关于
被BERT和Transformer刷屏了,研究一下。
关键论文:
- Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
- Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. In Advances in Neural Information Pro- cessing Systems, pages 6000–6010.
Transformer要点
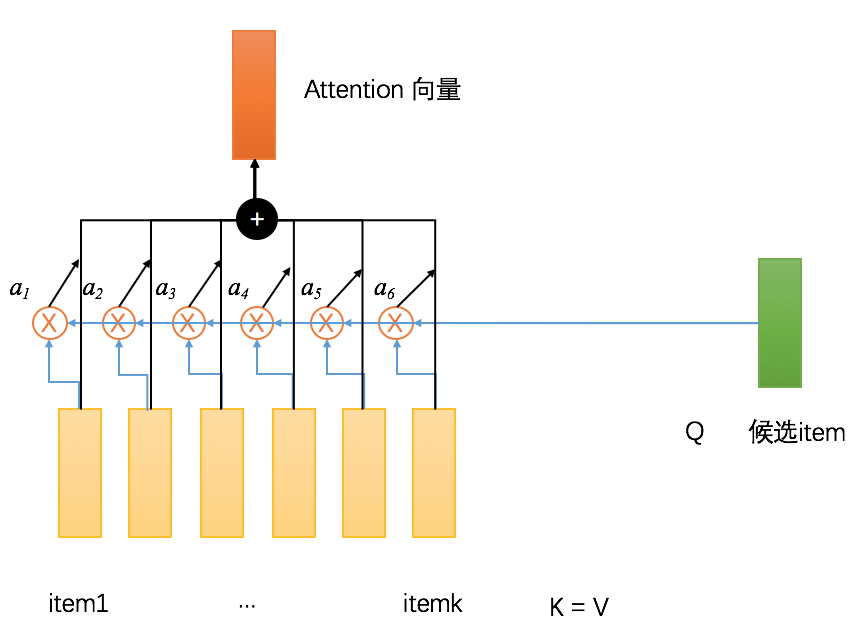
- Attention可以抽象为 (Q, K, V)三元组, Q代表query,在具体场景中可以是搜索的query, 推荐排序中的候选 item, 广告点击率预估中的候选广告etc 对应的 embedding 向量; K 和 V一般都是用户历史行为序列,比如用户的查询query序列,过去一段时间点击过的item序列, 过去一段时间点击过的广告序列 对应的 embedding 向量。(如下图所示)
- KV存储作为一个特殊的Attention机制: hard attention
- KV存储查询的时候,可以看做一个Attention机制,一个query过来,先计算Attention score,Attention score可以定义为如果k=q,那么Attention score ai=1, 否则ai=0。最终的输出可以看做所有的V按照Attention score的加权和。即只有等于q的那个k对应的v才被输出来
- KV这种可以看做hard Attention,即只输出其中一个
- 在NLP中也有这种hard Attention,计算q和k的相似度,然后只输出相似度最大的k对应的v。
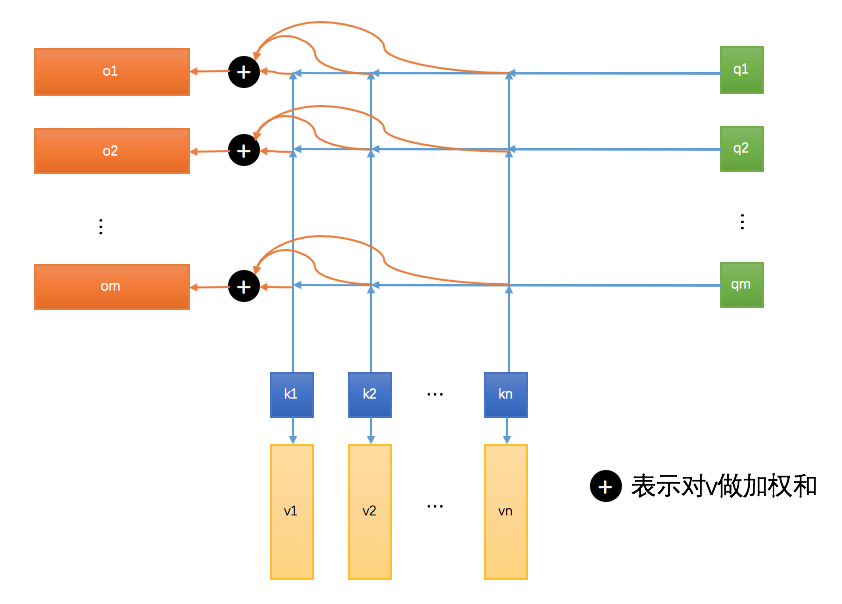
- 一般的Attention都是这种soft Attention,不是取最匹配的那个,而是计算一个匹配程度权重(即Attention score),然后按照这个权重对所有的v做加权和,如下图所示,在推荐系统中,可以用候选item和用户历史点击过的item计算相似度,得到Attention score,然后计算得到的加权和作为最终的输出。soft Attention一般会对Attention score用softmax 归一化, 而不是直接除以他们的和来归一化。
