Table of Contents
关于
- 论文: Applying Deep Learning To Airbnb Search
摘要与导言
- 排序候选集只有几千个
- 算法迭代:
- 手工打分函数
- GBDT(很大提升,然后饱和)
- NN
- 模型预测目标
- 房主接受顾客预订的概率
- 顾客给这段经历打5分的概率
- 也是目前重要考虑的点: 顾客会订购的概率
- 搜索的特点
- 用户会搜索多次
- 点击一些listing去查看详情
- 最终订购
- 新模型通过老的模型部署后产生的线上数据进行训练, 得到一个打分函数
- 特征工程, 系统工程, 超参数搜索
模型演化
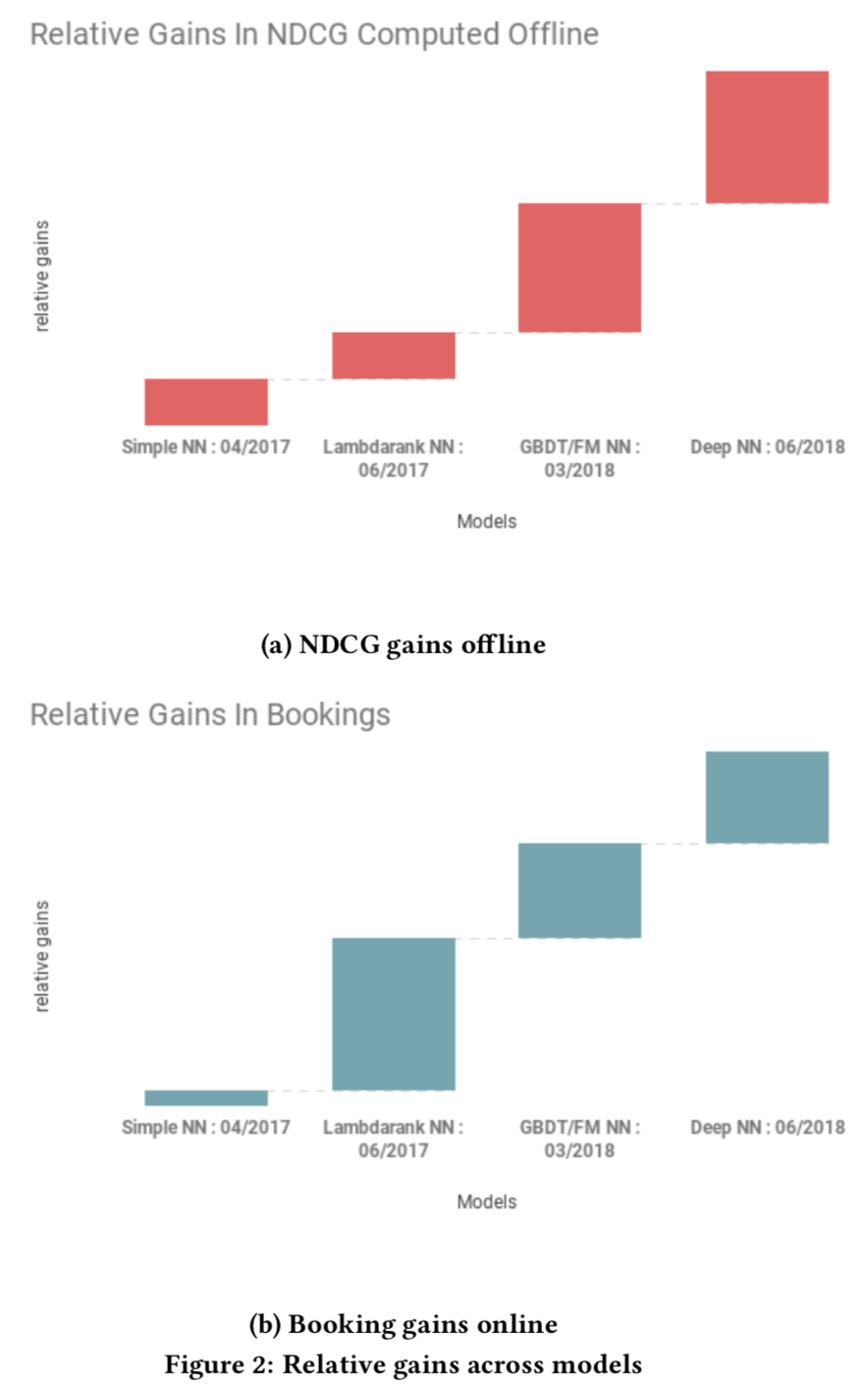
- 评估指标 NDCG
- 订购的相关性为1, 其他都是0
- 左图显示了不同模型的离线NDCG上的收益, SimpleNN没有GBDT好, DeepNN最好
SimpleNN
- 单隐层, 32个隐层节点, ReLU激活函数, 击败了GBDT, 相同的特征, 最小化 L2 回归损失函数, 1订购, 0未订购 ???
