关于
论文:Deep Forest: Towards An Alternative to Deep Neural Networks,南大周志华
gcforest
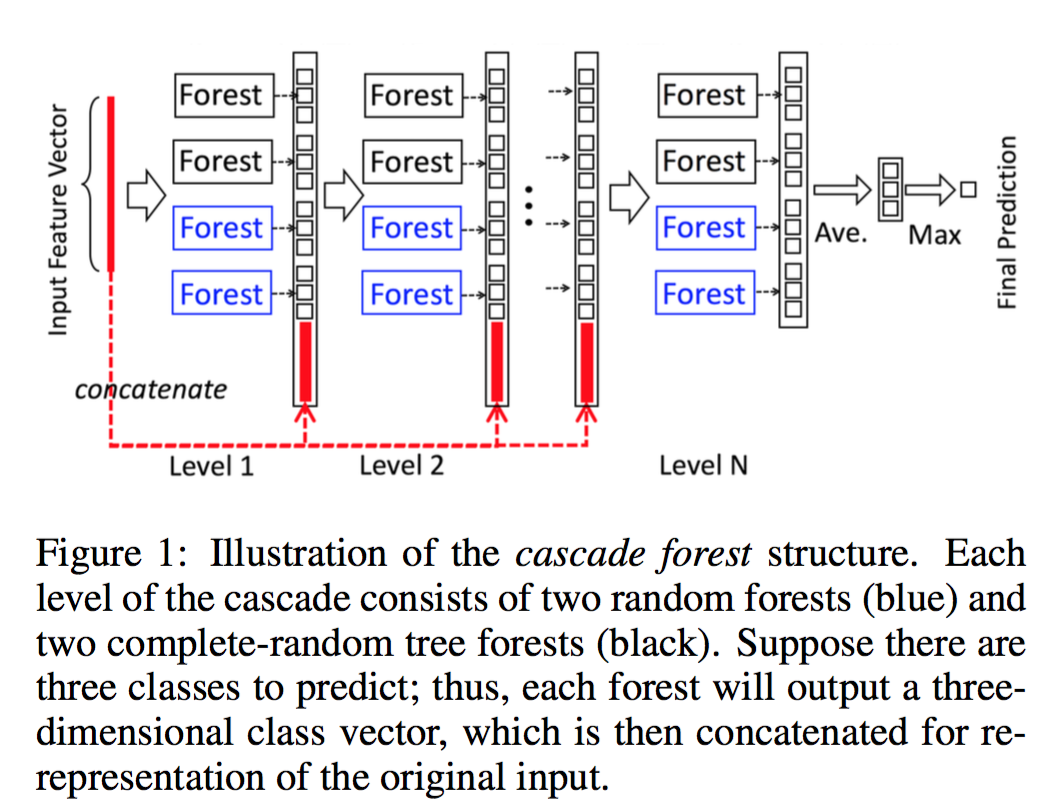
Cascade Forest
gcforest由多层构成,每一层是多个决策树森林的集成。
我们用两个完全随机树森林和两个随机森林,利用不同类型的树来增加集成的多样性,
因为集成学习中的多样性是至关重要的。
- 完全随机树森林:1000个完全随机树构成。
- 完全随机树:树的每一个节点随机选择一个特征进行分裂,生长树直到每个叶子结点只有一类或者样本量不多于10个。
- 随机森林:1000个决策树,每棵树都是随机选择 $(\sqrt{d})$ 个特征,选择 gini 增益最大的进行分裂。
对每一个样本,每个森林将输出其在每个类的概率分布向量(通过平均每棵树的概率分布向量得到,每棵树是通过统计该叶子结点上的分布得到)。
将所有森林输出的分布向量链接成一个大的向量(augmented features ),并和原始向量拼接到一起后输入下一级继续学习!
为了避免过拟合,类向量通过k-fold交叉验证产生的,将每个样本作为训练集的 k-1 次结果平均!
每一层训练结束后,将在验证集上计算score,如果score没有明显增加,那么训练流程将会停止!
