关于
卷积网络经典文章导读,文章列表是参考 CS231N 课程。
AlexNet
论文:Imagenet classification with deep convolutional neural networks
Alex Krizhevsky, Ilya Sutskever, Geoffrey E Hinton, 2012
Hinton 带学生打比赛的故事。
- 求解问题: ImageNet LSVRC-2010 比赛,1.2M高精度图片,1000分类!ILSVRC-2012 TOP5 error:15.3%,第二名是 26.2%!
- 效果: TOP1 error:37.5%, TOP2 error:17.0%。
- 网络参数:60M 参数,650,000个神经元
- 重要创新: ReLU激活函数, GPU计算卷积,dropout
- 5层卷积层+3层全连接层,卷积层的深度是很关键的,移除任何一层都将导致性能的降低!
- GTX 580 3GB GPUs 训练 5-6天
Amazon’s Mechanical Turk crowd-sourcing tool
- 对图像做下采样到固定大小 256x256,满足固定大小输入;对每个像素减去在整个训练集上的均值
结构上的创新
- ReLU 非线性:加速训练,CIFAR-10上达到25%错误率,比tanh快6倍!
相关论文:V. Nair and G. E. Hinton. Rectified linear units improve restricted boltzmann machines. In Proc. 27th International Conference on Machine Learning, 2010
- 多 GPU 训练:2个GPU
- Local Response Normalization:将错误减少1-2个点。
- Overlapping Pooling:Pooling尺寸=3,步长却是2
- 结构:前面五层是卷积层,每个卷积层分为两个部分,每个部分放在一个GPU中,在卷积过程中,第2、4、5层的两个GPU互不干扰,第3层和全连接层又相互交错连接的部分。maxpooling层在第1,2,5层卷积层,Local Response Normalization layer 在第1、2层。
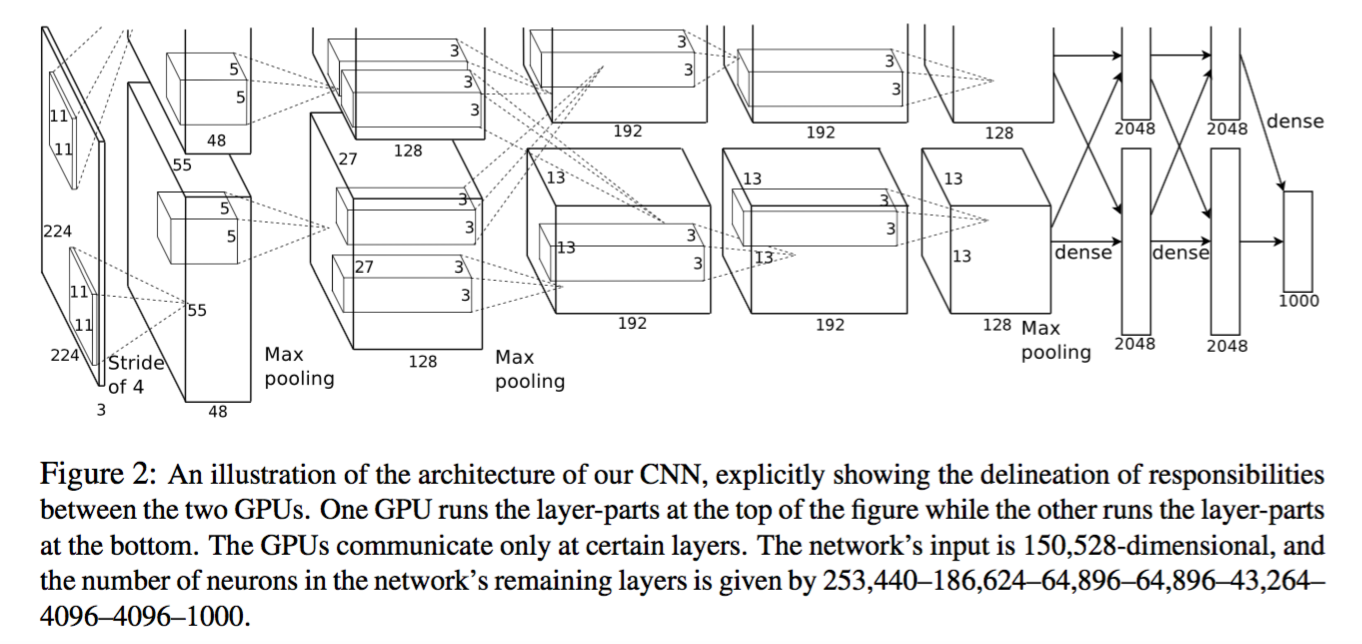
- 每一层的详细参数:输入 224x224x3
- 96个11x11x3的滤波器,分为上下两部分,每部分48个
- 256个5x5x48的滤波器,两个GPU互不干扰
- 384个3x3x256的滤波器,两个GPU有交互
- 384个3x3x192的滤波器,两个GPU互不干扰
- 256个3x3x192的滤波器
- 全连接层为4096个神经元
- 卷积层参数:1.45M,卷积层输出为6x6x256;三个全连接层分别是:37.75M,21.92M,4.10M!!可以看到参数主要集中在卷积层最近的两个全连接层!!
降低过拟合技巧
- Data Augmentation: 数据增强:
- 平移和水平翻转,从256x256的图片,截取224x224的图片块,加上水平翻转,一张图片就变成了32x32x2=2048个样本!预测的时候;预测的时候,截取四个角+中央以及他们的水平翻转10张图片,结果取平均!
- 加噪,有点像 denoise 的概念,对每一个像素 $(I_{xy} = [I_{xy}^R, I_{xy}^G, I_{xy}^B]^T)$,不是简单的在每个分量上简单地叠加,而是在三个通道的协方差矩阵的三个主方向上,叠加对应比例的噪声。下式中,p与lambda分别是协方差矩阵的三个特征向量和特征值,$(\alpha_i)$ 是叠加的噪声比例,服从0均值方差为0.1的高斯分布。
$$
[\mathbf{p}_1, \mathbf{p}_2, \mathbf{p}_3] [\alpha_1 \lambda_1, \alpha_2 \lambda_2, \alpha_3 \lambda_3]^T
$$
-
Dropout:可以看做一种大量的神经网络的模型组合。可以解决过拟合问题,学习到鲁邦的特征,预测的时候,则将神经元的值乘以概率即可。 dropout 技术大致使得收敛的迭代次数增加一倍。
-
配置:NVIDIA GTX 580 3GB GPUs,两块
量化评估
用最后的4096维特征作为图像向量,评估图像的相似度,效果很不错,用 auto-encoder 于这些特征上比在raw data上效果应该会更好。

ZFNet
论文:Zeiler M D, Fergus R. Visualizing and Understanding Convolutional Networks[C]. european conference on computer vision, 2013: 818-833.
- ZFNet 在 AlexNet 上改进的不多,主要贡献在 CNN 的可视化。
- 解释 AlexNet 为什么效果好(主要是通过可视化分析),以及怎么进一步改进。
- 数据集:Caltech-101,Caltech-256.