- 作用: 用于验证pipeline和线上系统正确性
Lambdarank NN
- 将 Lambdarank 的思想应用到NN上,直接上代码了(后面根据这个复现一下)
def apply_discount(x): '''Apply positional discount curve''' return np.log(2.0)/np.log(2.0 + x) def compute_weights(logit_op, session): '''Compute loss weights based on delta ndcg. logit_op is a [BATCH_SIZE, NUM_SAMPLES] shaped tensor corresponding to the output layer of the network. Each row corresponds to a search and each column a listing in the search result. Column 0 is the booked listing, while columns 1 through NUM_SAMPLES - 1 the not-booked listings. ''' logit_vals = session.run(logit_op) ranks = NUM_SAMPLES - 1 - logit_vals.argsort(axis=1).argsort(axis=1) discounted_non_booking = apply_discount(ranks[:, 1:]) discounted_booking = apply_discount(np.expand_dims(ranks[:, 0], axis=1)) discounted_weights = np.abs(discounted_booking - discounted_non_booking) return discounted_weight # Compute the pairwise loss pairwise_loss = tf.nn.sigmoid_cross_entropy_with_logits( targets=tf.ones_like(logit_op[:, 0]), logits=logit_op[:, 0] - logit_op[:, i:] ) # Compute the lambdarank weights based on delta ndcg weights = compute_weights(logit_op, session) # Multiply pairwise loss by lambdarank weights loss = tf.reduce_mean(tf.multiply(pairwise_loss, weights))
Decision Tree/Factorization Machine NN
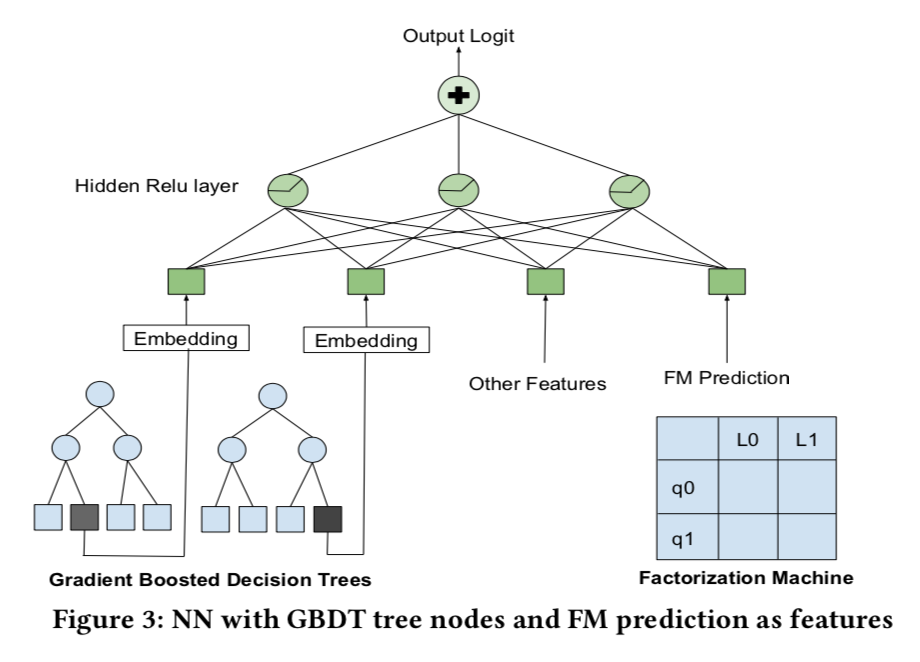
- 在这个阶段主要线上模型是NN,
- 同时:
- 用GBDT模型构造训练集 Iterations on the GBDT model with alternative ways to sample searches for constructing the training data.
