Table of Contents
- 主要内容
- FAQ
- 这篇文章解决的问题是什么
- 之前的论文没有研究AMHENs吗?他们都是在研究啥图
- AMHENs有什么实际的困难吗
- 本文方法的关键点是什么
- 文中说的transductive learning 跟 inductive learning分别是什么?
- 论文中模型离线评估的F1值是怎么算的
- 其它可以扩展到新节点的方法有哪些
- 本文中的问题的数学表示是
- GATNE-T 的基本结构是什么
- GATNE-T 中每个顶点的初始边向量是怎么来的
- GATNE-T 第k次聚合是否只利用到k-1次聚合的结果
- GATNE-T 对多个关系是如何处理的
- 为什么GATNE-T中,u明明是跟顶点强绑定的,对邻居节点的聚合和多个关系的聚合被表示为边的表达
- GATNE-T 对顶点属性是如何利用的
- GATNE-I 是如何处理属性的
- GATNE-I 是如何实现对新的节点的也能推理的
- 模型是如何训练的,监督信号是啥
- 分布式训练是如何做的
- 为什么顶点向量维度比边向量维度高一个量级
- meta-path的采样在工程上是如何实现的
- 邻居聚合在训练和推断的时候是如何实现的
- 文章的结果是否拿到线上效果
- 这篇文章的前序文章有哪些值得看的
- 代码在哪
主要内容
模型
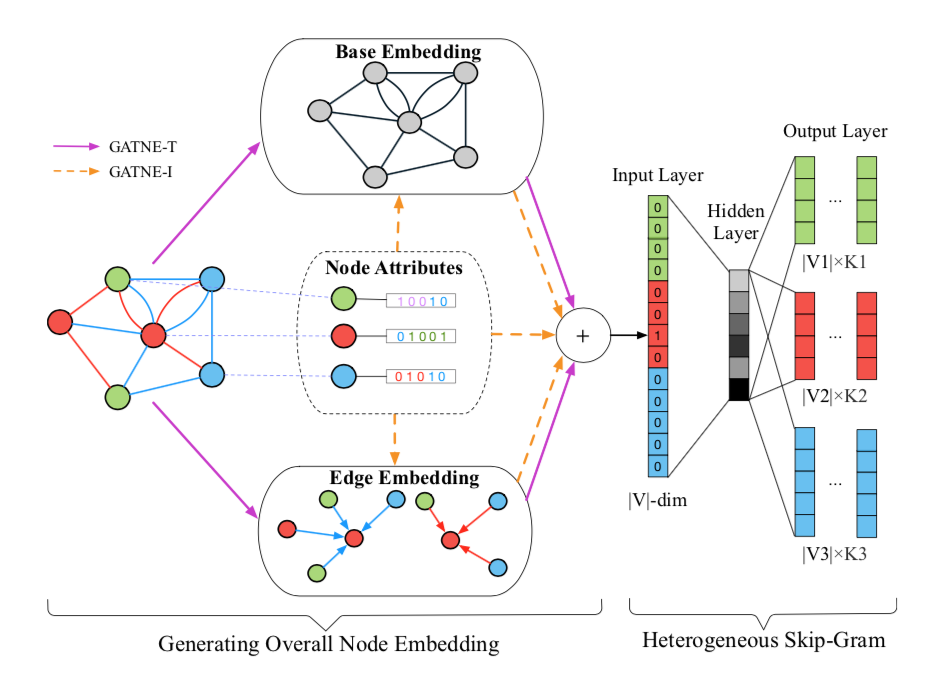
Transductive Model: GATNE-T