也就是说层数是训练过程中确定的。
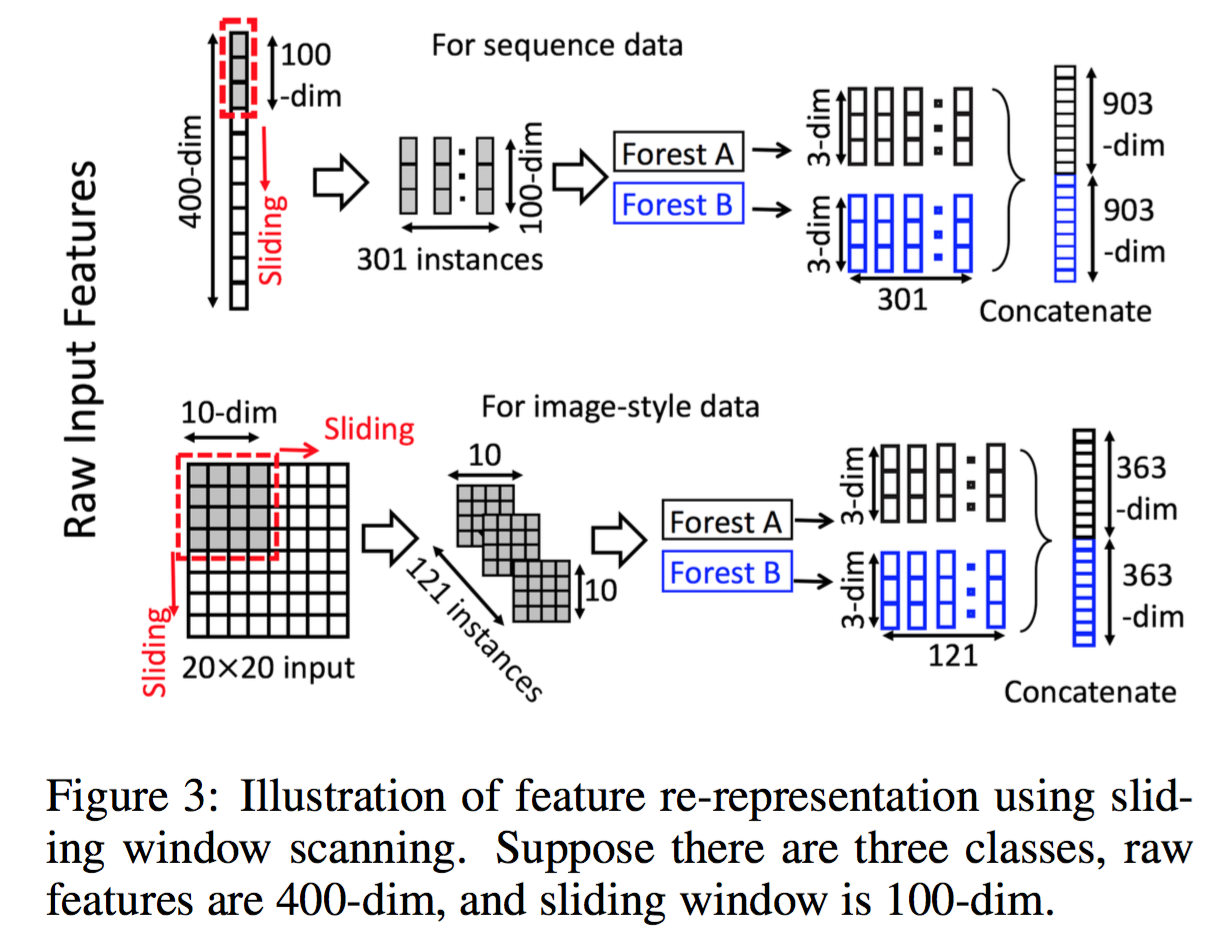
Multi-Grained Scanning
对于序列数据、图像数据等,借鉴了卷积的思想,利用滑动窗将一个样本变成多个样本,提取特征!
将一个样本变成多个小尺寸的样本,这个跟多示例学习中的 bag generate一致 [Wei and Zhou, 2016]。
然后把每个小尺寸样本预测出来的类向量拼接到一起变成一个大的向量,作为原始样本的组合输出特征,叠加到下一层。
可以采用多个滑动窗,从而获取跟多不同尺寸的特征,类似于小波分析。这些扫描后的特征作为 Cascade Forest 的输入特征,进行学习。
- X.-S. Wei and Z.-H. Zhou. An em- pirical study on image bag generators for multi-instance learning. Machine Learning, 105(2):155–198, 2016.
试验结果
试验配置,gcforest都是用基本相同的配置。具体结果参看原始论文,这里列举一些结论。
- gcforest 在所有的试验都显示出强大的建模能力,尤其是在小数据集上的效果,在IMDB情感分类这样级别的数据集也和目前最好的CNN效果略优。
- Multi-Grained Scanning 对图像数据和序列数据非常必要,对最终效果影响特别明显,在GTZAN和sEMG数据及上效果相差10个点!
- 运行速度快,都采用 CPU 版本时,gcforest大约只需要 MLP 的 1/4 时间,接近 GPU 版本的 MLP
- 更大规模的数据集的效果和 CNN 的对比尚有待研究,例如和 res150 对比?!
Ref
F. T. Liu, K. M. Ting, Y. Yu, and Z.-H. Zhou. Spectrum of variable-random trees. Journal of Ar- tificial Intelligence Research, 32:355–384, 2008.