- 可视化技术:解卷积,通过显示激活任意一层的单一的 feature map 的输入图像的方法,可视化某个神经元学到的东西。 Zeiler, M., Taylor, G., Fergus, R.: Adaptive deconvolutional networks for mid and high level feature learning. In: ICCV (2011)
- 敏感性分析:通过遮蔽输入图片的一部分,展示图片的哪一部分对分类结果比较重要。
- 对 AlexNet 改进,并迁移到其他任务,只将最后一层 softmax 重新训练,有监督的 pre-training。
- 之前的可视化工作一直停留在第一层。
- 通过梯度下降最大化某个神经元的输出,从而找出最优激励图像(BP to Image)Dumitru Erhan, Yoshua Bengio, Aaron Courville, and Pascal Vincent,Visualizing higher-layer features of a deep network,2009,没有解释神经元的不变性!?
- 计算在最优点处的 Hessian 矩阵,理解这种不变性?
- 解卷积是无监督学习,相当于一个探针,探测一个已经学好的网络
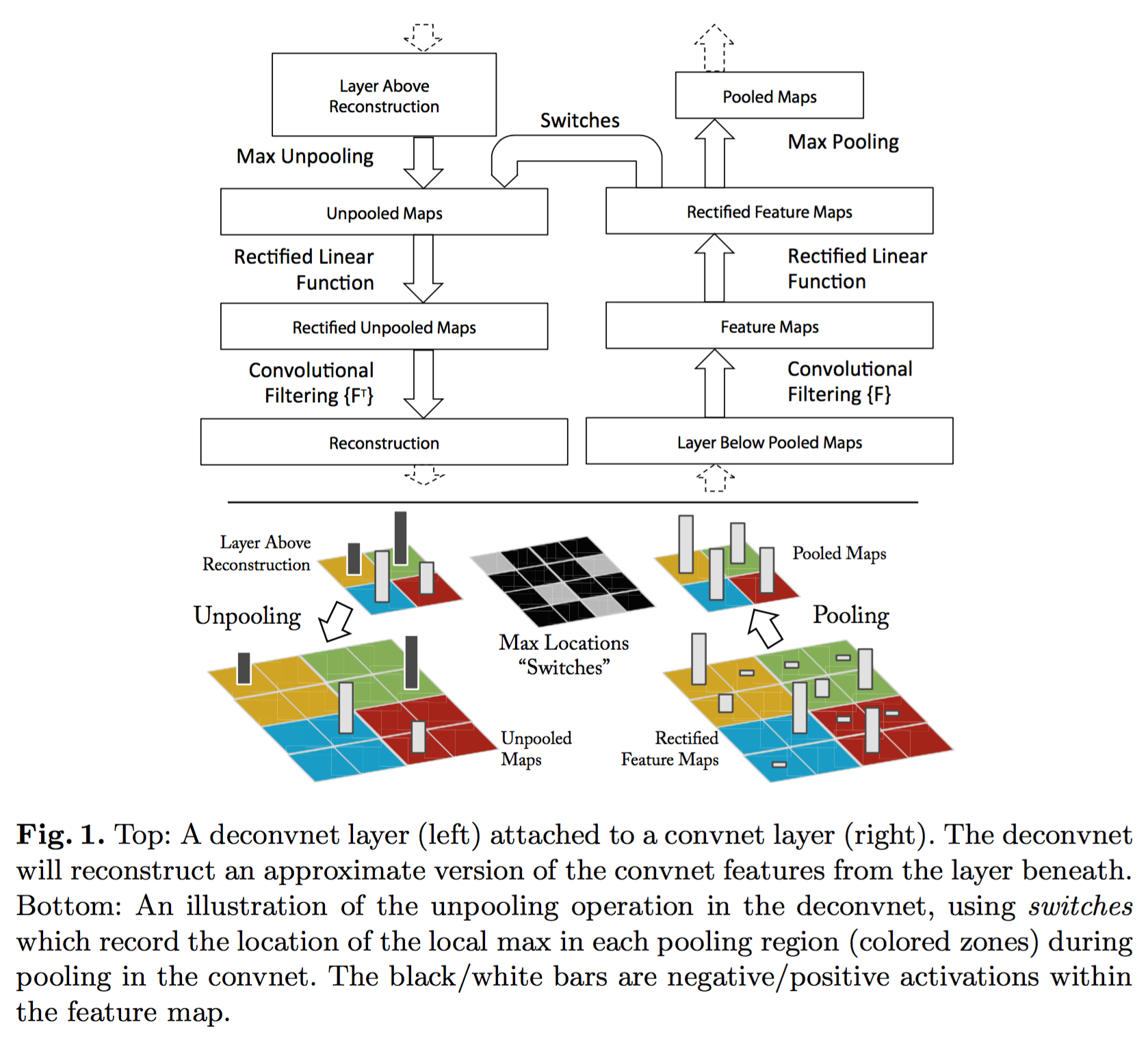
- 解卷积过程:将同一层的其他神经元置0,将该层作为解卷积的输入,依次经历了(i) unpool, (ii) rectify and (iii) filter
- Unpooling: Max-pooling 不可逆,为了解决这个问题,在做 Max-pooling 的时候,用一个 switch 变量记录最大值的位置。问题,可视化的时候,没有正向卷积过程,这个 switch 变量从哪来?
- Rectification:直接将重构信号通过 ReLU?
- Filtering:将卷积核做水平、垂直翻转后,再进行卷积。这就可以解卷积了?不应该要做个逆滤波?
解卷积解释:设原始信号为 $(f)$,卷积核为$(k)$,解卷积核为$(k')$,那么经过卷积和解卷积,信号变为
$(f * k * k')$,利用卷积运算的结合律,也可以表达为 $( f * (k * k') )$,如果要使得解卷积后的信号
和原始信号一致,那么需要 $( k * k' = \delta )$,即两个卷积核的卷积为单位冲击函数,也就是
$( \sum_{x',y'} k(x - x', y - y') k'(x', y') = \delta(x, y))$,即只有在$(x=0,y=0)$时为1,
其他情况为0。这里将卷积核水平和垂直翻转后,相当于 $( \sum_{x',y'} k(x - x', y - y') k(-x', -y'))$
可以看到,当x和y都为0时取得最大值(达到匹配),其他情况虽然不为0,但小于匹配的时候的值,所以可以看做逆滤波的一种近似实现. 不过简单试验结果表明,这种近似太粗糙了。
- CNN 训练的输入是[-128,128],居然没有归一化?!初始化是随机取的,幅度为$(10^{-2})$
卷积网络可视化

- 特征可视化:选取TOP9
- 结构选择:11x11滤波器改为7x7,stride减少到2,从而使得第1,2层滤波器提取到更多有用的信息。??