- 每个定点的向量是其一阶邻居向量的某种聚合操作(均值、attention etc)
- 可以存在多次聚合,就能扩展到邻居的邻居来表示该节点
FAQ
这篇文章解决的问题是什么
- AMHENs网络的表达学习
- AMHENs网络是指:不同类型的顶点会有不同类型的边;每个顶点关联一组不同的属性。
- 举例来说:在电商领域,user跟item的关系有
- 点过
- 买过
- 加购物车
- 加收藏
之前的论文没有研究AMHENs吗?他们都是在研究啥图
- deepwalk,node2vec,同质图,只有一种顶点,一种关系,没有属性
- metapath2vec,异构图,有多种顶点,多种关系(两个顶点之间只有一种关系),没有属性
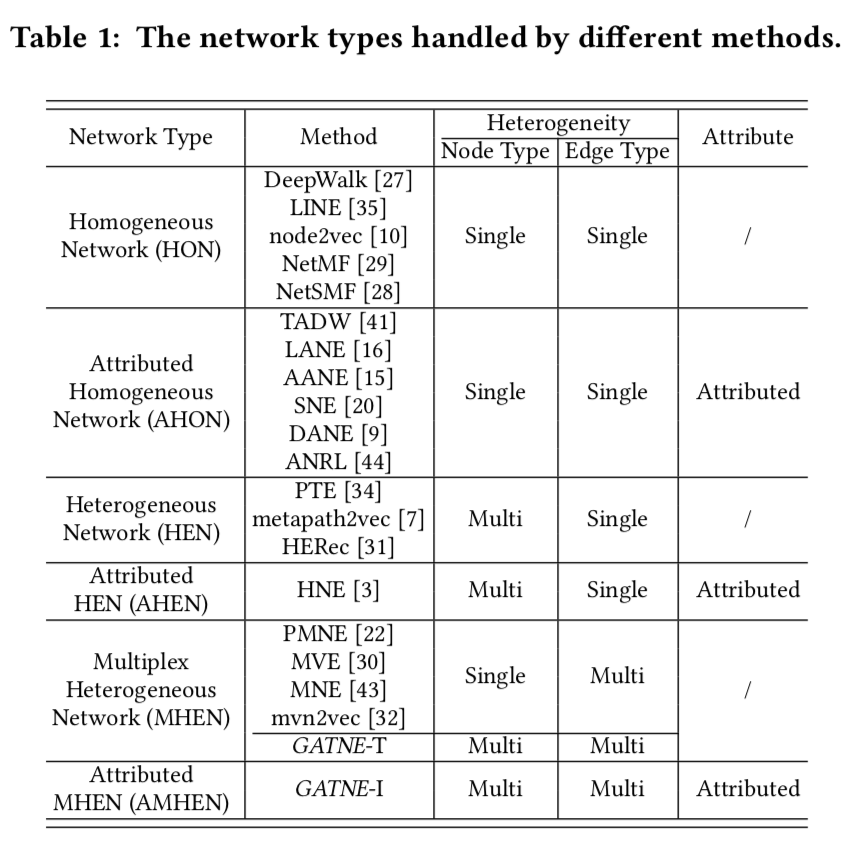
AMHENs有什么实际的困难吗
- 多个边,两个节点见有多种关系,也就有多个边。每种关系的对刻画节点关系的重要程度不一样(例如下单跟点击)
- 部分观测,大部分user跟item之间没有曝光过,所以就没法获得用户跟item的一些关系,所能拿到的数据都只是观测到的一部分数据。大多已存在的方法无法处理长尾和冷启动问题
- 可扩展性,数据规模大,节点是10亿量级,边是百亿甚至千亿量级
本文方法的关键点是什么
- 方法:General Attributed Multiplex HeTerogeneous Network Embedding (GATNE)
- 关键技术:
文中说的transductive learning 跟 inductive learning分别是什么?