- 用FM学习query和listing的相关性, 用32维向量
- 将GDBT输出的叶子节点作为类别特征, embedding输入到NN, FM输出的相关性得分直接输入NN
Deep NN
- 数据集扩大10倍, 17亿对样本对, NN的隐层数目增加到2层
- 特征:
- 价格, 环境(amenities), 历史订购次数, etc
- 智能定价价格
- listing和该用户历史看过的listing的相似度 (就是KDD2018 best paper那篇文章)
错误的模型
- 两个流行的方法,但是实际没有效果
Listing ID
- 将 listing id作为特征, 然后 embedding, 输入到NN
- 试了很多版本, 加入 listing id 很容易过拟合
- 原因是listing订购数据太稀疏了,即使一年也只有365次,更不用说那些不热门的listing了
Multi-task learning
- 用长时间浏览作为辅助任务,做MTL。
- log(view duration)作为权重?
- 试验结果发现对长时间浏览任务有较大帮助,但是对订购没有帮助
Xing Yi, Liangjie Hong, Erheng Zhong, Nanthan Nan Liu, and Suju Rajan. 2014. Beyond Clicks: Dwell Time for Personalization. In Proceedings of the 8th ACM Conference on Recommender Systems (RecSys ’14). ACM, New York, NY, USA,
特征工程
- 对于NN, 是为了让特征具有某些特殊的性质, 让NN能够学到复杂的计算逻辑
- 特征归一化, 均值方差归一化; 对于幂率分布, 用$(log(\frac{1 + v}{1 + median}))$归一化。为什么不用cdf?

- 数据不是平滑的分布
- Spotting bugs 大规模的数据中难免有少数bug数据,简单的范围限制的方法,只能找到一部分,还有一部分可以通过平滑分布找到。例如,对于某地区的价格,log之后的分布图中哪些尖锐的值很有可能就是bug数据
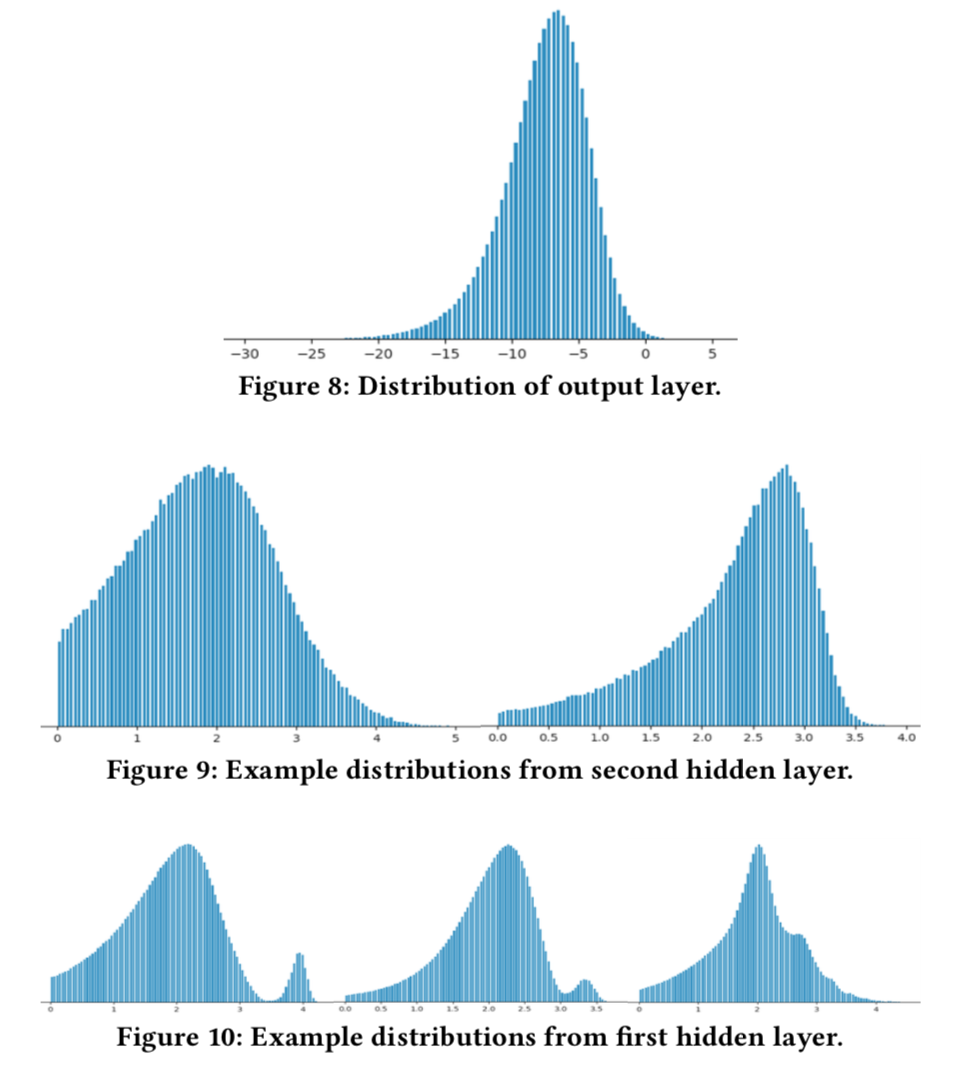
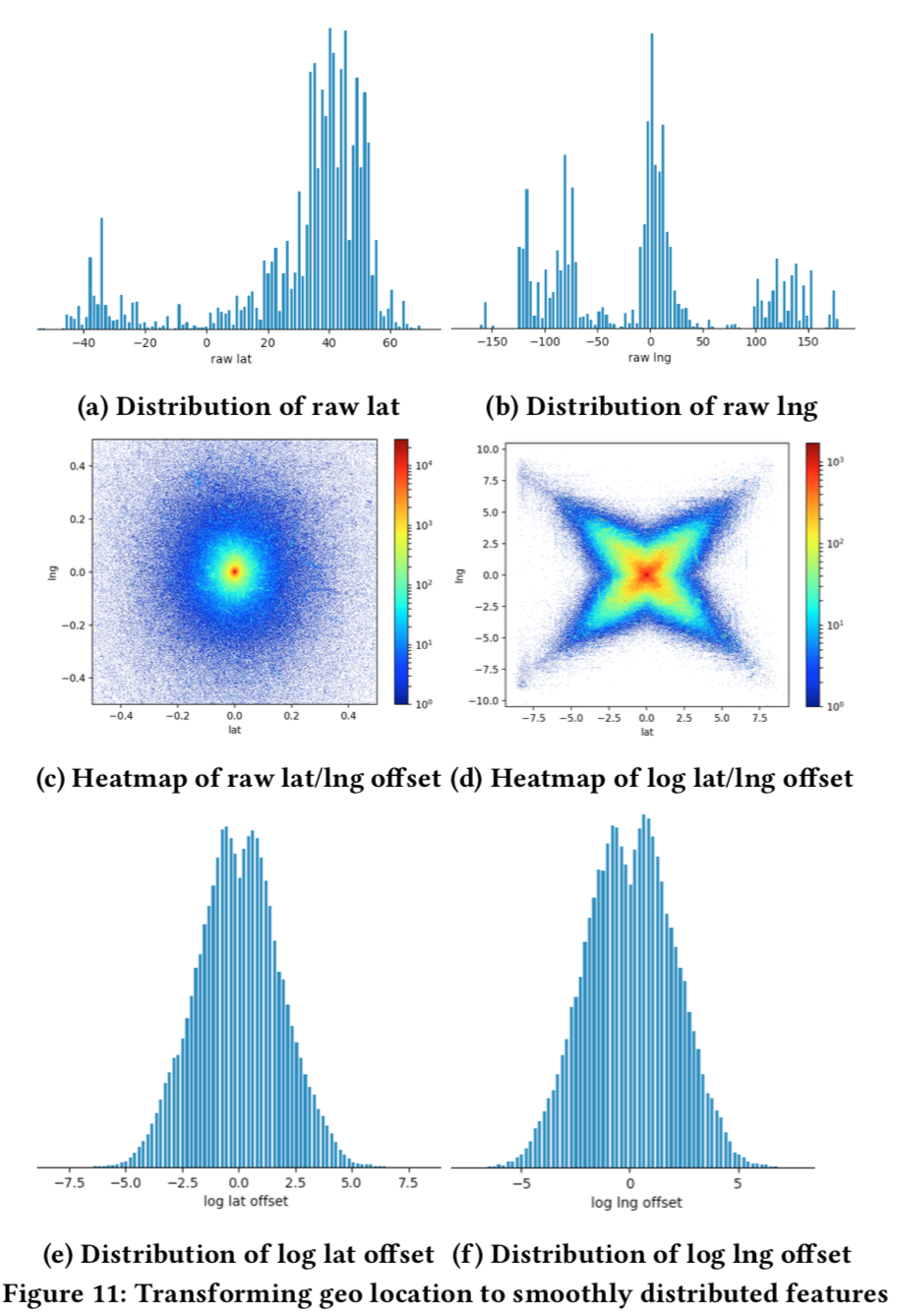
- Facilitating generalization DNN每一层的输出的分布越来越平滑,(下图, log(1 + relu_output))。