- 遮挡敏感性:测试分类器是否真的检测到了图片中的目标,还是只是用周围的信息。
- 选取第5层最强的 feature map 的响应值之和,随着遮挡的位置的变化。可视化的结果如图(b)。
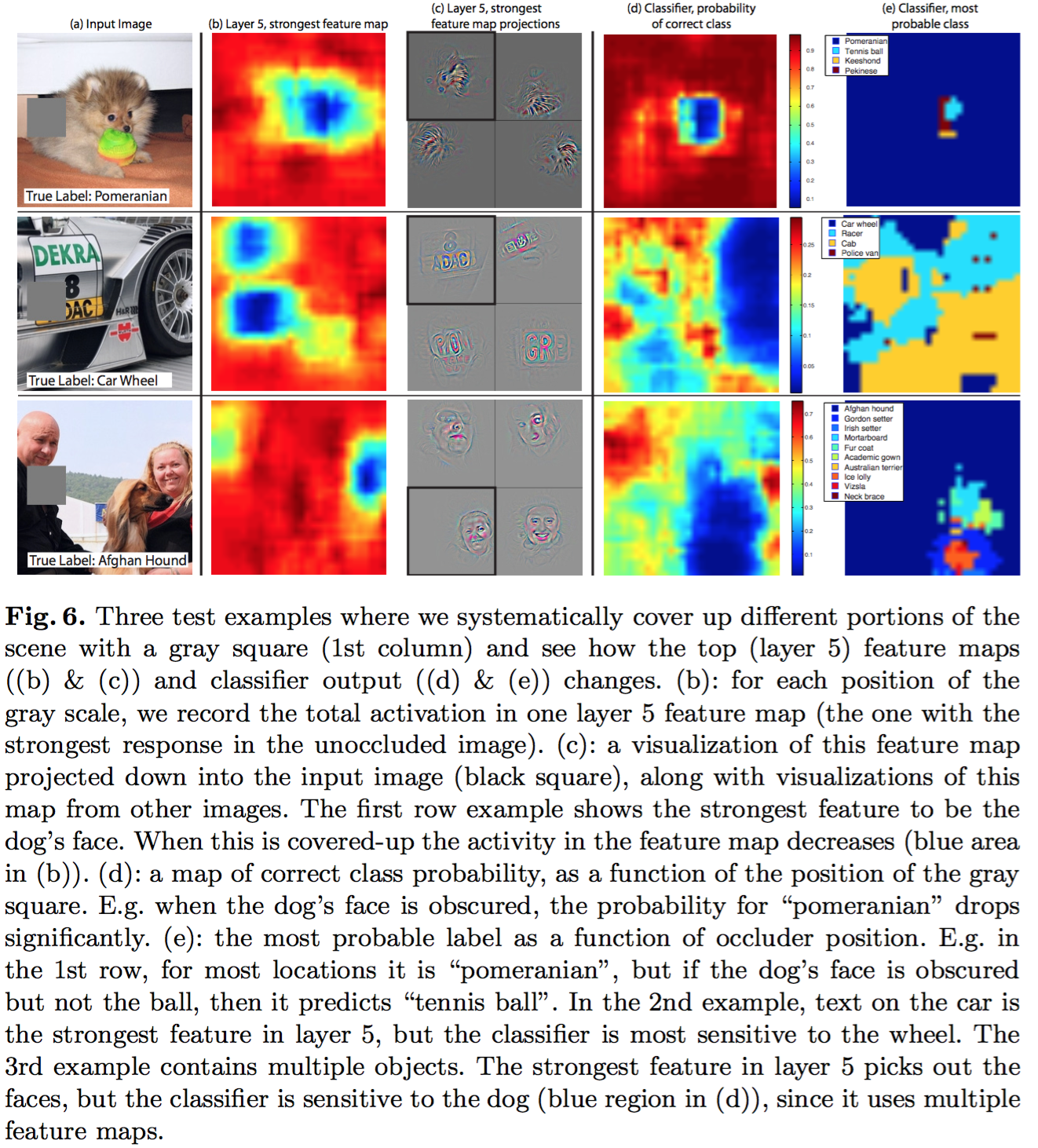
特征泛化能力
- 利用 ImageNet 学出来的模型,应用到其他任务,例如:Caltech
- 只改变最后一层,前面的层都固定不变。
问题
- 解卷积可视化具体是怎么样做的?
VGG net
- 论文:VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION, Simonyan and Zisserman, 2014 @ICLR 2015
- 重要贡献:通过非常小的卷积核 3x3,提升模型的深度!
- 1x1 卷积核的使用!
- 卷积的 stride 保持为1,保证卷积层后空间分辨率是不变的。
- pooling层保持为 2x2 大小的窗,stride=2.
- 没有使用 AlexNet 的 Local Response Normalisation 层!没有明显收益!
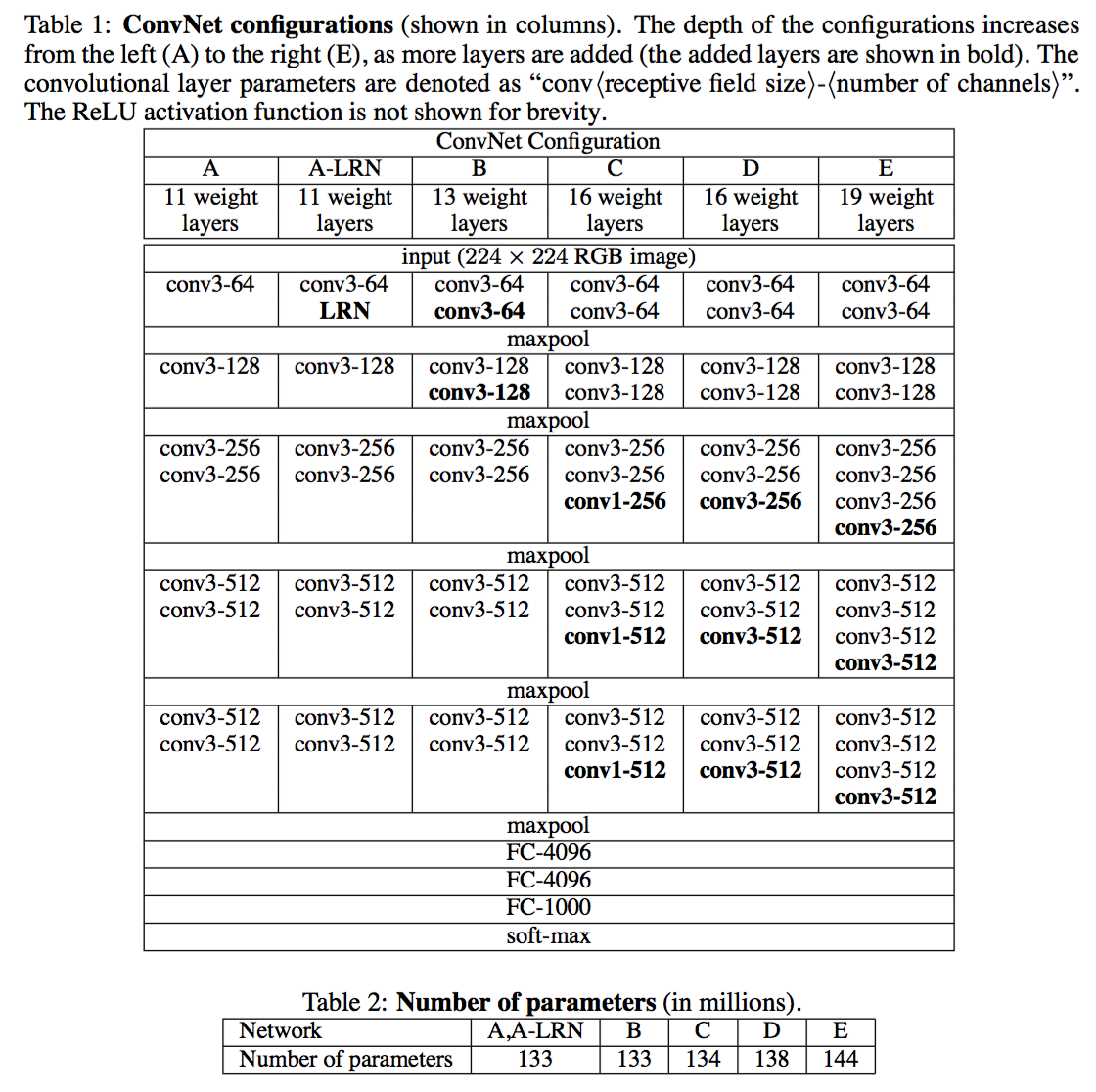
- 用两层3x3的卷积层代替一层5x5卷积层;3层3x3的卷积侧代替一层7x7卷积层;这种方法可以在不减少卷积核的覆盖范围情况下,增加非线性变换次数并减少参数!