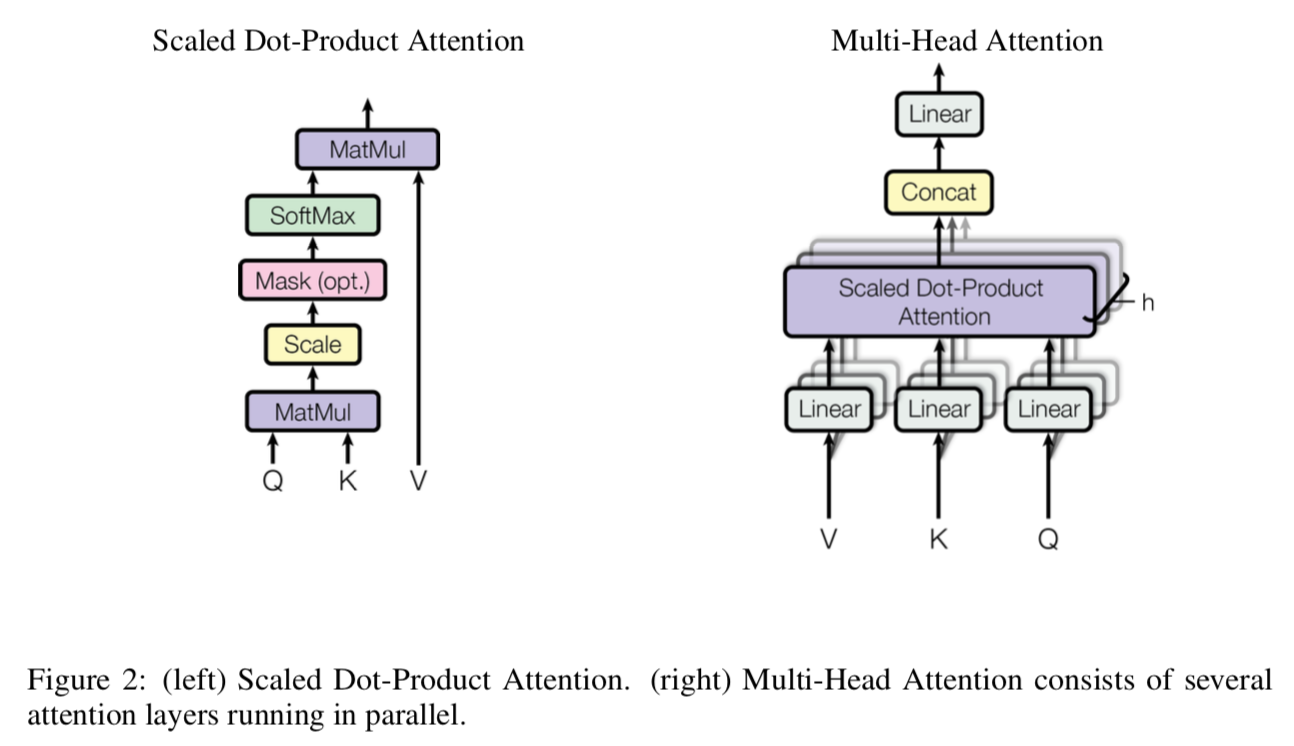
- 对应的矩阵计算过程就是, 除了一个 $(\sqrt{d_k})$ 也就是向量的维度,是为了防止softmax和内积导致差异太大。比如,如果向量维度非常大,那么相似度得分很容易非常大,比例跟维度$(d_k)$正相关,除以维度后,可以在一定程度上解决这个问题。参考下图,蓝色箭头表示对k和q做内积,黑色+表示用橙色的作为权重对v做加权和。注意attention的输出序列长度跟query序列长度一致, key 和 value 序列长度一致,实际上大多数情况K=V, 在self-attention的情况下, Q = K = V
$$
Attention(Q, K, V) = softmax(\frac{Q K^T}{\sqrt{d_k}}) V
$$
- 多头Attention, 一个Attention只在原始的向量空间中操作,可以将Q,K,V投影到不同的子空间甚至更高维度空间中(数学上就是分别乘以一个矩阵),再计算Attention向量,每一种投影就会有这样一个Attention向量,搞多个投影就得到多个Attention向量了。将多个向量拼接再投影,或者直接叫做线性组合,因为concat + 投影(乘以一个矩阵) 等价于分别投影到一个共同的空间中然后求和(也就是线性组合)。也就是说,多头Attention的输出和Attention输出是一样的, 所以能用Attention的地方就能用多头Attention。
$$
MultiHead(Q, K, V) = Concat(head_1, ..., head_h)W^O \\
head_i = Attention(QW_i^Q , KW_i^K , VW_i^V )
$$
-
self-attention, Q=K=V时,就是self-attention。self-attention时,不论是单头还是多头,输入一个向量序列,输出是一个相同长度的向量序列,每一个向量的维度可以不同,但是向量的数目是相同的。这恰好是一层RNN和一层CNN做的事情,这说明,self-attention可以实现RNN和CNN相同的事情,并且可以不断堆叠。
-
