摘要 & 导言
- Airbnb 问题的特殊性
- 是一个双边市场,既需要考虑考虑买家的体验,还需要考虑卖家的体验
- 用户很少有复购行为
- 99%的转化来自于实时搜索排序和推荐
- 方法:pairwise regression, 下单的作为正例,拒绝的作为负例
- lambda rank
- 联合优化买家和卖家的排序 ??
- 利用listing embeddings, low-dimensional vector representations计算用户交互的list与候选list的相似性,作为个性化特征放到排序模型中
- 利用点击等行为学习短期兴趣;而利用下单学习长期兴趣
- 问题: 下单行为过于稀疏, 一个用户平均一年旅行1-2次; 长尾用户只有一次下单
- 解决方法: 不是对userid做embedding,而是在用户类型维度做embedding,类型通过多对一的规则映射得到
-
论文创新点:
- 实时个性化
-
相关论文:
- Yahoo
- MihajloGrbovic,NemanjaDjuric,VladanRadosavljevic,FabrizioSilvestri,Ri-cardo Baeza-Yates, Andrew Feng,
Erik Ordentlich, Lee Yang, and Gavin Owens. 2016. Scalable semantic matching of queries to ads in sponsored
search advertis- ing. In SIGIR 2016. ACM, 375–384. - MihajloGrbovic,VladanRadosavljevic,NemanjaDjuric,NarayanBhamidipati, Jaikit Savla, Varun Bhagwan, and Doug Sharp. 2015.
E-commerce in your inbox: Product recommendations at scale. In Proceedings of the 21th ACM SIGKDD
International Conference on Knowledge Discovery and Data Mining. - Dawei Yin, Yuening Hu, Jiliang Tang, Tim Daly, Mianwei Zhou, Hua Ouyang, Jianhui Chen, Changsung Kang,
Hongbo Deng, Chikashi Nobata, et al. 2016. Ranking relevance in yahoo search. In Proceedings of the 22nd ACM SIGKDD.
- MihajloGrbovic,NemanjaDjuric,VladanRadosavljevic,FabrizioSilvestri,Ri-cardo Baeza-Yates, Andrew Feng,
- Etsy
- Kamelia Aryafar, Devin Guillory, and Liangjie Hong. 2016. An Ensemble-based Approach to Click-Through
Rate Prediction for Promoted Listings at Etsy. In arXiv preprint arXiv:1711.01377.
- Kamelia Aryafar, Devin Guillory, and Liangjie Hong. 2016. An Ensemble-based Approach to Click-Through
- Criteo
- Thomas Nedelec, Elena Smirnova, and Flavian Vasile. 2017. Specializing Joint Representations for the task
of Product Recommendation. arXiv preprint arXiv:1706.07625 (2017).
- Thomas Nedelec, Elena Smirnova, and Flavian Vasile. 2017. Specializing Joint Representations for the task
- Linkedin
- Benjamin Le. 2017. Deep Learning for Personalized Search and Recommender Systems. In Slideshare:
https://www.slideshare.net/BenjaminLe4/deep-learning-for-personalized-search-and-recommender-systems. - Thomas Schmitt, François Gonard, Philippe Caillou, and Michèle Sebag. 2017. Language Modelling for
Collaborative Filtering: Application to Job Applicant Matching. In IEEE International Conference on
Tools with Artificial Intelligence.
- Benjamin Le. 2017. Deep Learning for Personalized Search and Recommender Systems. In Slideshare:
- Tinder
- SteveLiu.2017.PersonalizedRecommendationsatTinder:TheTinVecApproach. In Slideshare:
https://www.slideshare.net/SessionsEvents/dr-steve-liu-chief-scientist-tinder-at-mlconf-sf-2017.
- SteveLiu.2017.PersonalizedRecommendationsatTinder:TheTinVecApproach. In Slideshare:
- Tumblr
- MihajloGrbovic,VladanRadosavljevic,NemanjaDjuric,NarayanBhamidipati, and Ananth Nagarajan. 2015.
Gender and interest targeting for sponsored post advertising at tumblr. In Proceedings of the 21th
ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 1819–1828.
- MihajloGrbovic,VladanRadosavljevic,NemanjaDjuric,NarayanBhamidipati, and Ananth Nagarajan. 2015.
- Instacart
- Sharath Rao. 2017. Learned Embeddings for Search at Instacart. In Slideshare:
https://www.slideshare.net/SharathRao6/learned-embeddings-for-search-and-discovery-at-instacart.
- Sharath Rao. 2017. Learned Embeddings for Search at Instacart. In Slideshare:
- Facebook
- Ledell Wu, Adam Fisch, Sumit Chopra, Keith Adams, Antoine Bordes, and Jason Weston. 2017.
