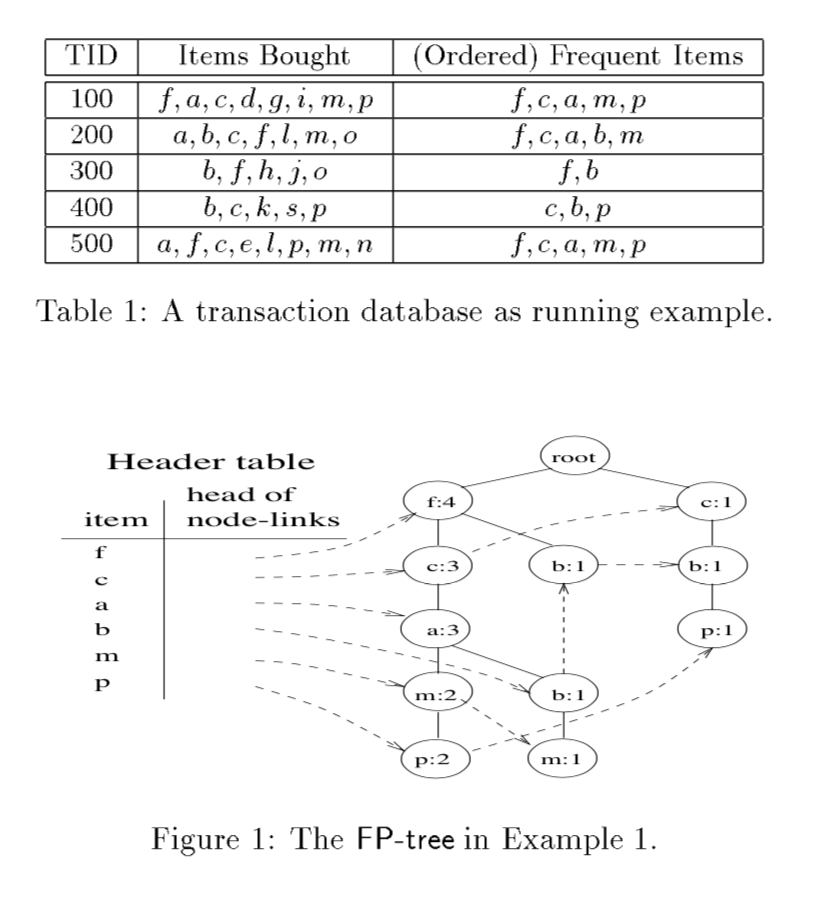
- 根据FP树寻找频繁集算法 FP-Growth, 扫描数据库,构建主FP树,然后执行一下算法,初始后缀为空集
- 对FP树中的每个item,寻找以item结尾的所有路径构造子FP树,每个节点的次数也调整为item的次数。相当于从原始数据库中只筛选出包含item的transaction,并且去掉频率比item低的其他元素,构建FP树。去掉频度低的是为了避免重复统计。
- 在每个子FP树递归使用该算法,寻找频繁子串,直到FP树为空,或者item的所有路径上的频率之和不超过最小支持度。这些频繁子串与后缀拼接,得到完整的频繁子串

并行FP
- 论文: parallel fp-growth for query recommendation, Spark ml 库使用的方法, Google China, 2008
序列FP
- 论文: PrefixSpan- Mining Sequential Patterns Efficiently by Prefix-Projected Pattern Growth
- 。。。
改进应用
- PV时间加权来计算规则的加权频率
- 引入用户个性化: 用户聚类
- 对关联规则加权,用规则中item的某种权重,都是手工设计的
- 将协同过滤和关联规则结合起来
序列模式挖掘
- Effective next-items recommendation via personalized sequential pattern mining, 2012
推荐理由
- Explainable Recommendation: A Survey and New Perspectives
- 推荐理由的方法: https://zhuanlan.zhihu.com/p/21497757
- 基于内容的推荐理由:
- 将item的一些特征(分类、标签、价格、品牌、导演etc)作为推荐理由;
- 挑选高质量评论:
- 热门推荐「热门指标】排名前【名次】名的【热门物品】」,定期生成榜单
- 协同过滤: 「购买此商品的用户也购买了这些」,「和你口味相似的用户都买了」
- 基于知识: 「由于你【用户的需求或偏好】,所以你可能选择【某物品】」
- 基于内容的推荐理由:
- 方法分类:
- 生成解释的类型: 文本、视觉
- 生成解释的模型: 矩阵分解、主题模型、图模型、deep learning、知识图谱、关联规则、post-hoc models etc
- 例子:
- 基于浅层模型的文本解释: Explicit factor models for explainable recommendation based on phrase-level sentiment analysis.
