关于
fast text 开源工具见https://github.com/facebookresearch/fastText。
主要涉及的两篇文章是:
- P. Bojanowski, E. Grave*, A. Joulin, T. Mikolov, Enriching Word Vectors with Subword Information
- A. Joulin, E. Grave, P. Bojanowski, T. Mikolov, Bag of Tricks for Efficient Text Classification
论文导读
Enriching Word Vectors with Subword Information
摘要
论文的基本思想:由于之前的词向量方法都是以词为单位进行学习,而通常一个词的有很多不同的形态!(不能用stem将形态标准化么?)
为此,作者提出一种基于skip-gram结构的新方法,词被表达为多个 n-gram 字母的bag。
对每一个n-gram学习一个向量,而词向量用这些n-gram的向量求和得到。
这种方法非常快!作者在5种不同的语言中训练词向量,评估了在word similarity and analogy
tasks上的效果!
导言
subword 模型
在skip-gram模型中,两个词之间相似度用两个词词向量的内基表示$(score = s(w,c) = w^T c)$。
这个模型将一个词的n-gram g单独赋予一个向量$(z_g)$,而词向量用该词所有的n-gram向量之和来表示。
不同词之间,共享n-gram向量!那么$(s(w,c) = \sum z_g^T v_c )$。
词本身也加到了n-gram集合中,并且 词向量和n-gram向量不同,比如as作为单词和作为paste的n-gram是不共享向量的!
n-gram 词典的设计,论文只保留了长度为3-6的n-gram。为开始位置和结束位置添加特殊字符,用以区分前缀和后缀。
限制内存:将n-gram hash 到 1 to K,论文中K取200W!
效率提升:最最常出现的P个单词,不使用n-gram!
结论
对 rare words, morphologically rich languages and small training datasets 提升明显。
实现性能比skip-gram baseline 慢1.5倍。105k words/second/thread VS 145k words/second/thread for the baseline。
Bag of Tricks for Efficient Text Classification
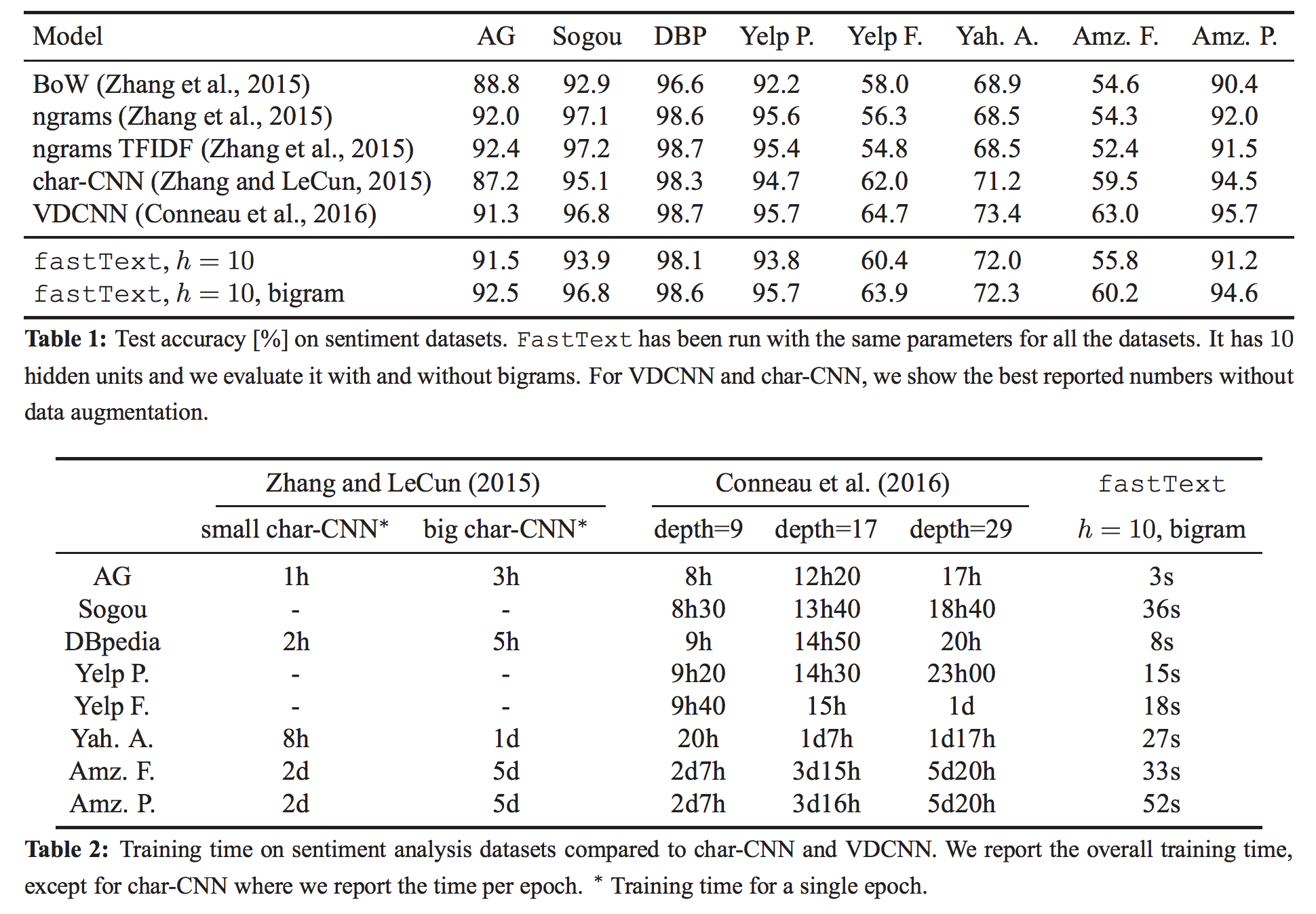
论文:Bag of Tricks for Efficient Text Classification, Armand Joulin, Edouard Grave, Piotr Bojanowski, Tomas Mikolov
fastText 在多核CPU上,训练超过10亿的单词,不到10分钟!