StarSpace: Embed All The Things! arXiv preprint arXiv:1709.03856.
- Ledell Wu, Adam Fisch, Sumit Chopra, Keith Adams, Antoine Bordes, and Jason Weston. 2017.
- Yahoo
METHODOLOGY
- listing embedding 短期实时个性化
- user-type & listing type embeddings 长期个性化
Listing Embeddings(List指一个项目?还是列表?)
- session定义: $( s = (l_1, ..., l_M) )$ 非中断点击序列; 新的session定义为相继两次点击事件相隔30分钟以上。
- skip-gram模型: 损失函数
$$
\mathbf{L} = \sum_{s\in S}\sum_{l_i \in s} \sum_{-m \le j \le m, i \ne 0} P(l_{i+j} | l_i)
$$
利用负采样近似, 正例集合 $((l, c) \in D_p)$ l,c在同一个上下文; 负例集合 $( (l, c) \in D_n )$
$$
\arg\max_{\theta} \sum_{(l, c) \in D_p} \log \frac{1}{1 + e^{- v' _ c v_l}} + \sum_{(l, c) \in D_n} \log \frac{1}{1 + e^{v' _ c v_l}}
$$
- 将订购的listing作为全局上下文:
- booking sessions 最后有订购
- exploratory sessions
- 对于 booking session, 认为最终订购的listing跟之前点击的每一个listing都有相关性,所以可以将它作为之前点击的每一个listing的全局上下文
$$
\arg\max_{\theta} \sum_{(l, c) \in D_p} \log \frac{1}{1 + e^{- v' _ c v_l}} + \sum_{(l, c) \in D_n} \log \frac{1}{1 + e^{v' _ c v_l}} + \sum_{l} \log \frac{1}{1 + e^{- v' _ b v_l}}
$$
$( v_b )$ 是订购的listing
相当于增加一些正例!
- 在搜索场景性,用户看到的和搜索的大多是同一个小市场/区域中的房屋,所以正例都是在同一个市场中的房屋对,而负例都是随机采样的,所以负例对大多不在同一个市场中。
这导致模型难以学到市场内的相似性差异,所以可以额外加入一些同一个市场中的负例对。
$$
\sum_{(l, m_n) \in D_{m_n}} \log \frac{1}{1 + e^{v' _ {m_n} v_l}}
$$
$( D_{ m_n })$ 是采样自l同一个市场中的负例对。
- 冷启动问题: 选出新房源地点附近10miles半径范围内,相同房屋类型,相同价格带的3个有embedding向量的其他房屋,用它们的均值代表新房源的向量
- listing embedding检验: 向量维度32, session数量800M!
- embedding的重点是为了学习房屋特点、结构、类型、观感etc,等难以直接提取的相似性。作者开发了一个评估工具:Similarity Exploration Tool
- 学习到的类型: 船屋、树屋、城堡、小木屋、海景房 https://youtu.be/1kJSAG91TrI
User-type & Listing-type Embeddings
用用户的订购的序列作为session, 来学习跨market的相似性。这种跨market的相似性可以用来解决用户来到一个新的market的时候给他推荐的问题。
但是这种方法由于数据稀疏会带来一下几个问题:
- 大多数人的历史下单次数很少,甚至只有1个,没法学
- listing的长尾特性,导致长尾的listing的向量学得不好
- 由于时间跨度长,原来假设的相邻两个listing是相似的假设并成立,因为用户的偏好、价格等因素以及发生了改变
用 User-type & Listing-type 而不是ID
上下文是 (User-type, Listing-type) 对, 购买的对是正例, 没有购买的对是负例, 被拒绝的对也是负例。
session是同一个用户的购买序列 user-type, listing-type 序列, s =(ut1, lt1, ..., utM, ltM)
这样可以复用 word2vec 代码, 并在同一个空间投影, 让向量距离具有可比性!
试验
- session构建: 按照登录用户ID, 将点击的listing id按照点击时间排序, 然后按照30分钟不活跃划分成多个session , session数量800M, listing数量 4.5M
- 过滤掉在listing页面停留少于30s的事件(认为是噪音), 保留至少2个listing的session
- 过采样 booked session, x5
- 每天定期训练配置:
- 离线训练、评估、调参
- 滑动窗构建数据集, 数月的数据
- 每次都是重新开始训练(相同的随机数种子),随机初始化每一个向量; 发现比增量训练效果要好
- 每天都在变的向量对效果没有影响,因为最后使用的是余弦相似度作为特征
- d=32, 主要是性能和相似度检索的性能之间的权衡
- 上下文窗口为5, 10次遍历整个训练集
- 修改了word2vec
- 使用 MapReduce 训练: 300个mapper读数据, 1个reducer训练模型, 多线程训练 ?
