Table of Contents
- 简介
- FAQ
- 模型的主要思路是什么
- 主要贡献点是什么
- 数据量有多大
- 图是如何构造的
- 节点的特征是如何构造的
- 评估方式有哪些
- 向量的应用
- 文章做了哪些关键事情提升了扩展性
- 为什么卷积的时候要先做一层变换,而不是直接聚合
- 为什么聚合之后还要再来一层变换
- 为什么不降顶点自己的向量在第一层融合的时候就融合进去
- 怎么理解用concat比avg性能提升较大
- 为什么最后还要归一化
- 卷积时的采样是如何进行的
- 每个node的采样权重是如何构造
- Pooling的重要性加权是如何做的
- 卷积的参数有哪些
- 训练的监督信号?
- 训练过程如何
- Producer-consumer minibatch construction是什么
- 负采样的优化
- Curriculum training 是怎么做的
- 为什么naive的方法无法最大限度利用GPU
- 为什么文章的方法可以最大限度利用GPU
- MapReduce推断是如何做的
- naive的方法为什么会有重复计算
- Weak And 是什么
- 试验的对比对象有哪些
- 相比内容的方法,本文的方法多了什么额外的信息
- 计算资源
- 离线评估指标
- 查看随机两个item的余弦相似度分布有什么用
- 图结构和邻居采样是通过什么数据结构实现的
- 代码实现时用到了哪些库
简介
- 本文是GraphSAGE的落地版本
解决的问题
- 解决i2i推荐的问题
- 一个pin有图像,文字。传统的方式就是从图片和文字中抽取特征(VGG16,word2vec),然后计算item的相似度
- 上述的问题:用户会收藏相似的pin到一个board中,这个信息比较有价值,但是上述方法没有利用到
- 本文的解决思路:将pin和board关系表示成一个二分图,将这种收藏关系用图结构来表达,那么只要有个模型能将图结构信息编码到向量中,就能解决这个问题
FAQ
模型的主要思路是什么
- 跟GraphSAGE一样,其中聚合函数取的是Pooling聚合函数。
- 邻居的定义通过随机游走,到达的归一化次数最高的T个顶点
- 损失函数用的是max-margin 损失函数
主要贡献点是什么
- 将GCN扩展到大规模数据集的训练和推断,可落地
数据量有多大
- 节点数目 30亿
- 边数目 180亿
- pins 有20亿
- board 有10亿(相当于pins的收藏夹,里面是人工根据相似的pin收藏到一起的)
图是如何构造的
- 是一个二部图,一个顶点集合I是pins(类似于item、poi),一个顶点集合C是boards(pins的集合,类似于session,用户(可以看做item集合))
节点的特征是如何构造的
- 每一个I中的元素都有一组特征向量
- 在Pinterest中,特征向量从文本和图片中提取
- 3类特征
- 图像embedding特征 4096(VGG-16的第6层全连接层特征向量)
- 文本(标题和描述)embedding特征 256(利用word2vec相关方法学出来的)
- log(node的度)
- 每一个C中的元素呢???没有特征,向量置0?
评估方式有哪些
- 离线评估
- 用一个pin作为触发,召回一批pins,评估hit-rate和mrr
- user study 即人工评测
- 给一个pin的图片代表一个用户,给他用两个策略各推送一个pin,人工打分哪个更好。2/3的用户达成一致才有效。
- 在线AB测试
- 用repin rate来评估,10-30%的提升(相比只用文本和只用图像特征计算相似)
评估任务是:item-item推荐(即i2i推送相似的pin);homefeed任务?
