Table of Contents
简介
问题
以电影推荐为例,我们既要预测用户购买电影,也要预测用户对电影的评分。通过对用户推荐其评分高的电影实现长期收益
模型结构
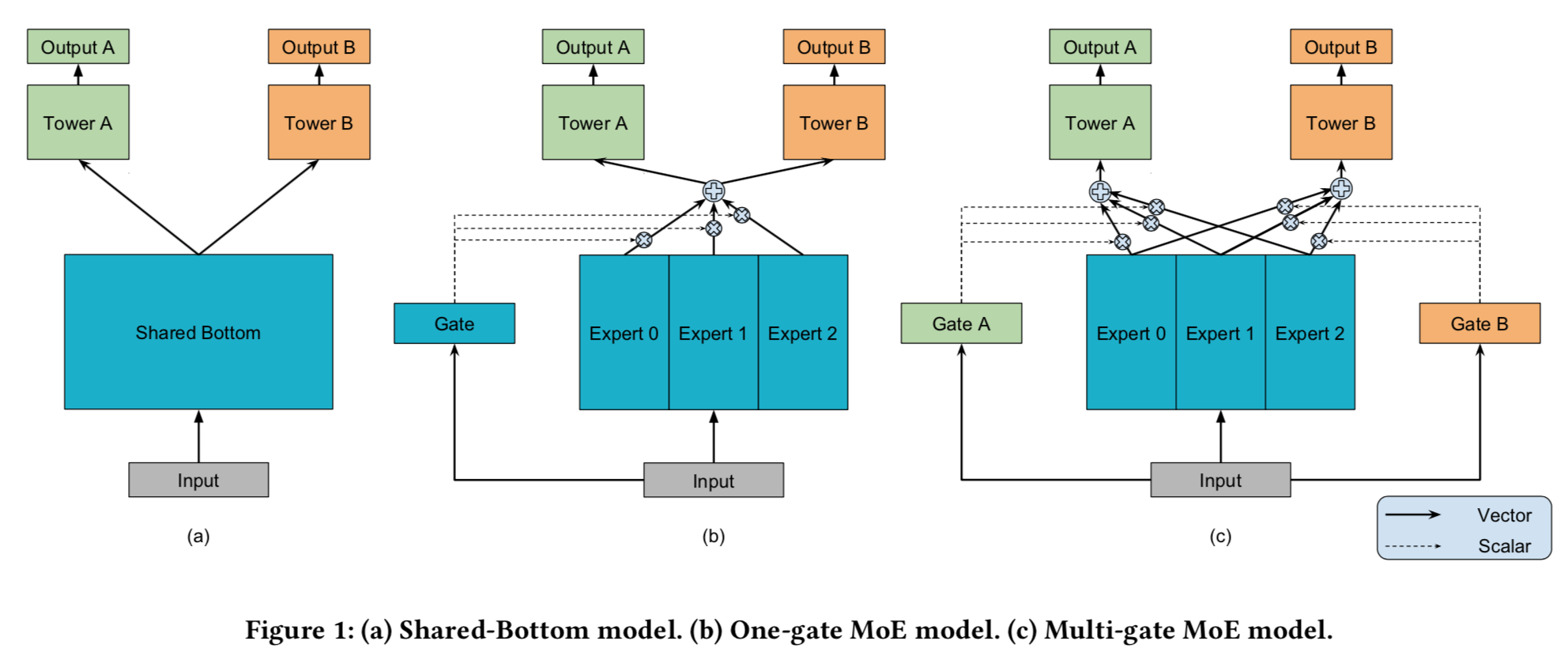
- Shared-Bottom multi-task DNN structure:用相同的部分来处理输入特征得到中间表达,然后再用单独的塔来学习目标任务。
$$
y_k = h^k(f(x)), k=1,2,...
$$ - One-gate MoE:
- Multi-gate MoE:有多个encode(expert)来处理输入,得到多个中间表达;每个任务都有一个gate来对着多个中间表达做加权聚合,得到自己的最终向量表达,然后输入到自己的塔中学习目标任务
合成试验
- 任务:两个回归任务
- 数据生成
- 生成两个正交单位向量u1,u2。
- 给定常数因子c和相关系数p,生成两个权重向量
$$
w_1 = cu_1, w_2=c(pu_1+\sqrt{(1-p^2)}u_2)
$$ - 生成高斯随机向量x作为特征
- 生成两个任务的label,alpha和beta是固定参数,用于函数的形状,epsilon是高斯随机噪声
$$
y_1 = w_1^x + \sum_{i=1}^m sin(\alpha_i w_1^T x + \beta_i) + \epsilon_1 \\
y_2 = w_2^x + \sum_{i=1}^m sin(\alpha_i w_2^T x + \beta_i) + \epsilon_2
$$
- 这种生成方式可以保证w1和w2的余弦是p
Mixture-of-Experts
- The Original Mixture-of-Experts (MoE) Model
$$
y = \sum_{i=1}^n g(x)_i f_i(x)
$$
g 是gate网络,g(x)_i 代表gate网络输出的第i个分量,代表选择第i个专家的概率,g是归一化的,f_i代表第i个专家网络
- MOE很久之前就提出来了,之前用来做模型融合
FAQ
为什么多任务一起学习很多时候不如单任务单独学习的效果
- DNN模型通常对数据非常敏感
- 任务不同的地方数据会互相干扰,尤其是模型共享参数很大的情况下
- 因此,多个任务之间要有较强的关联才会都有提升,提升来自于共同的部分的加强收益超过不同的部分的损失