Position-wise Feed-Forward Networks: 输入已经attention模块的输出不都是向量序列吗?可以在这些地方插入所谓的PFFN,也就是用同一个神经网络对每一个向量做一个变换。相当于对这个向量序列使用了kernel size=1的一维卷积(下面这个式子实际上代表了两层这种卷积,第一层带了非线性激活函数,第二层是一个线性层)
$$
FFN(x) = \max(0, xW_1 + b_1) W_2 + b_2
$$
-
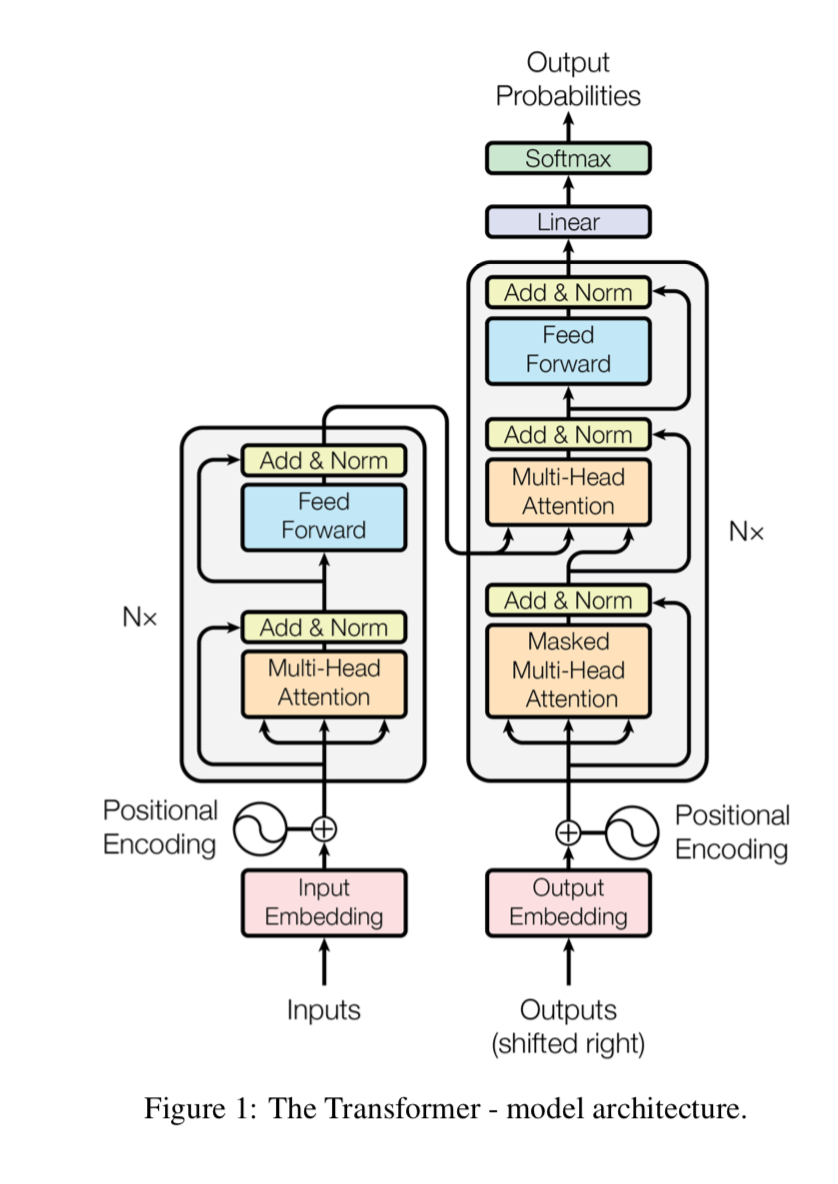
transformer也是Encoder-Decoder架构
- Encoder包含多个multi-head attention + FFN的子模块,Encoder的attention是self-attention。
- Decoder模块是由以下这三个模块重复堆叠N次
- 输入是将output往右移一位之后的向量序列,为了让当前的输出只依赖之前,所以会用一个mask将未来的序列给干掉。
- output的输入encode完了之后,与Encoder的输出一起放到一个multi-head attention中,这个attention的K和V由Encoder的输出向量序列提供,Q由Decoder的输入提供。
- attention输出在经过一个FFN变换。
- 输出是softmax,相当于一个多分类任务,每一个词就是一个类别,所以类别数量特别多
-
position Encoder, 将位置编码加入输入向量中。一种是直接embedding,文中用的是固定向量,v(t, i) = f(w_i t), t是偶数是就是cos,t是奇数时是sin, w_i 都很小,相当于在多个正弦波/余弦波中同一时刻(位置)采样一个值作为位置编码的向量。
Transform用作语言模型
- P. J. Liu, M. Saleh, E. Pot, B. Goodrich, R. Sepassi, L. Kaiser, and N. Shazeer. Generating wikipedia by summarizing long sequences. ICLR, 2018.
OpenAI
- Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. Improving language understanding with unsupervised learning. Technical report, OpenAI.