- 1x1卷积层在不影响空间变换情况下,增加非线性变幻的次数!Network in network.
- 训练参数细节:
- mini-batch sgd, momentum = 0.9, batch size=256
- L2 正则参数5e-4
- dropout 0.5,最前面两侧全连接层
- 学习率初始值1e-2,当验证集不降低时除以10
- 74 epoch
- 训练图像尺寸:CNN输入块大小是224x224,图像被rescale尺寸为S。S可以是固定大小,也可以是多个分辨率。
- 固定尺寸:256,384(用256的权重初始化网络)
- 可变尺寸,在[256,512]之间随机变动S,scale jittering.
- testing:将全连接层变成全卷积层:将最后一层的通道作为class通道,然后在空间上平均得到不同位置的分类概率的平均值!这样就不用切割原始图像为多个块了!只要简答的rescale为固定的Q值即可。
- 对于固定resclae,取Q=S,对于scale jittering,取Q为S的平均值!
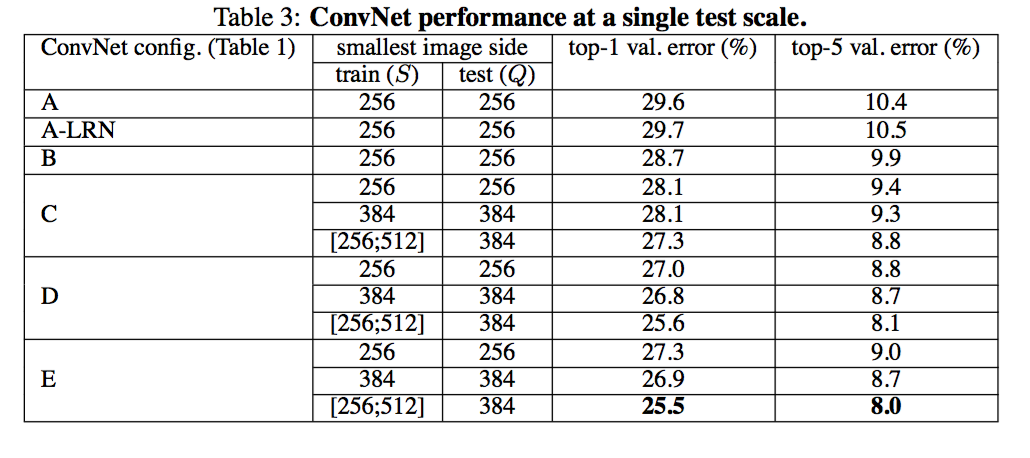
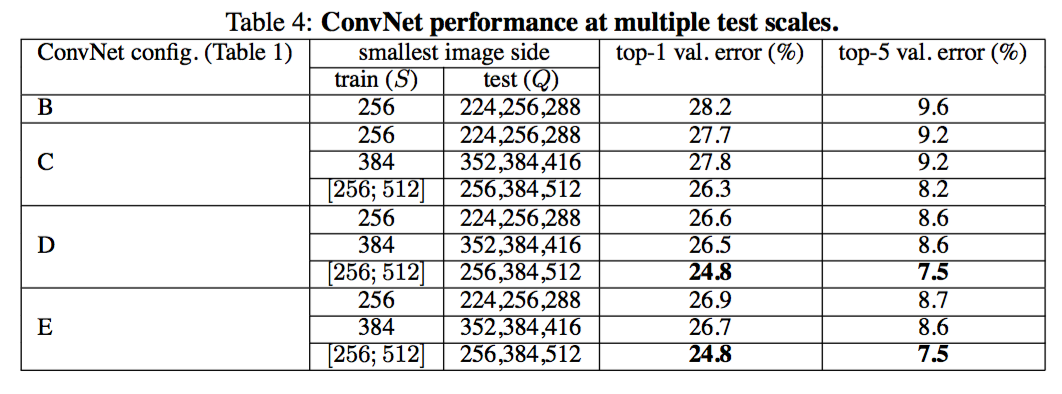
- 单个scale的评估:Q的取值策略如上;试验表明,scale jittering帮助提升效果!
- 多个scale的评估:Q取值策略,对固定S值,取S-32,S,S+32;对变动S值,取S_min,S_avg,S_max三个值。可以看到,比单个scale效果要好!
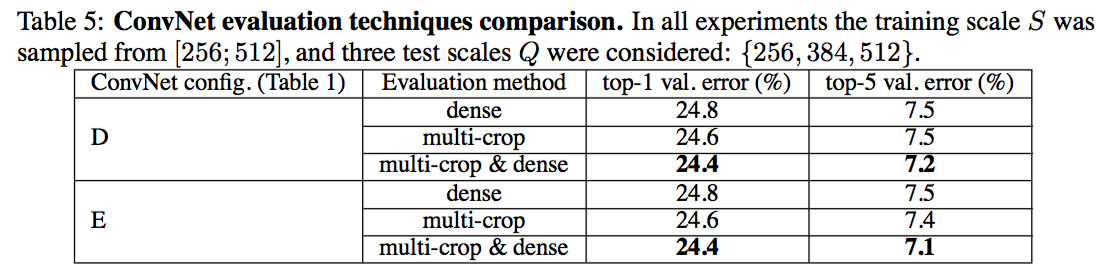
- 多个crop的评估:略
- 卷积网络融合:将每一个网络输出的多类概率平均。
- D模型参数数目分析:138M参数!大约是Alex的两倍!
- 参数主要集中在FC层,而内存消耗主要集中在前面几层!