- 基于深层模型的文本解释: Interpretable Convolutional Neural Networks with Dual Local and Global Attention for Review Rating Prediction
- 基于深层模型的视觉解释: Visually explainable recommendation
- 可解释性和有效性: 这是一对矛盾, 但是现在在深度学习的帮助下, 变得可以同时兼得
不同的解释形式
- 形式
- 个性化文本
- 词云
- 高亮图片的某个区域进行解释
- 生成喜欢该item的社交朋友列表
- 统计直方图、饼图等形式可视化评分分布和item的优缺点
- user-based解释: 推荐给用户的原因是因为与他相似的一组用户对这个item评分很高, 将相似用户的评分可视化(直方图等可视化手段)。由于用户对「相似用户」并不了解,所以这种方法说服力比较有限,如果换成朋友会更有说服力
- item-based解释: 推荐给用户的原因是因为他之前买了某个item。因为用户对购买过的item比较熟悉,这个方法比user-based的方法更有说服力
- content-based解释: 解释原因是因为item的某个feature,比如价格、品牌etc, 而这个feature与用户的某个偏好属性匹配上了。
- 人口统计学解释: 「80%的20-30岁用户都买了这个商品」
- 文本解释:
- feature-level与基于内容的解释相似, 区别是这些feature不是直接从商品的属性中提取的, 而是从用户评论中提取的;
- 评论文本中抽取feature: 短语级别的语义分析工具: feature–opinion–sentiment: Do users rate or review?: Boost phraselevel sentiment labeling with review-level sentiment classification, 通过这种方式, 基于抽取的feature, 以词云的方式可视化这些feature作为解释
- Sentence-level:
- 基于模板+关键词: 「该产品XXXX,你可能会喜欢」,正向和负向的解释都可以提升说服力、转化率etc
