Table of Contents
腾讯lookalike
- 论文:Real-time Attention Based Look-alike Model for Recommender System
- 传统的推荐依赖item的特征,会导致曝光多的item预估CTR偏高,而曝光少的item预估CTR偏低,带来长尾曝光不足的问题。
- lookalike 是基于用户做相似扩展,可以有效解决item特征不足的问题,因为这种方法只依赖用户。本质上是userCF,比较适合新的item推荐。
- 几个特性
- 实时性
- Effective
- Performance
- 相关论文:QiangMa,MusenWen,ZhenXia,andDatongChen.2016.ASub-linear,Massive- scale Look-alike Audience Extension System A Massive-scale Look-alike Au- dience Extension. In Workshop on Big Data, Streams and Heterogeneous Source Mining: Algorithms, Systems, Programming Models and Applications. 51–67.
- 主要方法
- 相似度方法,利用user embedding,计算候选用户与种子用户的相似度
- 回归方法(实际上是分类的方法),将种子用户做正样本,而将非种子用户做负样本,建立模型
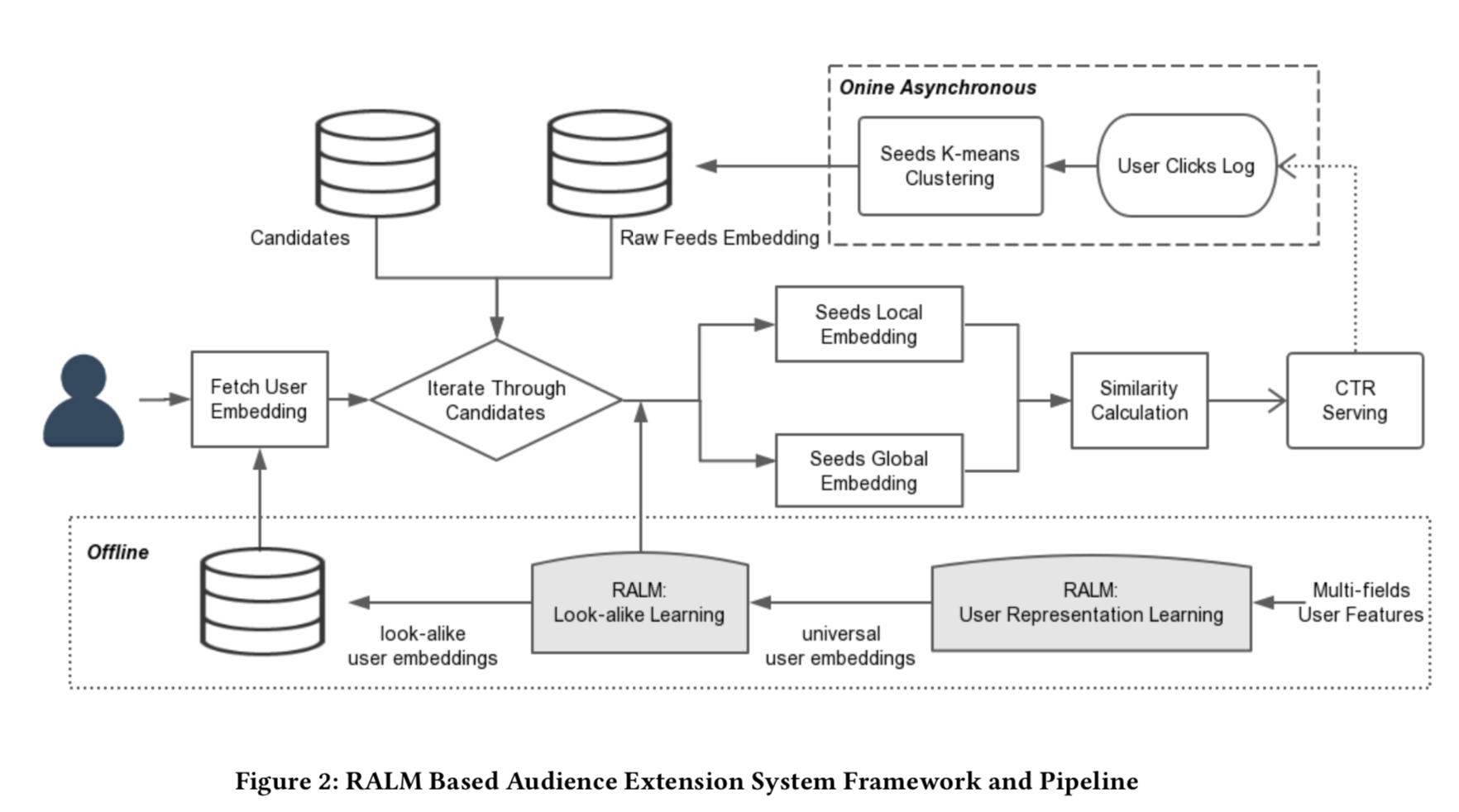
- 离线训练流程
- 用户表示学习
- 特征:用户全域数据
- 样本:用户阅读文章、播放音乐、播放视频、购物 etc
- 输出:用户embedding向量
- look-alike学习
- 特征:前一阶段的用户embedding向量
- 样本:受众扩展的样本,种子用户和非种子用户?