GoogleLeNet
- 论文:Going Deeper with Convolutions,CVPR2015
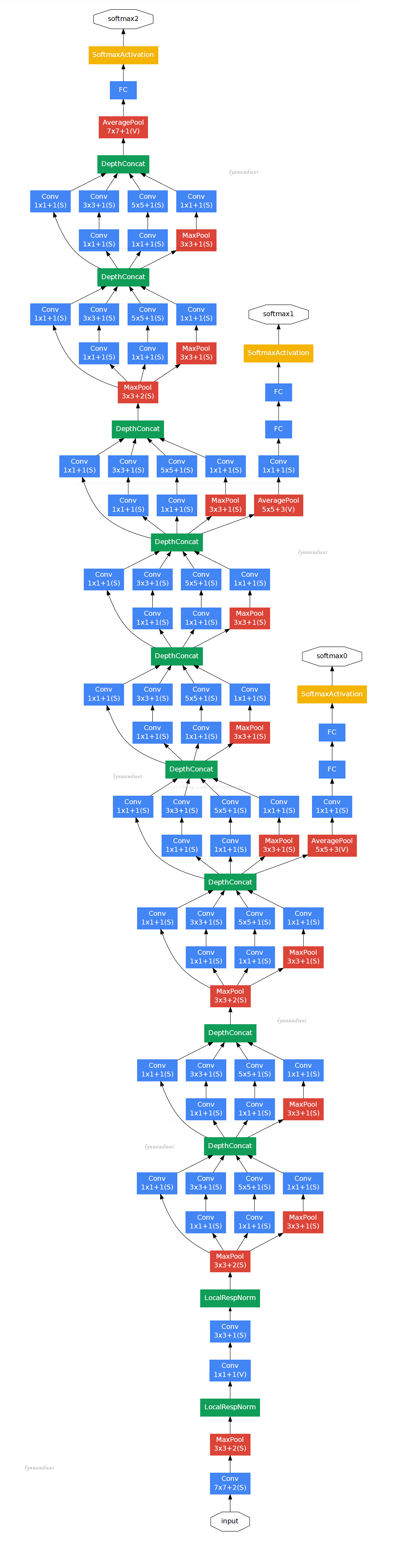
- 最大创新:增加网络的深度和宽度,但是保持计算代价不变!22层网络!
- 参数数目只有Alexnet的1/12.
- Inception结构,借鉴自 network in network.
- Hebbian principle: neurons that fire together, wire together
if the probability distribution of the dataset is representable by a large, very sparse deep neural network, then the optimal network topology can be constructed layer after layer by analyzing the correlation statistics of the pre- ceding layer activations and clustering neurons with highly correlated outputs
- 将稀疏矩阵乘法通过聚集后变成 dense matrix 乘法,可以充分利用计算资源。
- non-uniform deep-learning architectures
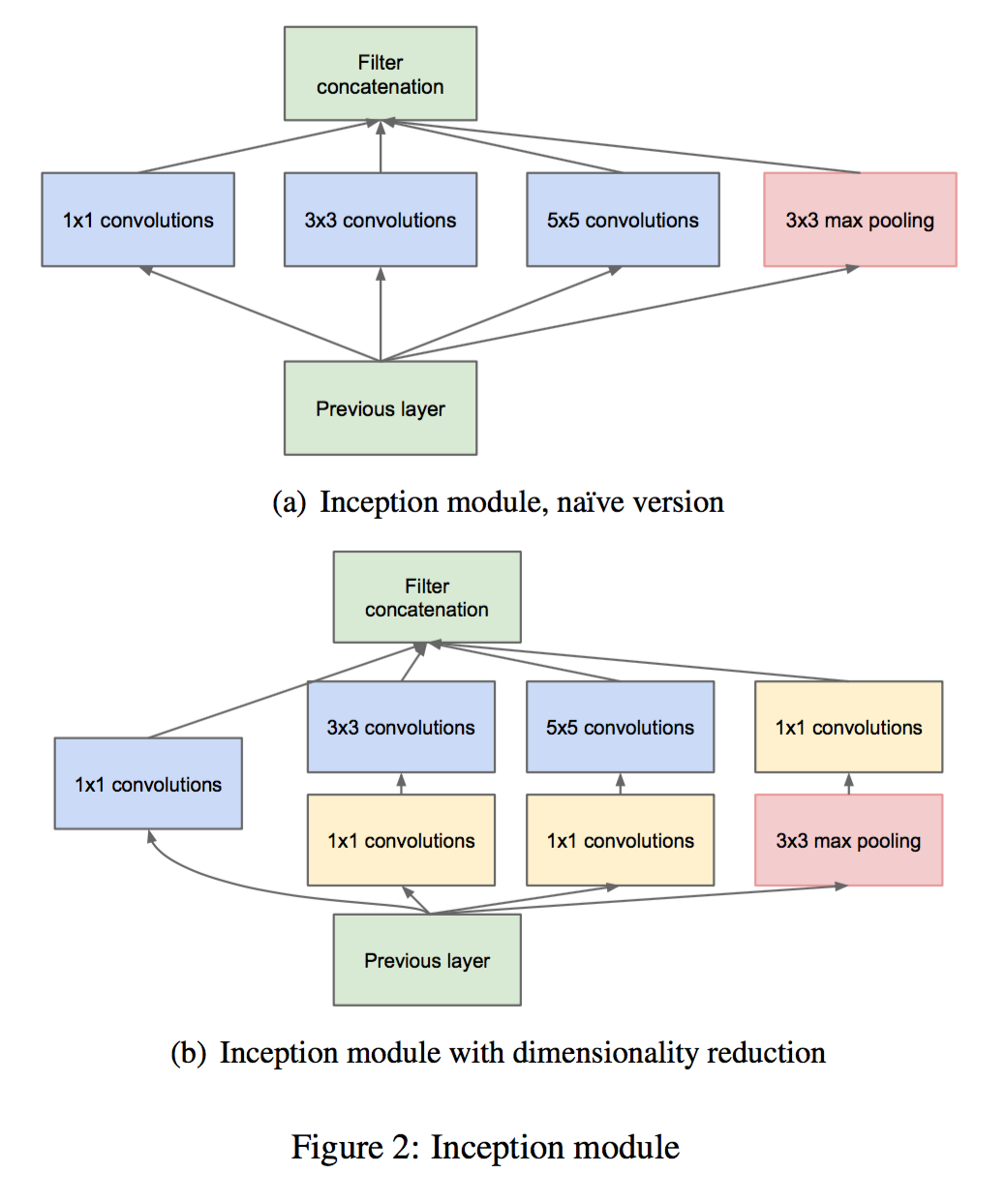
- 通过多个不同的滤波器,实现多尺度的抽取;通过1x1滤波器实现降维,减少大尺寸滤波器计算复杂度,也减少了参数!