- 给一个用户推荐步骤:找出用户最后一次pin的item,然后在embedding空间查询K个最近邻item,作为推荐的结果
向量的应用
- 利用最近邻做推荐,i2i
- 作为下游推荐模型的特征
文章做了哪些关键事情提升了扩展性
- On-the-fly convolutions:去掉了全拉普拉斯矩阵运算,基于邻居采样来计算即可
- Producer-consumer minibatch construction:producer-consumer 架构构造minibatch训练数据,保证在训练时最大限度地利用GPU
- Efficient MapReduce inference:加速推断效率
为什么卷积的时候要先做一层变换,而不是直接聚合
- 先做一层非线性变换,可以增加模型容量
- 跟正常的卷积类比,也是做一层非线性变换,最后再来一层Pooling操作
为什么聚合之后还要再来一层变换
- 主要目的是为了将顶点自己的向量融合进去
为什么不降顶点自己的向量在第一层融合的时候就融合进去
- 可能是为了强调自己向量,毕竟顶点自己向量比邻居向量包含的信息量更多
- 作者也有提到,用concat比avg性能提升较大,实际上说明加一层效果更好
怎么理解用concat比avg性能提升较大
- concat有参数,有更高的模型容量。数学上来看,前面的权重W多了一倍的参数
- avg相当于相同的权重,学到的权重自然会比拍的权重要好一些
为什么最后还要归一化
- 为了防止梯度爆炸或梯度消失?
- 作者的说法是模型训练稳定
- 在归一化的向量上做KNN更有效率(直接用余弦距离即可)
卷积时的采样是如何进行的
- 不是聚合所有的邻居节点,而只根据权重采样出来的T个节点
- 好处是提高计算性能
- 不好的地方时,实现起来比较麻烦 TODO,看一下如何实现?
每个node的采样权重是如何构造
- 根据对该node的影响程度来加权,具体做法如下:
- 从该node出发,random walk 多次,按照经过的次数
- 当仿真无限次的时候,就相当于 Personal PageRank 算法的结果(从固定的顶点出发)
- 这样做的好处是:
- 固定邻居数目,节省内存
- 将各顶点对该node的权重也考虑进来了
- TODO:试验中,random walk仿真了多少次?
Pooling的重要性加权是如何做的
- 由上述仿真出来的归一化节点权重来加权求和
卷积的参数有哪些
- 两层非线性变换的权重,在node间共享,但是不同层是独立的(跟卷积类似)
训练的监督信号?
- 来自有标注的item对(q, i),即只有正样本,负样本通过负采样得到
- 通过max-margin 的rank-loss
$$
J(z_q, z_i) = E_{n_k \sim P_n(q)} \max{ 0, z_q\cdot z_{n_k} - z_q\cdot z_i + \Delta }
$$
- (q, i) 对构造方法:用户在跟q交互后,又立马跟i交互,那么就构成一个正样本;实际上是就是共现关系
- 总计12亿正样本对;每个batch 500个负样本;每个pin 6 个hard负样本
- 只在图的一个子集(只选择一部分节点构造图)上训练(极大地提升训练速度)
- 20%的board和70%的样本;10%的样本用于调参(验证集);20%的样本用于评估
训练过程如何
- 多GPU卡,通过大batch的方式,每个GPU分一部分,BP算完梯度后,来一次同步SGD