- 输出:一个模型,可以预测种子用户集合的表达
- 用户表示学习
- 在线异步处理流程
- 实时更新种子用户的embedding数据库?
- 应用K-means聚类将用户聚成K类
- 用户反馈监控:只选取最近点击的300W用户作为种子用户?
- 种子聚类:每5分钟运行K-means聚类,聚类中心的embedding向量保存到数据库中
- 在线服务
- 拉取当前用户的embedding向量 $(E_u)$
- 拉取每一个候选集合的种子用户embedding向量,输入look-alike模型,算出两个向量:全局embedding $(E_{global})$和局部embedding向量 $(E_{local})$
- 计算相似度
$$
score_{u, s} = \alpha \cdot cosine(E_u, E_{global}) + \beta \cdot cosine(E_u, E_{local})
$$ - 相似度将作为ctr模型的权重因子????
模型
- 特征
- 离散
- 单值:gender、location
- 多值:兴趣keyword
- 连续
- 每一类特征作为一个field
- 连续特征和预训练的低维向量特征,归一化到(0,1)
- 离散
- 用户表示学习
- 采样
- 任务包括:文章阅读、音乐播放、视频播放etc
- 负样本通过负采样得到
- 限制每个用户正样本数目最大为50
- 正负比例1:10
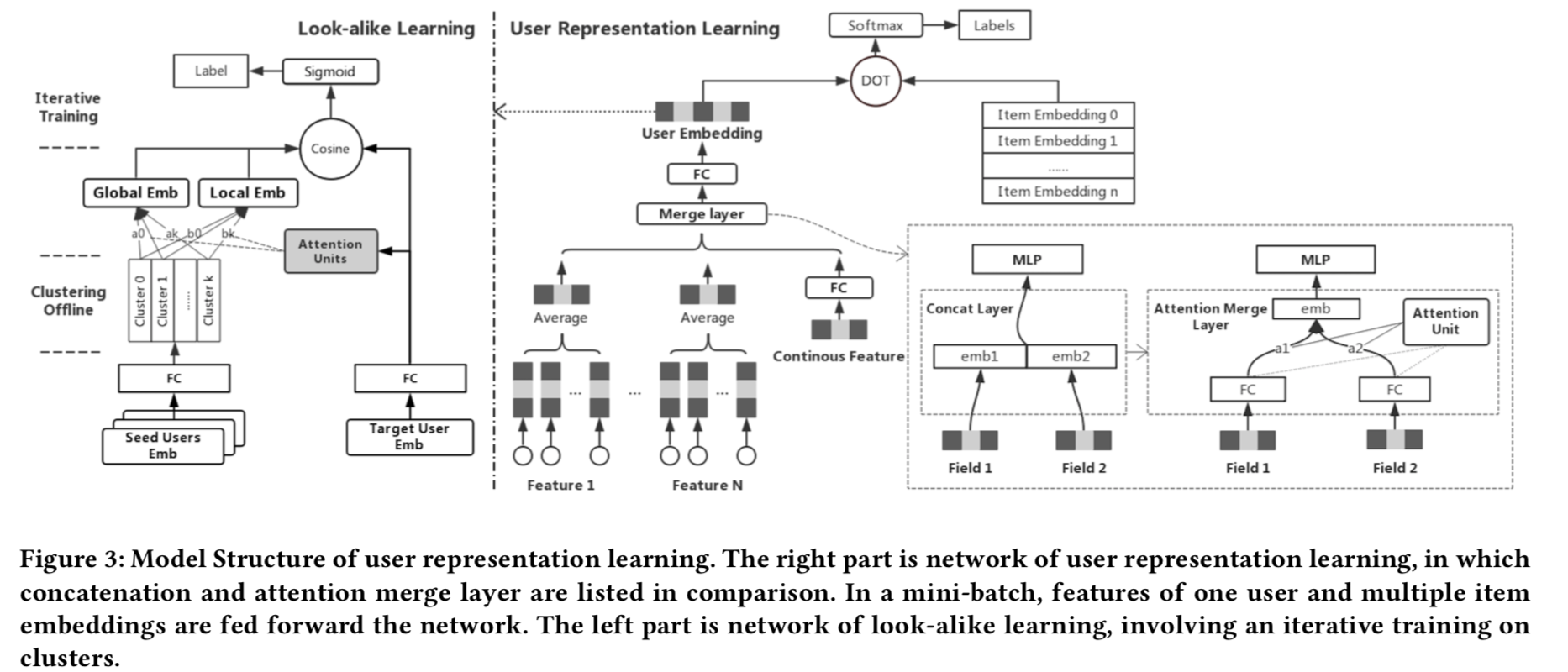
- 模型结构