作者认为,底层的输出分布越平滑,上层神经元越能泛化到未知数据中。作者通过抖动测试印证了这一点, 通过将测试集中的所有样本的某个特征放到2倍,3倍,观察NDCG的变化,发现观察到前所未有的稳定性。因此,作者认为要尽可能保证输入的特征分布的平滑。绝大多数特征都可以通过修复bug+合适的变换得到平滑的分布,还有一部分是需要特殊的特征工程的,listing用经纬度表示的地理位置。经纬度的原始值是不平滑的分布(图11a 和 图11b),作者使用了经纬度的相对偏移,将经纬度的原点放在用户看到的地图中心,用相对经纬度代替经纬度,分布就平滑很多(图11c 和 图11 e),作者还对相对经纬度取log得到新的一组平滑分布特征。
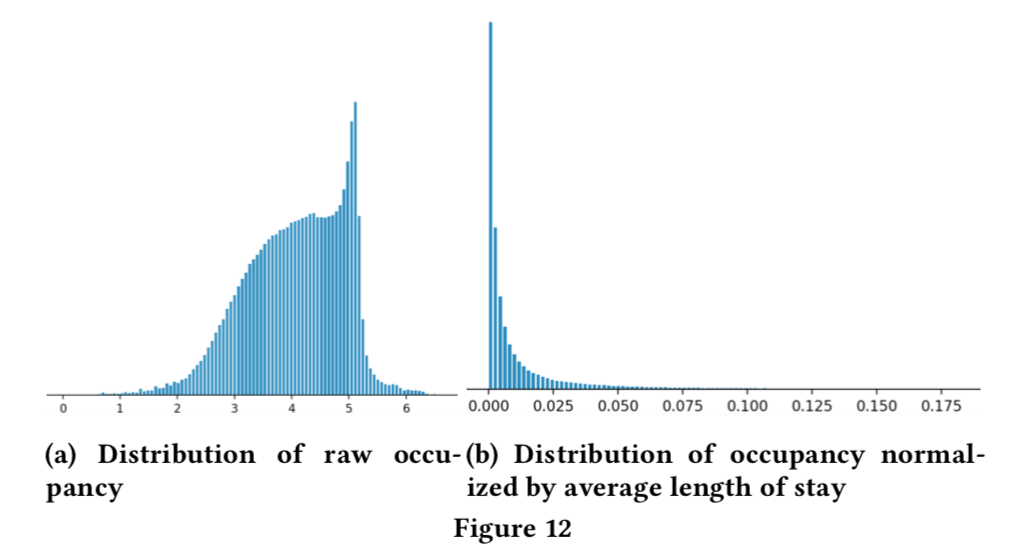
- Checking feature completeness 用listing的未来可订购天数作为特征, 但是原始的入住天数分布不平滑(图12 a)。通过调研,作者发现另外一个影响因素: listing有最小停留时间要求,有一些要求至少一个月!因此,他们有不同的入住率,但是我们又不能将这个作为特征放进去,因为它跟日期有关而且也太复杂了。作者添加了平均入住时长作为特征,一旦入住天数用平均入住时长归一化后,它们的比值竟然具有平滑的分布了(图12 b)!!
