关于
深度学习在语音识别中的应用。参考文献
- Hinton G E, Deng L, Yu D, et al. Deep Neural Networks for Acoustic Modeling in Speech Recognition[J]. IEEE Signal Processing Magazine, 2012, 29(6).
语音识别现状
- GMM-HMM
- GMM 表达 HMM 态之间的关系;
- 输入的表达:MFCC(Mel-frequency cepstral coefficients),PLPs(perceptual linear predictive coefficients);
以及一阶和二阶时域差分;
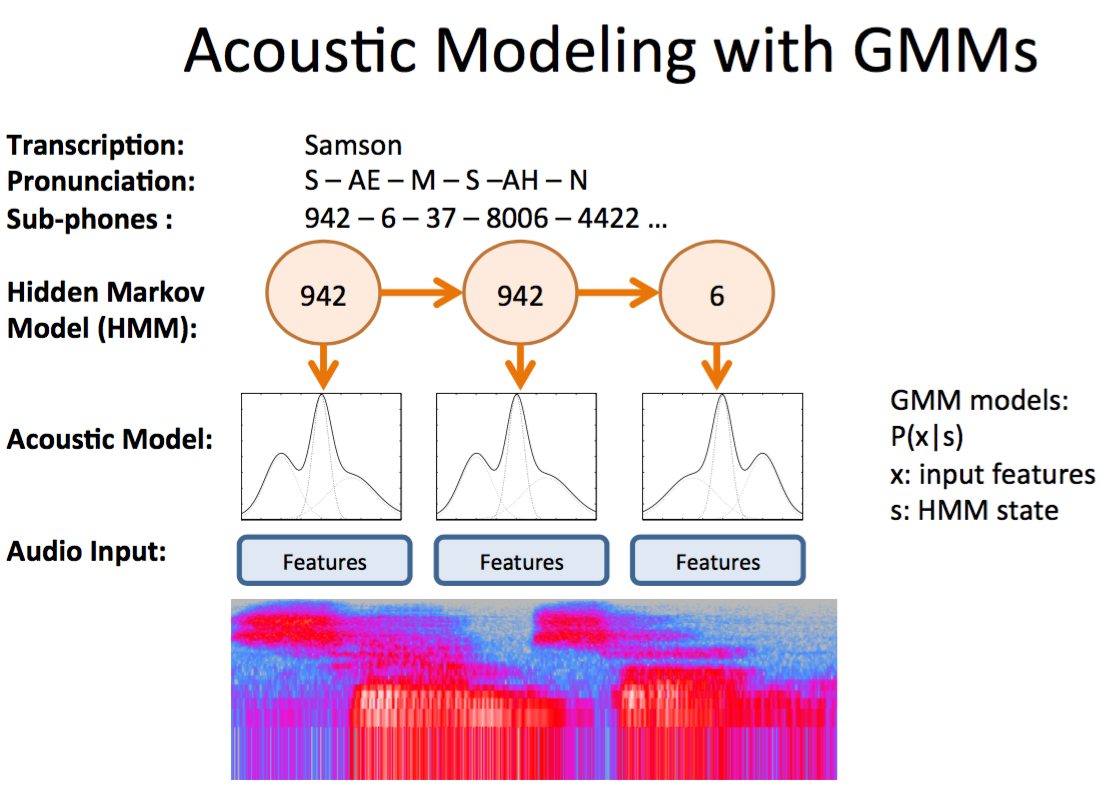
- 每一个音节(?)用一个态 s 表示,输入特征 x 到态s的建模 $(P(x | s))$ 采用高斯混合模型 GMM,这是一个生成模型。(利用EM算法,很容易拟合数据)
- 用隐马尔科夫模型建模态转移
- DNN 替换 GMM:GMM不能很好的建模低维非线性流形。DNN直接建模条件概率 $(P (s | x))$,然后通过贝叶斯法则得到 $(P(x|s) = P(s|x) * P(x) / P(s))。态的标注通过基本的 HMM-GMM 得到?
-
TIMIT database; LVCSR
-
逐层的训练 RBM,第一层隐层保持二进制(硬判决的noise可以作为正则防止过拟合),其他层隐层都用实值的概率值。
- 实值数据(MFCC)建模:高斯贝努力 RBM(Gaussian–Bernoulli RBM (GRBM)),能量函数为:
$$
E(v, h) = \sum_{i \in vis} \frac{(v_i - a_i)^2}{2 \sigma_i^2} - \sum_{j \in hid} b_j h_j - \sum_{i,j} \frac{v_i}{\sigma_i} h_j w_{ij}
$$
两个条件分布为:
$$
p(h_j|v) = \text{logistic}(b_j + \sum_i \frac{v_i}{\sigma_i} w_{ij}) \\
p(v_i|h) = \mathcal{N}(a_i + \sigma_i \sum_j h_j w_{ij}; \sigma_i^2)
$$