- 22层,为了减少梯度消失效应,增加了中间的输出,以期望中间的特征也有一定的区分度!提供一种正则。
训练的时候,将这些低层分类的损失函数加到最终损失函数中,作为正则项!结果显示,这种效果不明显。
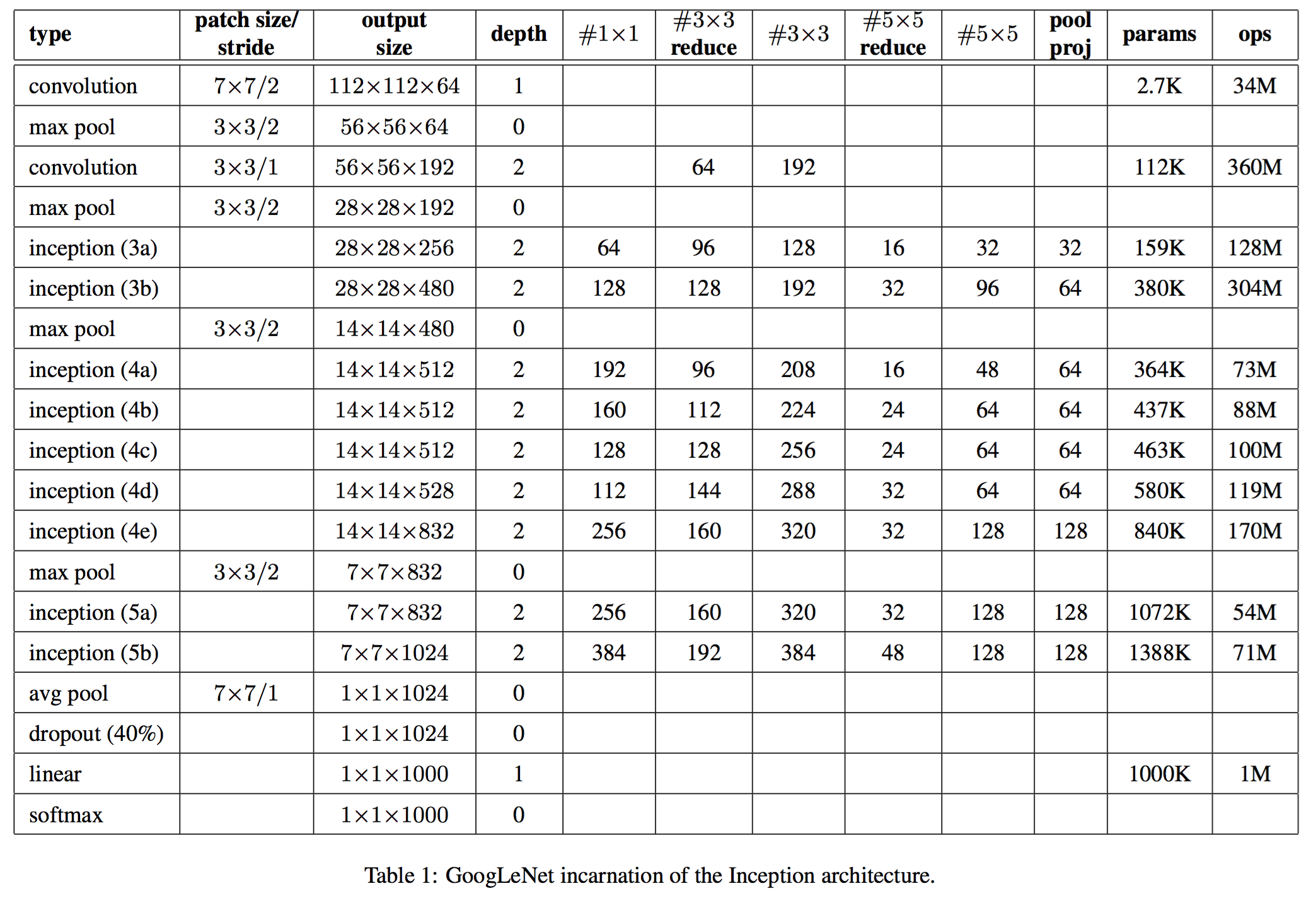
- GoogLeNet 的网络结构参数如表所示,其中#1x1,#3x3,#5x5分别代表对应的滤波器数目,而 #3×3 reduce 和 #5x5 reduce 分别代表 inception 中3x3滤波器和5x5滤波器前面用作降维的1x1滤波器数目,pool proj代表inception中Pool层后面的1x1滤波器数目!
- 完全移除了全连接层,取而代之的是 avg pool 层(top-1准确率提高了0.6%)!但是保留了dropout!
- 为了减少梯度消失的问题,在中间加了两个输出抽头!抽头的结构如下:
- 5x5 avg pooling, stride=3,分别将图片降维至 4x4x512, 4x4x528!
- 1x1滤波器降维至128维
- 全连接层1024的神经元
- 70% dropout
-
训练方法:用的是 DistBelief 分布式训练!模型并行和数据并行训练。CPU集群
- 异步 SGD, momenton=0.9
- 固定学习率策略,每8个poch减少4%
- Polyak averaging:B. T. Polyak and A. B. Juditsky. Acceleration of stochastic approximation by averaging. SIAM J. Con- trol Optim., 30(4):838–855, July 1992.
- 采样不同尺寸不同位置的patch
- photometric distortions:A. G. Howard. Some improvements on deep con- volutional neural network based image classification. CoRR, abs/1312.5402, 2013.
-
参赛配置:
- 没有额外的训练数据
- 训练了7个不同的版本,然后做融合:相同的初始权重,学习率,只在采用方法和图片的随机顺序不同
- testing阶段每个图片采样了不同尺寸不同位置不同镜像的多个块进行预测。
ResNet
参考WIKI残差网络
定位与检测
- 简单回归问题:
- 将定位作为一个回归问题,输出定位的坐标和尺寸4个数字,用L2损失函数,简单!
- 直接从分类模型最后一层的feature map引出一个回归抽头!
- 滑动窗:
- 在高分辨率图片中的不同尺寸和不同位置运行 分类+回归 网络
- 融合所有尺寸的分类+回归结果作为最终的输出
OverFeat
论文:OverFeat:Integrated Recognition, Localization and Detection
using Convolutional Networks,Pierre Sermanet, David Eigen,
Xiang Zhang, Michael Mathieu, Rob Fergus, Yann LeCun,2014.
- classification, localization and detection 的CNN集成框架
- multiscale 和 sliding window 技术
- ILSVRC2013 目标识别冠军
combining many localization predictions, detection can be performed without training on background samples and that it is possible to avoid the time-consuming and complicated bootstrapping training passes
- 在不同位置和不同scale使用CNN:大量的窗只包含目标的一部分,分类效果好,但是定位和检测效果不好。
- 每一个window不但输出不同类别的预测概率分布,还输出目标相对window的位置和大小!
-
累积每一个类别的每一个window的预测结果!
-
文本检测:M.DelakisandC.Garcia.Textdetectionwithconvolutionalneuralnetworks.InInternationalConference on Computer Vision Theory and Applications (VISAPP 2008), 2008.
- 人脸识别: C. Garcia and M. Delakis. Convolutional face finder: A neural architecture for fast and robust face detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2004.
- 人脸检测:M. Osadchy, Y. LeCun, and M. Miller. Synergistic face detection and pose estimation with energy-based models. Journal of Machine Learning Research, 8:1197–1215, May 2007.
-
行人检测:P. Sermanet, K. Kavukcuoglu, S. Chintala, and Y. LeCun. Pedestrian detection with unsupervised multi- stage feature learning. In Proc. International Conference on Computer Vision and Pattern Recognition (CVPR’13). IEEE, June 2013.