分类50W句子,312K个类别,只需要不到1分钟!
现有的神经网络建模句子的表达,速度慢:
- [Bengio et al.2003]
- Ronan Collobert and Jason
Weston. 2008. A unified architecture for natural language
processing: Deep neural networks with multitask
learning. In ICML.
线性模型建模,速度快: (Mikolov et al., 2013; Levy et al., 2015).
通过加入n-gram 信息,可以将线性模型的性能提高到和深度模型接近,但是速度快几个量级!
模型结构
baseline:将句子表达为bag of word,然后训练一个线性模型 LR or linearSVM。
线性模型不能共享权值,导致泛化能力不强。
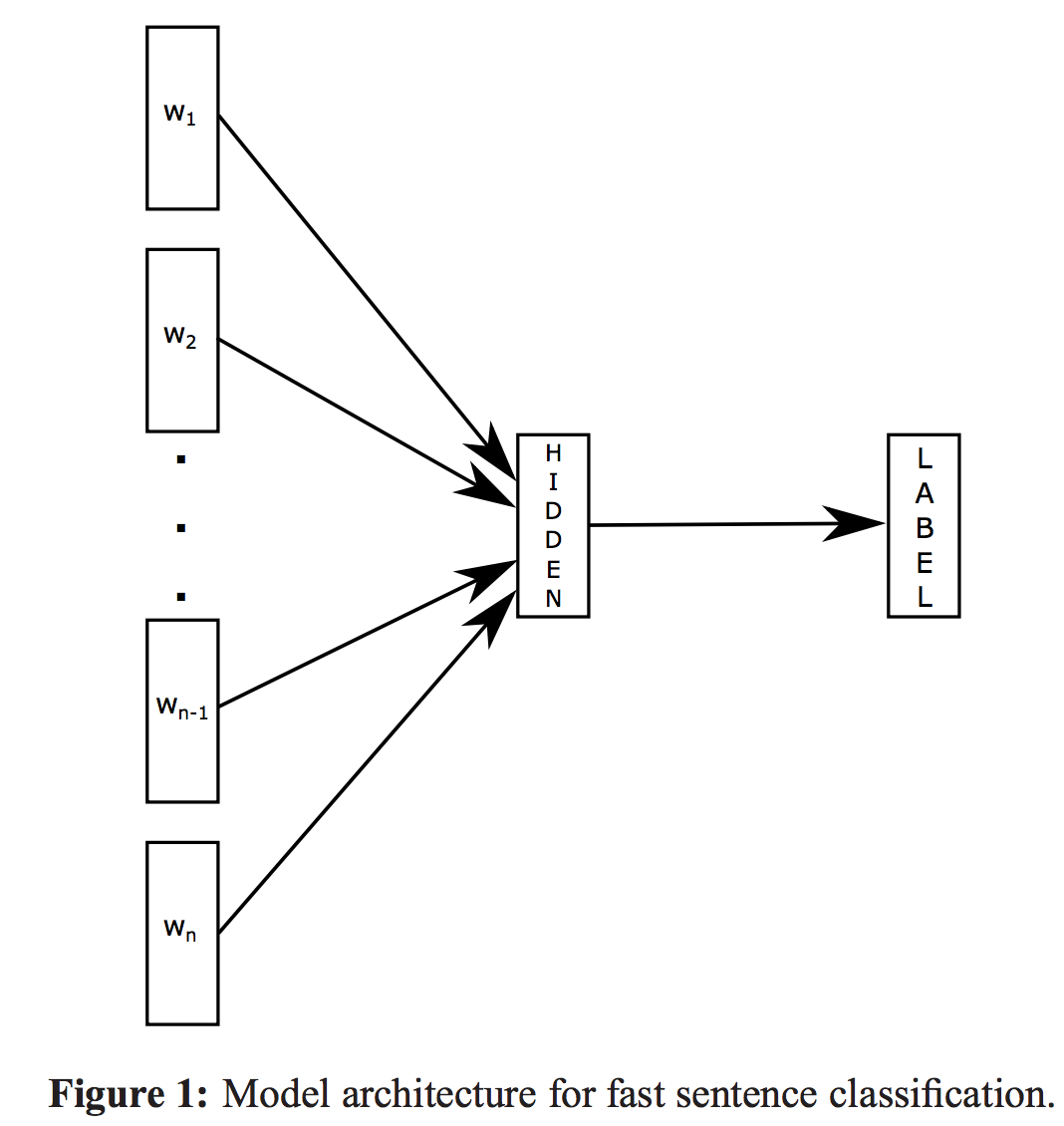
Hierarchical softmax 优化,略
N-gram features:n-gram 特征加入会极大影响速度,采用 hash trick解决!
trick方案论文:Strategies for training large scale neural network language
models.