- Airflow2 http://airbnb.io/projects/airflow
- 离线评估
- 设最后一次点击的listing是A, 待排序的listing列表是: BCDEFG。。。,待排序的列表需要包含了最终订购的listing,
我们可以计算A和这些listing的余弦相似度, 然后根据相似度排序,从而得到订购的listing排序的rank, rank越小,说明越靠前。 - 这种排序得到的订购listing的rank,取决于两个重要因素,一是当前距离最后订购之间还有几次点击, 显然越接近订购行为,相关性越强;
二是embedding向量的好坏, 这正是要评估的东西。 - 为了评估两种embedding向量好坏,可以固定距离最终订购之间的点击次数,来比较排序, 排序越靠前, 说明学到的embedding向量跟最终的排序目标越接近。
- 设最后一次点击的listing是A, 待排序的listing列表是: BCDEFG。。。,待排序的列表需要包含了最终订购的listing,
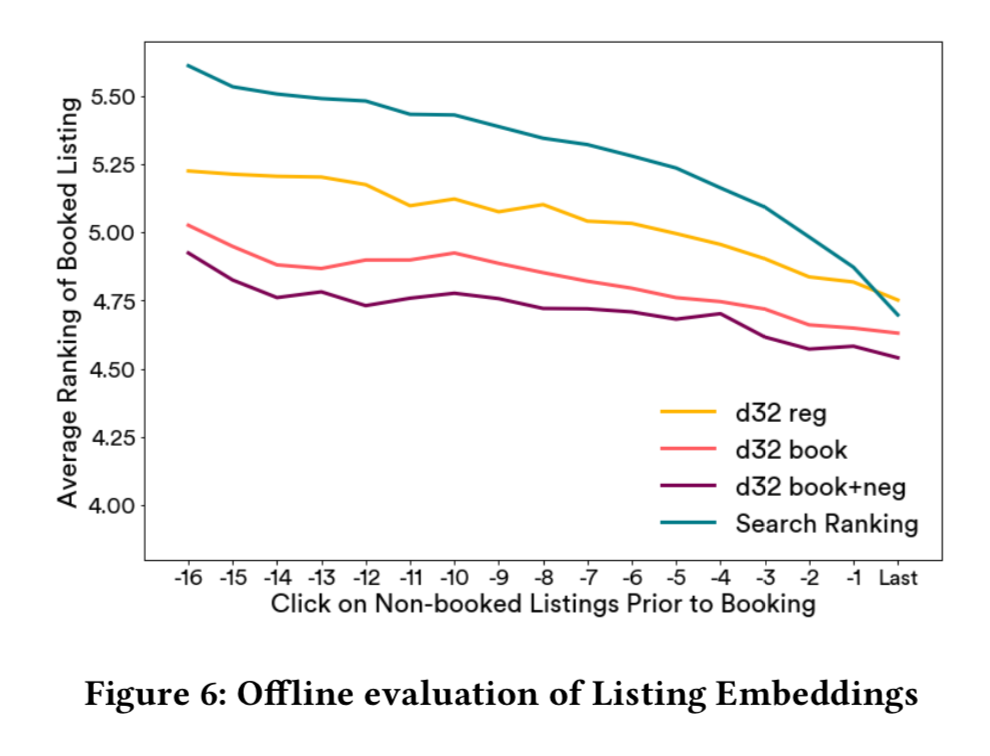
-
相似listing推荐
- 现有的方法是在给定的listing附近,根据是否可定购、价格范围、房屋类型筛选出候选集,然后调用搜索排序模块
- 从同一个market中, 在相同的日期内可订购的房屋中, 利用embedding向量直接找K近邻, 用余弦相似度度量距离
- CTR 提升了21%
-
实时个性化
- 排序模型:
- 标签: $( y_i \in \{ 0, 0.01, 0.25, 1, -0.4 \} )$ 分别代表,只曝光,曝光后只有点击, 曝光后用户联系了但是没订购, 1订购, -0.4房东拒绝了。
- 特征: listing features, user features, query features and cross-features
- 曝光后用一周的观测时间获得label, 只保留那些曝光列表中有订购的房屋的数据。
- 利用GBDT进行 pairwise regression, lambda rank损失, NDCG metric。