- 利用LSTM直接从评论中生成解释文本: Automatic generation of natural language explanations
- 从大量评论中抽取summary,生成解释: Neural rating regression with abstractive tips generation for recommendation
- 视觉解释:
- 将图片中用户感兴趣的部分区域高亮: Visually explainable recommendation
- 社交解释:
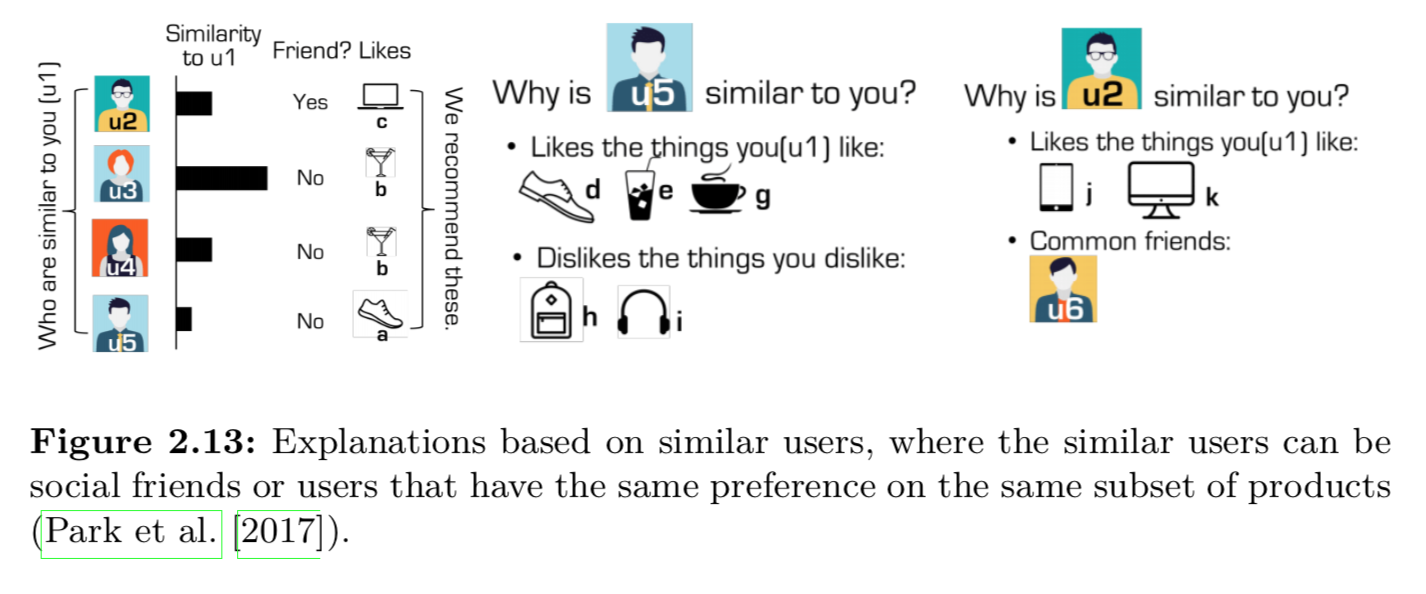
- 混合解释, 输出的一致性
可解释的推荐方法
-
矩阵分解的解释方法: 问题:隐因子缺乏可解释性
- 显式矩阵分解: Zhang et al. [2014a] 基本思想是,在传统的矩阵分解的基础上,假定隐空间的其中一部分维度和显性因子关联,可以通过一个线性变化V从子隐空间变换到显因子空间。用这一部分显因子来做推荐解释。显因子是从大量评论通过文本语义分析提取的、加上商品的属性etc
- 构建 user-item-feature 立方体,利用张量分解来做 Chen et al. [2016]
- 多任务学习:Wang et al. [2018b] 学习两个任务,一个是推荐任务,一个是option建模
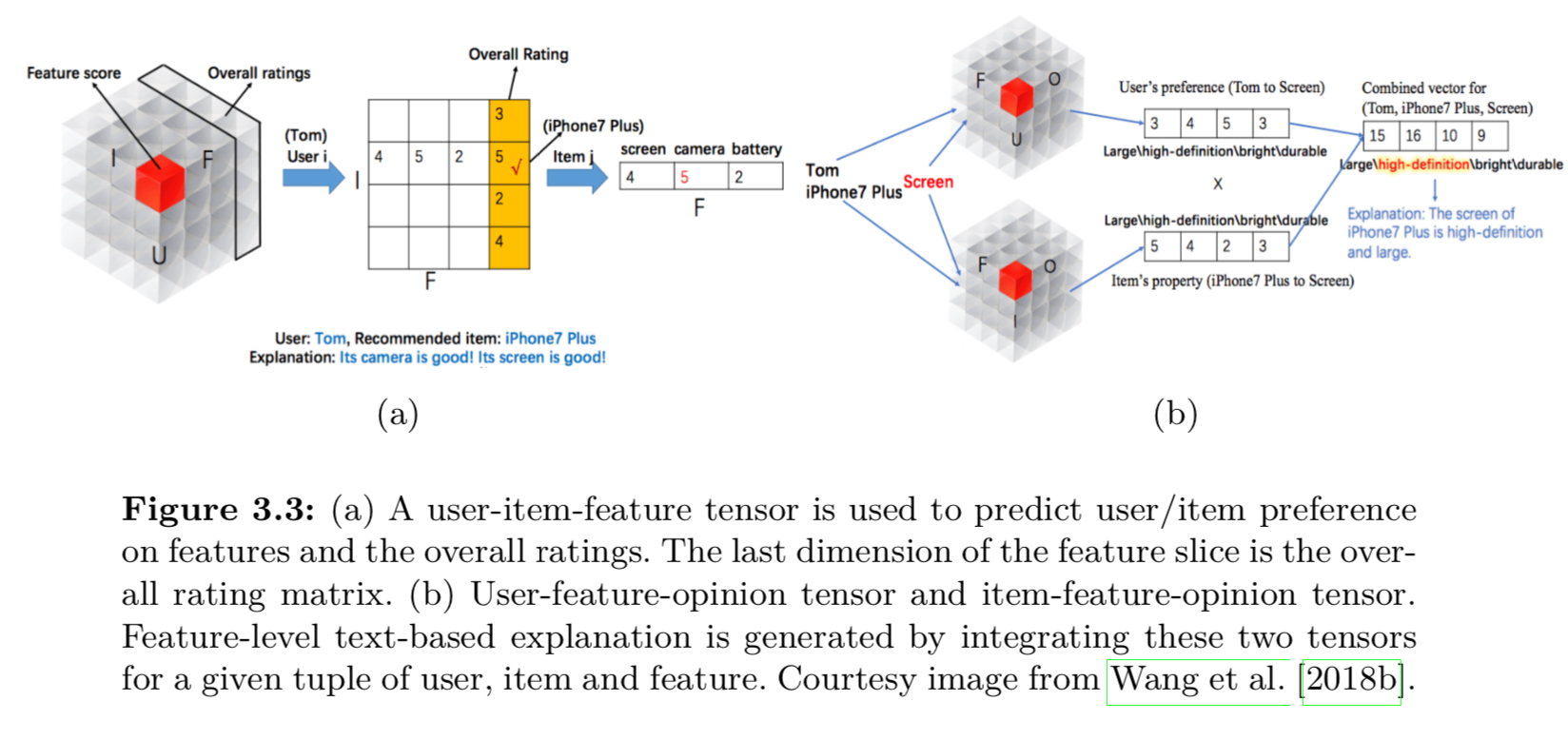
-
【2018-推荐理由】Explainable Recommendation via Multi-Task Learning in Opinionated Text Data
-
主题模型: Hidden Factor and Topic (HFT) model, 将item和user的每个隐向量联系到LDA中的一个主题, 使用了一个softmax函数
-
基于图模型的解释:
- 基于树模型的解释, 利用GBDT提取显式交叉特征, 进行解释
- 深度学习的推荐解释:
- 从用户评论用CNN提取特征,预测评分进行推荐。CNN的时候用了attention加权Pooling,权重可以用于解释关注点