- 说的是否能泛化到新的顶点上(例如新用户和新的商品)
论文中模型离线评估的F1值是怎么算的
- 在原始的数据中,构造了一个链接预测任务
- 随机选取了5%/10%的正样本,以及相同数目的负样本
- 假设已经知道正样本数目,(相当于将P调到跟R一样),避免卡不同阈值带来的差异
- 多个类型的边的结果单独计算,然后平均
其它可以扩展到新节点的方法有哪些
- GraphSAGE,Inductive Representation Learning on Large Graphs
- 基本想法是利用节点的特征来表达节点,学出表示函数的参数,而不是直接对节点做embedding
本文中的问题的数学表示是
- 对每一个顶点v,在不同的关系r下,存在一个embedding向量 $(v^r)$。本文是对每种关系r学习一个带参映射函数$(f_{\theta_r})$
GATNE-T 的基本结构是什么
- 第一层是一个多层的图传播聚合层,用于学习图的结构信息
- 第二层是一个self-attention层,因为每个定点都有r个向量,(每一种关系有一个向量),self-attention用于将这r个向量做聚合,聚合结果还是r个向量,但是每个向量可以学到其他关系中的一些信息
GATNE-T 中每个顶点的初始边向量是怎么来的
- 初始向量即$(u_{i, r}^0)$ 是随机初始化来的,类似于node2vec这种;所以这个可以看做多层图传播算子(聚合操作)
GATNE-T 第k次聚合是否只利用到k-1次聚合的结果
- 是的,第k词聚合的输入是k-1次聚合的所有定点向量
GATNE-T 对多个关系是如何处理的
- 最终输出的r个向量,每个向量都是聚合了多个关系中的顶点向量$(U_i)$的结果,所以在一定程度上,每个向量都包含了所有关系的信息。
- 另一方面,聚合的时候采用的是self-attention机制$(a_{i,r})$,所以可以只将其他关系学到的信息中跟当前关系有关的部分抽取进来(当然,这只是一种强行解释,只是说存在这样一种可能性;而如果没有这个结构就不存在这种可能性)
- 在聚合后,还做了一个线性变换,变换系数$(M_r)$跟关系关联;此外,还加了一个base embedding向量$(b_i)$,可以理解为基线模型。
$$
v_{i,r} = b_i + \alpha_r M_r^T U_i a_{i,r}
$$
说明:$(\alpha_r)$ 是一个超参数
为什么GATNE-T中,u明明是跟顶点强绑定的,对邻居节点的聚合和多个关系的聚合被表示为边的表达
因为,邻居的信息都是通过边来起作用的,而边的表示本质上是要将边的类型信息和对面的节点信息表示出来。
在模型中,边的类型信息通过attention矩阵和几个线性变换矩阵表示了出来(不同类型矩阵参数不一样)。而对面节点的信息通过聚合直接加了了进来。
虽然u跟顶点强绑定,但是u表示的是定点的边所表达的信息,所以还是叫边向量
GATNE-T 对顶点属性是如何利用的
GATNE-T 不使用顶点的属性,GATNE-I会使用;因此GATNE-T无法处理训练时没有出现过的顶点(如新的用户和新的item)
GATNE-I 是如何处理属性的
- 对每个顶点$(v_i)$有一个将顶点的特征向量 $(x_i)$ 映射到一个隐向量的函数 $(b_i = h_z(x_i))$ z是代表顶点的类型,每个类型对应的映射函数都是不一样的。
- 不一样的原因是,每种类型的属性特征维度和意义都不太一样,所以需要多个函数更好。类似于双塔模型的用户塔和item塔
- 另一方面,在GATNE-T中,还存在一个跟顶点强绑定的参数,即初始向量$(u_{i, r}^0)$,也都可以表示成顶点属性的函数。
- 此外,由于b和u都是对输入特征的高阶变换,所以作者还加了一个对输入特征的线性项。最终的结果是
$$
v_{i,r} = h_z(x_i) + \alpha_r M_r^T U_i a_{i,r} + \beta_r D_z^T x_i
$$
这里r代表边的类别,z代表顶点的类别
GATNE-I 是如何实现对新的节点的也能推理的
- 它没有直接用节点id来embedding,而是使用节点的特征来学embedding,类似于双塔模型与FM的区别
模型是如何训练的,监督信号是啥
- 在图中做meta-path-based random walks,然后利用负采样损失函数来做的,负采样只在特定类型的顶点集合中采样
分布式训练是如何做的
- 文章中没有提到
为什么顶点向量维度比边向量维度高一个量级
meta-path的采样在工程上是如何实现的
- 利用python包
networkx - https://github.com/THUDM/GATNE/blob/master/src/walk.py
邻居聚合在训练和推断的时候是如何实现的
- 通过邻接表数据结构来实现的
文章的结果是否拿到线上效果
- 只有离线的AB测试效果,没有线上效果
这篇文章的前序文章有哪些值得看的
- DeepWalk
- LINE
- NetSMF/NetMF
- GraphSAGE
- HNE
- PTE
- metapath2vec
- HERec
- etc