-
预测的box和groundtruth的box至少相交50%(IOU)才认为是对的。
IOU的定义:label框为A,groundtruth框为B,$(IOU = \frac{ area(A \bigcap B)}{ area(A \bigcup B)} )$
- 通过滑动窗,产生多个块,得到多个块预测结果,然后平均。滑动窗可以自底向上计算,不用每个滑动窗计算一个结果,减少计算量!
- 不同尺寸和位置检测得到的box融合成一个高可信的box,实现定位!
目标检测 HOG
论文:Histograms of Oriented Gradients for Human Detection,Navneet Dalal and Bill Triggs,2005.
RCNN
论文:Rich feature hierarchies for accurate object detection and semantic segmentation
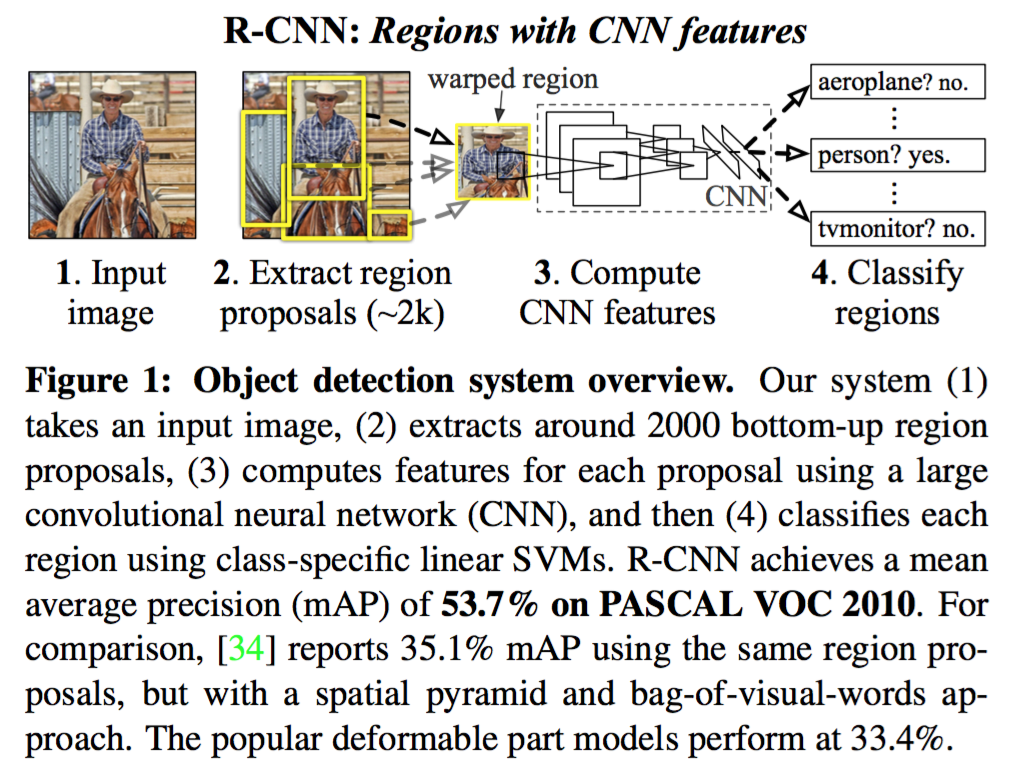
Region proposals
- objectness: B. Alexe, T. Deselaers, and V. Ferrari. Measuring the objectness of image windows. TPAMI, 2012.
- selective search: J.Uijlings,K.vandeSande,T.Gevers,andA.Smeulders.Selective search for object recognition. IJCV, 2013.
- category-independent object proposals: I. Endres and D. Hoiem. Category independent object proposals. In ECCV, 2010.
- constrained parametric min-cuts (CPMC): J. Carreira and C. Sminchisescu. CPMC: Automatic object segmentation using constrained parametric min-cuts. TPAMI, 2012.
- multi-scale combinatorial grouping: P.Arbelaez,J.Pont-Tuset,J.Barron,F.Marques,andJ.Malik.Multiscale combinatorial grouping. In CVPR, 2014.
- CNN: D.Cires ̧an,A.Giusti,L.Gambardella,andJ.Schmidhuber.Mitosis detection in breast cancer histology images with deep neural networks. In MICCAI, 2013.
Feature extraction
- 利用一个训练好的CNN网络(如 AlexNet 网络),对每个区域提取特征。
- 将每个区域补全和变形到标准的输入尺寸, alex net 要求输入时 227x227
Test-time detection
- 利用选择性搜索选出近2000个候选区域
- 用 CNN 提取每一个区域的特征向量,对每一个类别,使用对应的 SVM 分类器对特征打分
-
采用贪心的非最大值抑制方法(greedy non-maximum suppression, 每一个类是独立的):如果一个区域和另一个得分更高的区域 IoU 重叠度高于某个阈值,那么就拒绝这个得分低的区域。阈值是学习到的阈值?
-
性能对比(10K个类被):DPM+Hashing,5min/image; RCNN, 1min/image. T. Dean, M. A. Ruzon, M. Segal, J. Shlens, S. Vijayanarasimhan, and J. Yagnik. Fast, accurate detection of 100,000 object classes on a single machine. In CVPR, 2013.
Train
- 将在ImageNet上训练好的CNN最后一层替换成多个SVM(每一个类别一个,背景一个,SVM参数随机初始化),CNN参数也通过SGD调优
- 将于ground-truth重叠度IoU超过50%的区域作为该类的正样本,其他的作为负样本
- CNN调优的学习率降低10倍
- 每一个SGD的minbatch中,均匀采样32个正例和96个负例
- hard negative mining method:将分值较高的负例放到样本中重新训练
- pool5的特征就很好的,全连接层可以不要!
-
bbox regression:为每个区域训练一个回归模型,用相同的特征,只改变最后一层,预测目标的相对偏移。
-
最大的问题:慢,需要对每一个区域用CNN提特征!
Fast R-CNN
- 先用CNN对整个图片进行特征抽取(pool5特征,有空间维度的特征),在选取的RoI区域,用一个RoI Pooling层将特征尺寸变成固定的空间尺寸HxW,(空间尺寸固定了,整个特征的尺寸也固定了),然后为每一个区域中建立分类和回归模型。
- RoI还是通过预先的 region proposal 方法得到,这个部分是 Fast R-CNN 计算的瓶颈。
- 由于ROI将近2000个,计算最后的全连接层是计算瓶颈,可以通过 Truncated SVD 优化,其效果相当于用两层线性网络替换。
- 优点:只需要计算一次CNN即可!
- 优点:将回归和分类损失函数加到一起,优化一个目标,multi-task loss,端到端学习!
- 相比 R-CNN,训练时间加速8.8倍,预测时间加速146倍!每张图片的预测时间降低到0.32s,之前在分钟量级!效果也稍好;但是加上区域搜索时间(大约2s)后,只有25倍速度提升,搜索时间是瓶颈!