- 高维类别特征
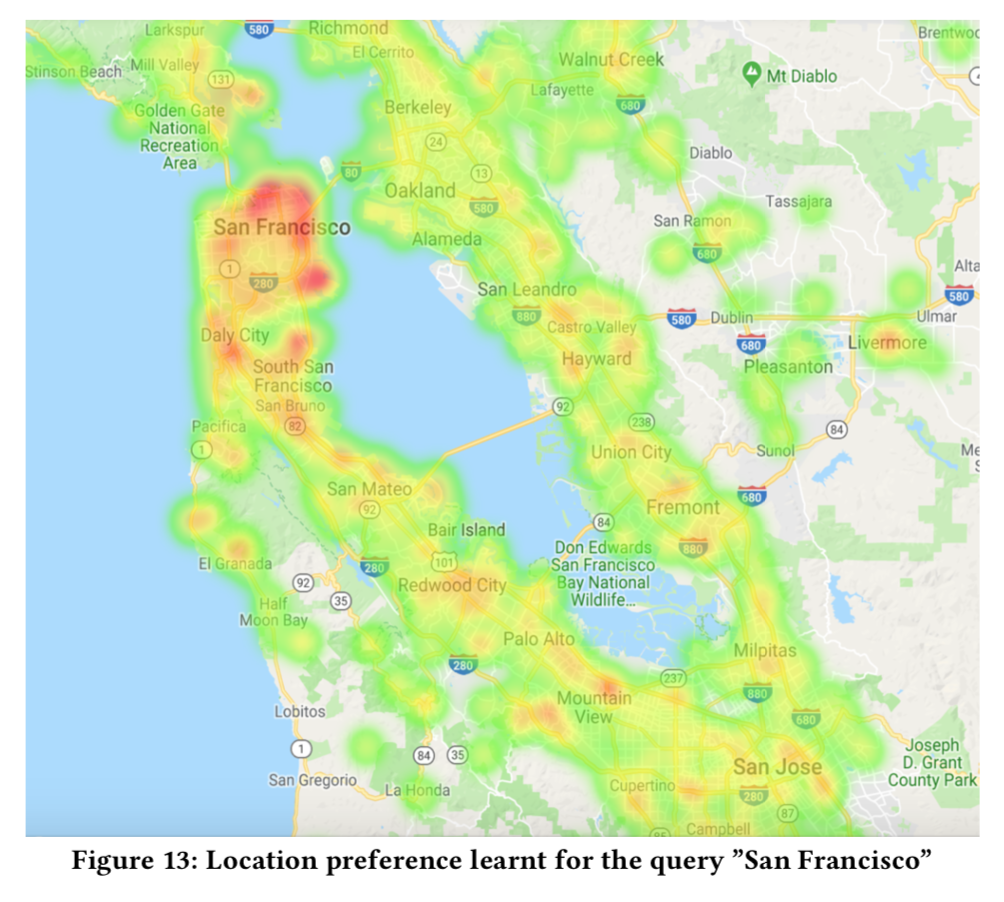
- 对附近城市的偏好是一个重要的位置信息,然而在GDBT中需要耗费很多力气来做这特特征,而且还没有考虑价格等关键因素。在DNN中,直接将查询的城市与listing的第12级S2 cell一起,hash到一个整数即可。例如,query城市为「San Francisco」,listing在Embarcadero附近,对应的S2 cell是539058204, hash({"San Francisco", 539058204}) = 71829521 作为输入DNN的类别特征。我的理解是,其实就是「两个离散特征交叉得到另外一个更高维的离散特征」嘛!
- 下图可视化了query=San Francisco时,不同位置的embedding values的大小(取模?),可以看到,不仅San Francisco附近的值很高,而且在一些靠南的地方也很高。
系统工程
- 目的:加速模型训练和在线打分
-
系统架构:
- Java服务提供查询接口和打分, 该服务同时记录日志,日志格式使用序列化后的 Thrift 对象
- 日志通过Spark处理,得到训练数据
- 模型训练使用的是 TensorFlow
- 用Scala 和 Java实现了一些工具评估模型和计算离线指标
- 然后,模型上传到服务中实现检索和打分
- 所有的都运行在AWS上
-
一开始用的是CSV格式作为训练集(迁移自GBDT),通过
feed_dict将数据喂给GPU,GPU使用率只有25%, 后来改为protobuf和DataSet方式,速度快了17倍,GPU使用率也达到了90%。 - listing很多特征都是静态的,每次读取数据会有大量磁盘读取,作者将这些特征作为listing id的embedding向量,而用listing id作为输入特征,和普通的embedding向量不同的是,这个向量在训练的过程中保持不变。相当于用内存做cache。
- Java NN lib, 在2017年早期的时候,还没有好用的Java NN打分的库,作者自己写了一个,降低了延时。话说现在能通过JNI的 TensorFlow Java API了
超参数
- Dropout 没啥用
- NN权重用 Xavier 初始化; Embedding用[-1, 1]均匀初始化
- Adam默认参数就很好了,现在用的是 LazyAdam,在大embedding时更快一些
- 用固定的batchsize=200,对训练速度影响挺大的
特征重要性
- GBDT的部分依赖图 https://scikit-learn.org/stable/auto_examples/ensemble/plot_partial_dependence.html
- Ablation Test 一次去掉一个特征, 观察对模型性能的影响
- Permutation Test 选择一个特征,将测试集中的该特征在整个测试集中重新随机排列,观察模型在测试集上效果的差异。越重要的特征,这个差异就越大。但是,实际上只能证明随机排列如果对效果影响不大,特征没啥效果;但是如果影响约大,并不能说明特征约重要,因为随机排列生成的数据在真实实际并不存在,特征间并不独立。