- 基本借鉴YouTubeDNN 用户模块,每个field单独embedding+avg pooling;然后多个field间concat
- 最后一层向量就可以作为用户的表示向量
- attention merge层
- 原因:多个field特征concat到一起之后,强相关的field会过拟合,而弱相关的field会欠拟合。(这个是如何判断的??)
- n个field,学n个权重,权重通过一个隐层的神经网络学到,输入是concat的特性向量!!
- 采样
- look-alike模型学习
- 模型结构:双塔=seed塔 + target塔。seed塔输入是n个种子用户向量;target塔输入是该用户的向量,通过transform矩阵投影到h维的隐空间
- transform矩阵,将用户embedding向量空间转换到h维隐空间
- local attention,将n个seed用户向量做pooling。$(E_s)$是n个种子用户向量构成的矩阵,$(E_u)$是target用户向量,这里的用户向量都是h维,经过转换矩阵之后。$(W_l \in R^{l\times l})$是核。
$$
a = softmax(tanh(E_s^T W_l E_u))
$$
因为seed用户较多,多达百万量级,为了加速计算,先对seed用户聚类成k各类(k在100量级),然后只用这k个类中心来代表这些种子用户集合。 - global attention,利用self-attention将n个种子用户向量Pooling到一个向量,也是利用k个聚类来做的?