- batch size:512-4096
Producer-consumer minibatch construction是什么
- 正常情况下,在做卷积时需要查询图的邻接表获取邻居节点以及节点的特征,所以会带来GPU和CPU的通信(因为无法将所有顶点特征和邻接表都塞到GPU中)
- 解决方法是,先把这个batch用到的节点构成的子图邻接表和他们的特征抽出来,在这个batch开始的时候一起送到GPU内存,那么在卷积计算的时候就不用查询CPU了
- CPU计算使用OpenMP,CPU计算和GPU计算并行执行,避免等待
负采样的优化
- 每个minibatch,事先采样500个负样本供后续采样,可以加速性能,但是效果上差异不大
- 采样的时候有限采样hard负样本(跟目标node相似的样本,实际上就是相似度加权采样,但又不能把正样本搞进去了)
- 具体做法是利用personal PageRank,得到顶点排序在2000-5000的那些item作为hard负样本
Curriculum training 是怎么做的
- 第一个epoch时不加hard负样本,让模型快速找到一个较小loss的模型,从第二个epoch开始加入hard负样本
为什么naive的方法无法最大限度利用GPU
正常情况下,在做卷积时需要查询图的邻接表获取邻居节点以及节点的特征,所以会带来GPU和CPU的通信(因为无法将所有顶点特征和邻接表都塞到GPU中)
为什么文章的方法可以最大限度利用GPU
先把这个batch用到的节点构成的子图邻接表和他们的特征抽出来,在这个batch开始的时候一起送到GPU内存,那么在卷积计算的时候就不用查询CPU了
MapReduce推断是如何做的
- 简单地说,就是一层一层地算
- 每一层拆分成两步,第一步算pins向量,第二步算boards向量
naive的方法为什么会有重复计算
Weak And 是什么
没搞清楚
试验的对比对象有哪些
- 只用视觉向量
- 只用文本向量
- 视觉+文本向量融合
- 本文的方法
相比内容的方法,本文的方法多了什么额外的信息
- 本文的方法多了图结构信息
- 图结构信息来源于用户的收集行为,人工将相关的pin收集到同一个board中(本质上来说,本文方法的超额收益来源是这部分信息)
计算资源
- 单机32核,16个K80 GPU,内存 500G
离线评估指标
- hit-rate:对每一对pins (q, i),用q作为检索向量,KNN检索K=500个最近邻,如果i在这K个中,则为hit,在test集的所有样本中计算hit平均值。(就是我们之前评估召回效果用的TOP N召回率)
- MRR:对每一对test样本pins (q, i),用q检索得到的i的排序序号$(R_{q,i})$,那么MRR就是序号的倒数。本文做了一个简单的修改,加了个scale因子
$$
MRR = \frac{1}{n} \sum_{(q,i)} \frac{1}{\lceil R_{q,i}/100 \rceil}
$$
查看随机两个item的余弦相似度分布有什么用
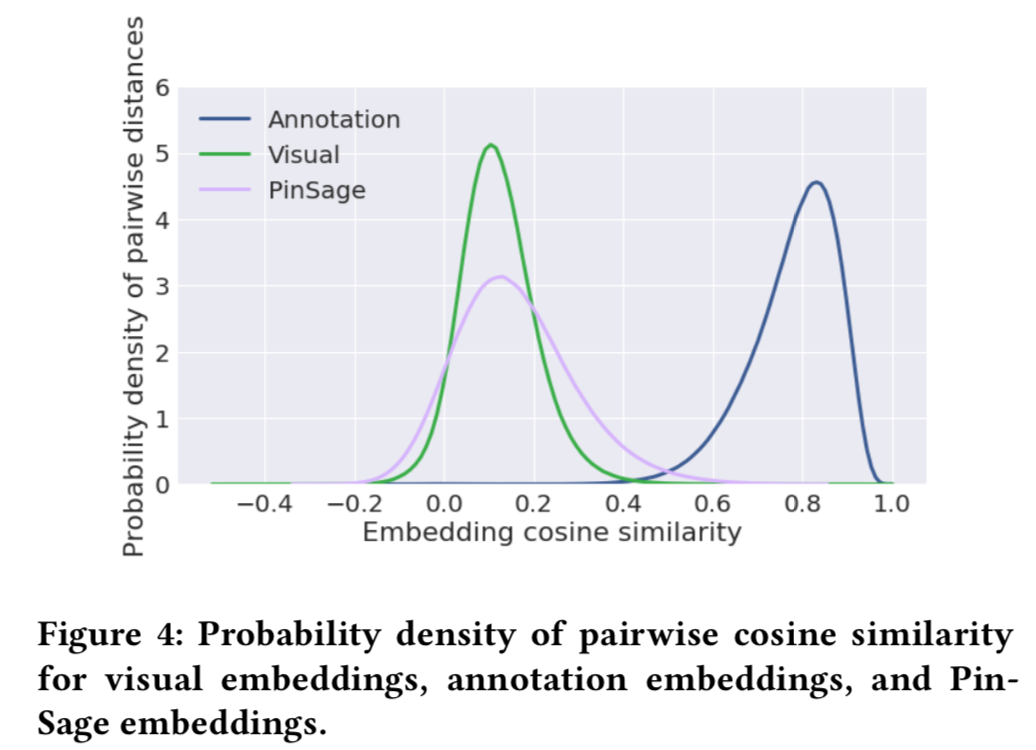
- 可以查看embedding向量学到的是否有一定的区分度,避免全部item的向量距离都很近
- 最近邻检索时也能更加高效
图结构和邻居采样是通过什么数据结构实现的
- 通过邻接表来表示图