- Listing Embedding Features:
- 对于每个用户ID, 用Kafka收集用户近两周的房屋id集合
- Hc 近两周点击过的listing id
- Hlc 点击过且页面停留时间超过60s的listing id
- Hs 用户跳过的曝光靠前的listing id
- Hw 用户近两周加到心愿单的listing id
- Hi 用户近两周咨询过的listing id
- Hb 用户近两周订购过的listing id
- 将上述每一个集合进一步分成同market的子集, 例如: Hc 里面有 New York 和 Los Angeles两个市场,那么就会分成两个子集 Hc(NY), Hc(LA)
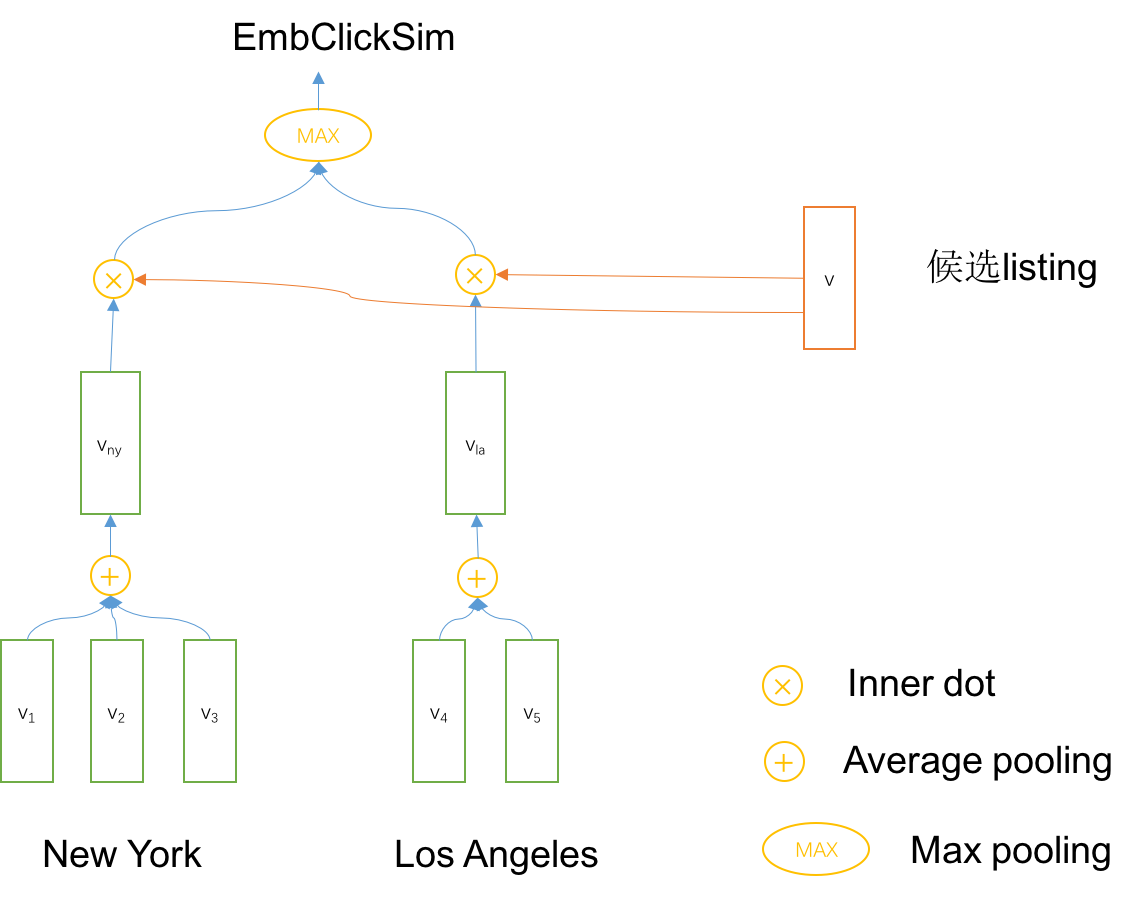
- 以EmbClickSim为例,说明这个特征的构造过程:
- 先计算每一个market的embedding中心, 也就是按照Market对 listing id的vector做average Pooling
- 计算候选的listing的向量与每一个中心的相似度(距离), 得到多个距离,然后取相似度的最大值(最小距离), max pooling
- EmbLastLongClickSim 是从Hlc中找到最近点击的listing id,计算的相似度,最后一个影响大
- UserTypeListingTypeSim 直接拿type的embedding向量计算的余弦相似度
- 对于每个用户ID, 用Kafka收集用户近两周的房屋id集合
- 特征单因素分析,固定其他特征,改变单个特征,分析单个特征变化对排序分数影响, (跟我的想法一模一样)
- 排序模型:
-
NDCU(Discounted Cumulative Utility)提升 2.27%, 指标就不列了
- NDCU 相当于用y作为Gain, 计算的NDCG, 而不是用 $(2^r - 1)$ 作为Gain ?

问题
- wor2vec 如何嵌入到MapReduce中?怎么实现?
- NDCU ?