$$
a = softmax(E_s^T tanh( W_g E_s))
$$ - 迭代训练,每个epoch训练完了之后,重新聚一下类
- 损失函数:交叉熵,label怎么来的?从下文来看,是用户对item的点击,seed用户来自item
试验
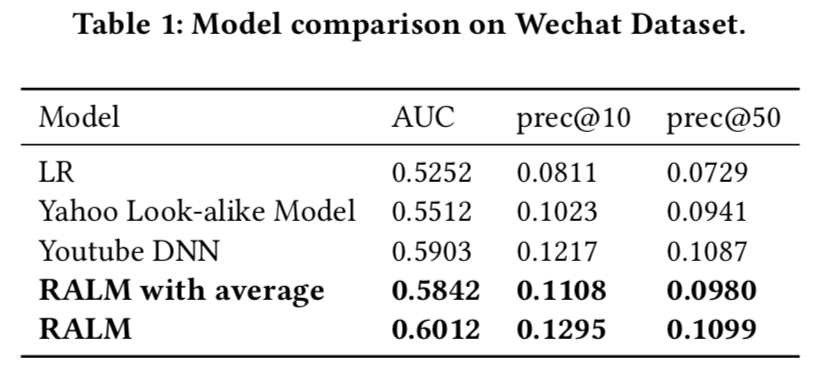
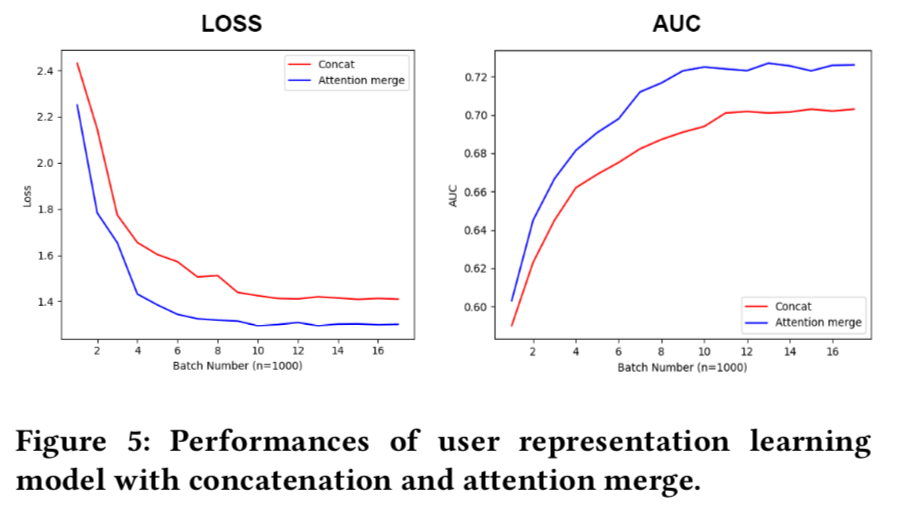
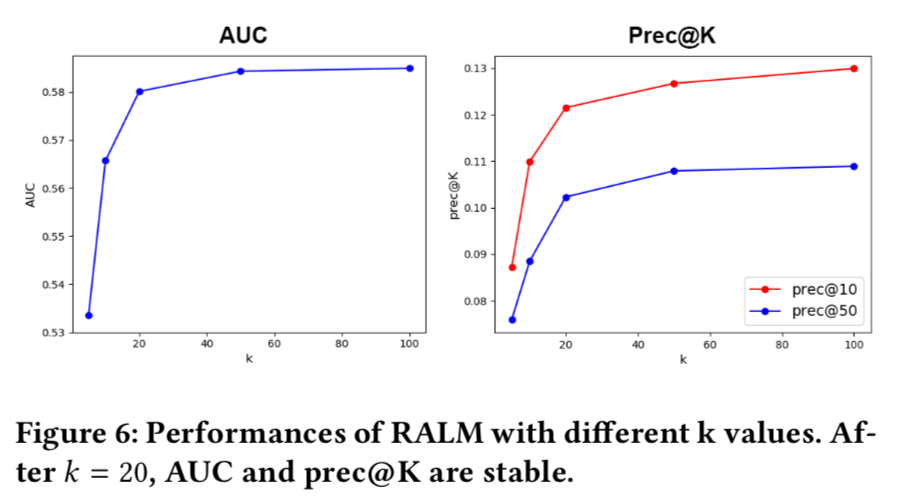
- 数据,{uid, item_id, is_click},种子用户通过item_id来关联得到
- 模型:LR,Yahoo lookalike,YouTube DNN,RALM with average 用average pooling
- 评估指标:AUC,precision@K(推荐的TOP K中有多少比例是用户实际点击的)
- attention的作用参考第二个效果图
- 聚类中心的个数K的影响,当K超过20之后就不敏感了。在线模型设置为20
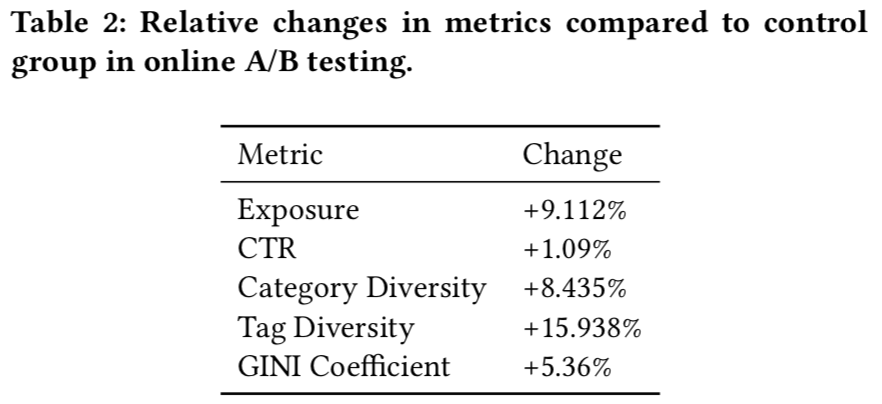
- 在线试验结果:周期 2018-11 to 2018-12
- 曝光量
- 点击率
- 内容&标签的多样性:用户一天内阅读的内容的列表、标签的数目
- Gini系数:减轻Mathew Effect(马太效应),所有被点击item的点击数量分布。这个系数越大表示越多的长尾内容被消费?(怎么和基尼系数的定义相反?)