- Decoder中的Transform block可以看做对输入的向量序列做一个变换,变成另外一个向量序列,并且可以不断堆叠,堆叠后的最后一层再。如果把用上下文的那个attention模块改成self-attention就不用Encoder的输入了。那么Decoder就是一个语言模型的预测器!!
- 用语言模型预训练Transform的参数,并调优,就是这篇文章的核心要点。
- Decoder最后的输出全连接层可以替换成具体任务的全连接层,重新训练。
- 训练的时候可以将语言模型和监督任务联合训练,用语言模型做辅助损失,相当于正则项提高泛化能力
BERT论文要点
- 之前的工作都是用相同的目标函数, 使用单向语言模型学习通用的语义表示
- 作者认为这种单向的目标函数是制约 pre-trained 方法的表达能力的关键, 所以,作者搞了个双向语言模型, 即 Bidirectional Encoder Representations from Transformers。还是基于 Transformers
- 新的目标函数: masked language model(MLM 马赛克语言模型?) 随机mask输入句子中的一些词, 然后让模型根据上下文推断mask掉的这些词
Input: the man went to the [MASK1] . he bought a [MASK2] of milk.
Labels: [MASK1] = store; [MASK2] = gallon
- "next sentence prediction"
相关关键论文
- Matthew Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. 2018. Deep contextualized word representations. In NAACL.
- Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. Improving language understanding with unsupervised learning. Technical report, OpenAI.