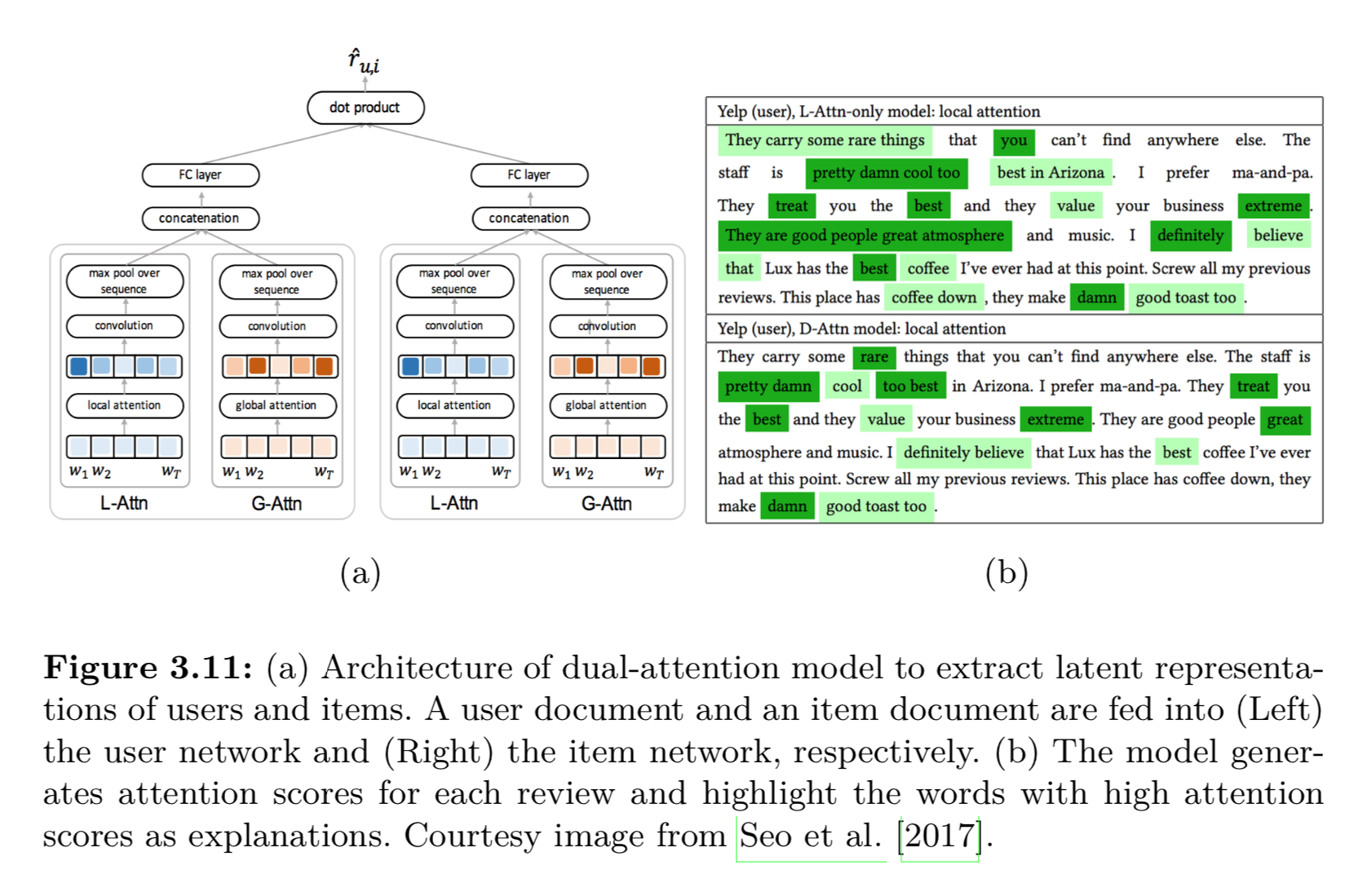
- 生成自然语言的解释: https://zhuanlan.zhihu.com/p/33956907
- 评论+辅助信息自动生成自然语言解释: Automatic Generation of Natural Language Explanations
- KG embedding 推荐的解释:
- Personalized PageRank
- 将推荐看做图谱中「购买」关系下最近的节点
- Rippnet, 推荐解释可以看做在图中找到从user到item的一条路径
- data Mining: 关联规则: 啤酒-尿布解释
- Post Hoc Explanation: 事后解释, 已经推荐了这个item,然后从事先可能的解释中选择一个,这些解释来自于前面说的解释方法
可解释推荐的评估
- 离线评估:
- 评分预测: MAE, RMSE
- top-n推荐: precision@n、recall@n、f1@n、NDCG@n、MRR, DCG中定义正例相关性为1,其他为0,按照位置折扣加权,对前n个求和,对每个用户,用最大的DCG(正例都在负例前面)归一化,然后在所有用户中平均得到NDCG@n
- Hit Ratio, AUC
- 在线评估:
- 点击率、转化率、其他商业指标
- 推荐解释的离线评估:
- explainability precision(EP)定义为推荐的top n 个item中有多少比例可解释
- explainability recall (ER) 定义为推荐的top n中可解释的item占所有可解释的item的比例?
- 生成文本质量: BLEU, ROUGE
- 可读性指标:
- 推荐解释的在线评估:
- 跟一般的推荐评估指标一致, 看点击率、转化率
- 仿真与用户研究,利用众包平台打标,小规模用户调研
- Qualitative Evaluation by Case Study
应用
- 电商推荐
- poi推荐
- 社交推荐
- 多媒体推荐
未来的方向
- 解释深度学习推荐系统
- 基于知识(图谱)增强的可解释推荐
- 多种信息类型的可解释推荐:图片、文本、行为etc
- 解释的自然语言生成NLG:
- 缺乏容易评估解释效果的离线指标
- 解释需要随时间变化,因为用户的行为、偏好、关注点等随时间变化
- 多种解释的聚合: 选最优的 or 聚合所有的
Deep Learning based Recommender System: A Survey and New Perspectives
- DL推荐
- 视频推荐YouTube: Deep neural networks for youtube recommendations.
- Google play: wide&deep
- 新闻推荐Yahoo:Embedding-based News Recommendation for Millions of Users
BiNE: Bipartite Network Embedding
- 将不同实体的二分图(user-item图,只有user和item之间有链接)做embedding
- 作者认为按照node2vec的做法子在全同实体的图可以,但是在不同实体的图不是最优的
- 一个好的embedding方法应该可以根据embedding向量重构原始的图
- 建模显式关系(边)和隐式关系
- 两个节点之间共现的概率建模为内积经sigmoid函数归一化的值
- 用embedding向量表达的共现概率与实际的共现概率之间的差异用KL聚类来度量
$$
P(i, j) = \frac{w_{ij}}{\sum_{ij} w_{ij}} \\
\hat{P}(i, j) = \frac{1}{1 + exp(- u_i^T v_j)} \\
min KL(P, \hat{P}) = - \sum_{ij} w_{ij} log \hat{P}(i,j)
$$
- user-user二阶相似度、item-item二阶相似度
$$
w_{ij}^U = \sum_{k\in V}w_{ik} w_{jk}\\
w_{ij}^V = \sum_{k\in U}w_{ik} w_{jk}
$$
- 而用embedding向量来表达这两个二阶共现概率需要用到softmax,可以利用负采样近似,即对1个样本采样k个其他不共现样本、计算这(k+1)个样本(不)共现概率的乘积
- 最终的目标是联合优化一阶和二阶共现概率