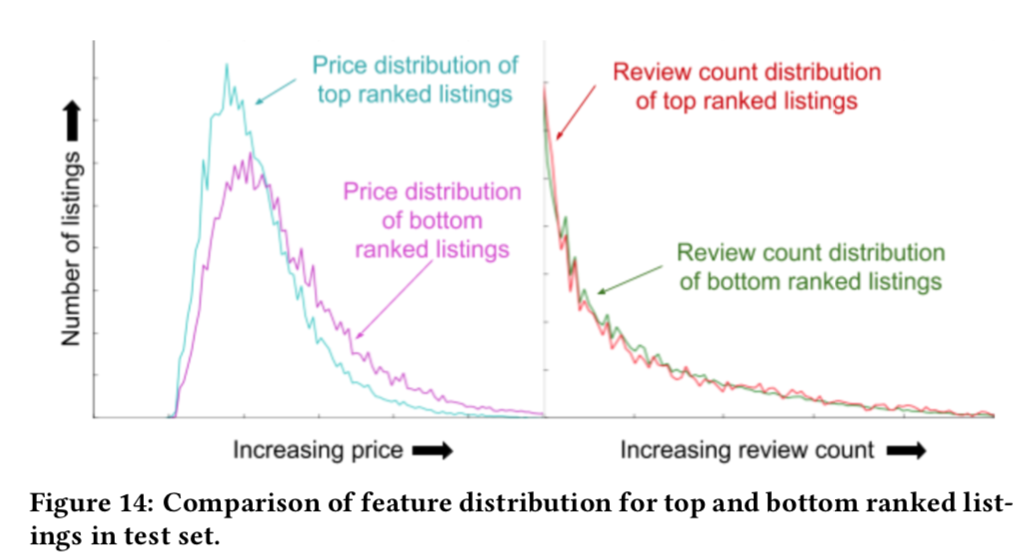
- TopBot Analysis 作者自己开发的一个工具, top-bottom analyzer。对于一个query,将listing排序,分析某一个特征在TOP listing的分布和Bottom的分布,分布上如果有明显差异,则说明模型对这个特征比较敏感。图14就是一个例子,说明模型对price比较敏感,对评论数量不敏感,说明模型对评论数据的拟合不符合预期,说明在评论数据使用上需要进一步研究。
参考
- https://developers.google.com/machine-learning/guides/rules-of-ml/
- Daria Sorokina and Erick Cantu-Paz. 2016. Amazon Search: The Joy of Rank- ing Products. In Proceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’16). 459–460.
- Peng Ye, Julian Qian, Jieying Chen, Chen-Hung Wu, Yitong Zhou, Spencer De Mars, Frank Yang, and Li Zhang. 2018. Customized Regression Model for Airbnb Dynamic Pricing. In Proceedings of the 24th ACM SIGKDD Conference on Knowl- edge Discovery and Data Mining.
- Sebastian Ruder. 2017. An Overview of Multi-Task Learning in Deep Neural Networks. CoRR abs/1706.05098 (2017). arXiv:1706.05098 http://arxiv.org/abs/1706.05098
- Xing Yi, Liangjie Hong, Erheng Zhong, Nanthan Nan Liu, and Suju Rajan. 2014. Beyond Clicks: Dwell Time for Personalization. In Proceedings of the 8th ACM Conference on Recommender Systems (RecSys ’14). ACM, New York, NY, USA,
- Chiyuan Zhang, Samy Bengio, Moritz Hardt, Benjamin Recht, and Oriol Vinyals. 2017.Understandingdeeplearningrequiresrethinkinggeneralization. https: //arxiv.org/abs/1611.03530