- 关键层: RoI pooling layer
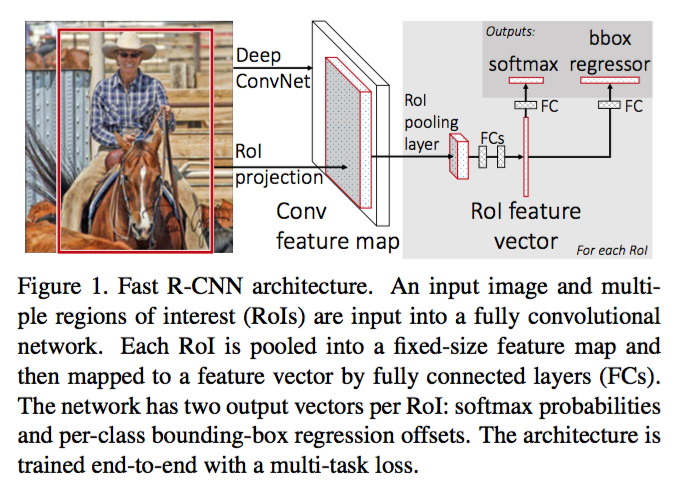
Faster R-CNN
用CNN做 region proposal,关键技术: Region Proposal Networks
CNN可视化
- R-CNN 计算所有的区域对某个神经元激活值,按照激活值从大到小排序,选取TOP区域可视化。

-
直接可视化权重:只能可视化第一层
-
可视化特征表达,例如用 t-SNE 可视化 AlexNet 最后一层的4096维特征
http://cs.stanford.edu/people/karpathy/cnnembed/
-
遮挡试验:分类概率与遮挡位置的函数关系!ZFNet
-
解卷积方法
BP to Image 方法:
可视化某个神经元的响应对输入图片的梯度(BP to Image),将该层所有神经元的梯度置0,将要可视化的那个神经元梯度置1!
然后运用BP算法,求出梯度。
$$
\frac{\Delta active}{\Delta I}
$$
由于高级特征具有不变性,不是针对某一个图片的,直接解卷积可视化得到的效果不好。
可以对于特定的图片,用这个图片做引导,通过 guided bp 得到条件梯度。
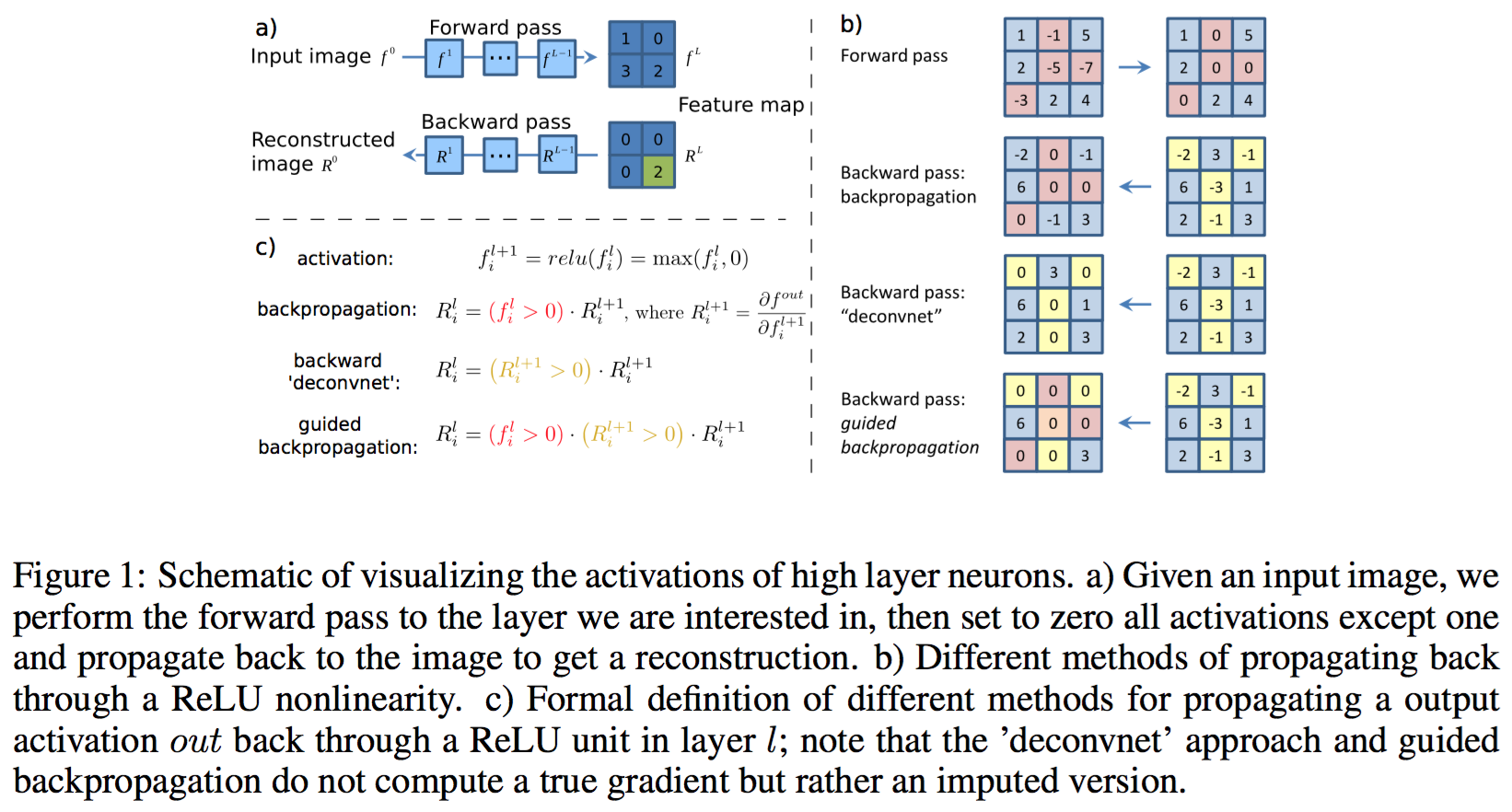

ZF 解卷积方法
- Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps
寻找图像I使得在类c上的score $(S_c(I))$ 最大!
$$
\arg \max_I S_c(I) - \lambda ||I|| _ 2^2
$$
利用 BP 算法优化,固定权重,优化输入!输入初始化为0值图片! Sc 是未归一化的score,优化归一化的score(即概率)效果反而不明显。
给定图像$(I_0)$,根据输入像素对某个类的score影响效果排序,影响效果通过梯度刻画
$$
w = \frac{\partial S_c}{\partial I} | _ {I_0}
$$
- 给定一个图片的code,寻找最接近这个code的图片
$$
x* = \arg \min _ x l(\Phi(x) - \Phi(x_0)) + \lambda R(x)
$$
- DeepDream:从一个初始图片开始,每次梯度沿着正反馈方向下降 dx = x!!这里x是神经网络某一层的响应值。即目标函数是,使得某个已经训练好的模型的某一层,激活函数的幅度最大化!
其结果是,如果最大化的是前面的层,那么图片中会显示出一些低级纹理,如果是后面的层,那么图片中会显示出一些学到的高级目标,如狗、猫的一些局部!